1. Overview
Databases have played a fundamental role in software development in recent decades. Their main purpose is to describe a real-world model for which we want to save data for different purposes. Therefore, they are crucial to data modeling and durable and consistent storage.
In this tutorial, we’ll look at relational databases, their core concepts, main advantages, and comparisons with other database types.
2. A Short History
Edgar F. Codd conceptualized relational databases in the 1970s by issuing the paper A Relational Model of Data for Large Shared Data Banks. IBM used this work to create System R, a prototype of a relational database featuring the first SQL.
The relational model replaced the hierarchical model used in IBM’s first commercial database. In contrast, a relational database introduces the theory of tables, relations, data normalization, and the definition of a Schema.
In 1979, Oracle released the first relational database management system (RDBMS) using SQL.
Although NoSql (non-relational databases) has grown to offer better performance in recent years, RDBMS is still popular in application development and is widely used by many software applications.
Let’s look at some basic concepts of a relational database and the logic of representing the data.
3. Table, Columns and Rows
Let’s look at the main actors in the relational model:
- Tables are data collection representing the entities of our particular data model. They consist of columns and rows. A table commonly has a unique identifier, which we can call an id.
- Columns that describe the attributes of an entity.
- Rows that are specific entries or records for an entity.
Let’s say we want to represent a bookshop where our main entity is a Book with a title and an author. We can picture this by showing a Book both as an entity and a table:
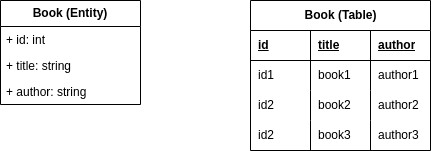
Describing the real world’s entities is difficult; tables can have many attributes and complex relations. Let’s see how we can use normalization forms to create a model of our data.
4. Normalization
In relation databases, we use normalization to shape relations and ensure data integrity. There are many types of normalization. Let’s see how we can apply it in our book example.
4.1. Normalization Example
For instance, let’s say a book has more than one author. In that case, we should rethink our table as follows:
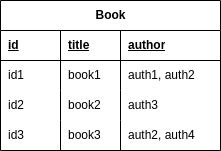
The first normalization form is to avoid duplication and redundancy of data. Let’s see how we can optimize the model:
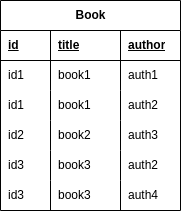
Nonetheless, we are now repeating some information. For example, the books with id1 and id3 now have two entries.
We can further optimize by using the next normalization steps and logically separating the book and author entities:
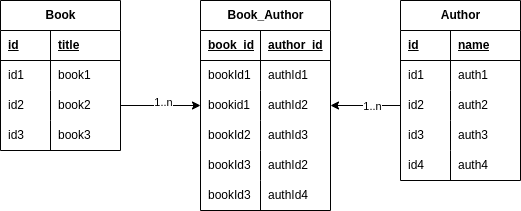
In this case, we create a many-to-many relationship between the Book and the Author using an intermediate table. We looked at a simple example to demonstrate how normalization works. Nonetheless, other possible normalization forms could exist given a model’s cardinality.
We can use tools to design a relational model. For example, we might consider UML.
4.2. Benefit of Normalization
Let’s see the main benefit of applying normalization:
- Minimized Data Redundancy: By organizing data into separate tables and eliminating redundancy, we significantly reduce data duplication and the risk of anomalies during data operations.
- Improve Data Integrity and Consistency: By structuring data logically, we prevent insertion, update, and deletion anomalies, ensuring consistent and accurate data operations.
- Enhanced Query Performance: Given a clear schema and relations, a database engine has efficient data retrieval strategies using access plans.
Normalization is the first step to properly define a database schema, its relations, and the constraints we want to apply to our data.
5. Keys and Constraints
As we have seen with normalization, we apply many rules to our model. A database achieves this with keys and constraints to ensure the data’s integrity, accuracy, and reliability.
Let’s look at the most common keys:
- Primary key (PK) describes what attribute uniquely identifies an entity. It can be a single or multiple attribute (composite key). A PK is sometimes a sequence or an incremental value. Tables might also use alternate or super keys to extend the uniqueness of a PK to multiple identifiers.
- Foreign key (FK) describes the relationship between a table and another table. A FK is a column or a set of columns in one table referring to a key or a constraint in another. It establishes a relationship between the two tables, enforcing referential integrity.
Likewise, let’s look at the most common constraints:
- Unique ensures that all values in a column are different
- Not null ensures that a column cannot have null values
- Default assigns a default to a column if it has no specific value during an insert operation
- Index improves the performance of database queries on the specified columns
Notably, a key is a constraint, but a constraint is not necessarily a key. For example, a PK is also a not null and unique constraint. A unique constraint can apply to a column that is not a PK but for which we want unique values (for instance, an email for a user table).
Nonetheless, choosing the appropriate keys and indexing for a table might be crucial to accessing data in constant time and scaling the database when volumes increase.
The data, such as table info and indexes, is usually saved in a tablespace.
6. Transactionality and the ACID Principles
We can access data in an RDBMS using a client that opens and closes transactions while performing CRUD operations. A database can process millions of transactions simultaneously, and multiple transactions could potentially access the same records concurrently.
The ACID principles are a set of properties that ensure a reliable processing of transactions. These properties guarantee data integrity, even in cases of system failures or concurrent access.
ACID Principles
Description
Atomicity
Ensures that a transaction is treated as a single unit, meaning that all of its operations execute successfully or none are. If any part fails, the entire transaction will roll back, leaving the database in its previous state. For example, if a transaction transfers money from one bank account to another, the debit from one account and the credit to the other must succeed. If one part fails, the transaction will abort, and neither account is affected.
Consistency
Ensures that a transaction takes the database from one valid state to another, maintaining its integrity constraints. A transaction will only be committed if it doesn’t violate any rules defined in the database schema. For example, it should reflect the constraints we determine during the normalization process or the table definition.
Isolation
Ensures that concurrent transactions leave the database in the same state as sequential execution. Each transaction is unaware of other transactions executing concurrently, preventing data anomalies. The isolation level is fundamental in handling problems such as reading uncommitted data or acquiring a lock over specific resources.
Durability
It guarantees that once a transaction commits, it will remain so, and the data is permanently saved even in a system failure. If a transaction commits changes to a database, those changes will continue even if the system crashes immediately afterward. Techniques to achieve this include transaction logs and backups.
The Atomicity and Isolation properties are significant for transactionality, making a relational database the best choice for concurrent processing.
We have seen Consistency when defining constraints in our normalization process.
Finally, the Durability part is vital for security and backup in case of system failures.
7. SQL
SQL is a programming language used for managing and manipulating relational databases. It provides a systematic way to create, retrieve, update, and delete data within a database.
It is the way to interact with a database at different levels, for example:
- DDL (Data Definition Language ) uses Create, Drop, or Alter commands to define and manage the structure of database objects such as tables, indexes, and schemas.
- DML (Data Manipulation Language) with Select, Insert, Update, or Delete commands to retrieve and modify data within the database.
For example, let’s look at a more extended bookstore example with DDL to create our tables:
CREATE TABLE author (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(100) NOT NULL,
last_name VARCHAR(100) NOT NULL,
birth_date DATE
);
CREATE TABLE book (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(255) NOT NULL,
isbn VARCHAR(20) UNIQUE,
publication_date DATE
);
CREATE TABLE book_authors (
book_id INT,
author_id INT,
PRIMARY KEY (book_id, author_id),
FOREIGN KEY (book_id) REFERENCES Books(id),
FOREIGN KEY (author_id) REFERENCES Authors(id)
);
We can then insert some sample data into the tables:
INSERT INTO author (id, first_name, last_name, birth_date) VALUES
(1, 'George', 'Orwell', '1903-06-25'),
(2, 'Harper', 'Lee', '1926-04-28'),
(3, 'J.K.', 'Rowling', '1965-07-31'),
(4, 'F. Scott', 'Fitzgerald', '1896-09-24'),
(5, 'Jane', 'Austen', '1775-12-16'),
(6, 'Mark', 'Twain', '1835-11-30');
INSERT INTO book (id, title, isbn, publication_date) VALUES
(1, '1984', '978-0451524935', '1949-06-08'),
(2, 'To Kill a Mockingbird', '978-0061120084', '1960-07-11'),
(3, 'Harry Potter and the Philosopher\'s Stone', '978-0747532699', '1997-06-26'),
(4, 'The Great Gatsby', '978-0743273565', '1925-04-10'),
(5, 'Pride and Prejudice', '978-1503290563', '1813-01-28'),
(6, 'The Adventures of Tom Sawyer', '978-0486400778', '1876-06-01');
INSERT INTO book_authors (book_id, author_id) VALUES
(1, 1),
(2, 2),
(3, 3),
(4, 4),
(5, 5),
(6, 6),
(1, 2),
(4, 1);
Let’s also see a SELECT statement we can use to get the author(s) of a specific book:
SELECT
CONCAT(a.first_name, ' ', a.last_name) AS author_name
FROM
author a
JOIN
book_authors ba ON a.id = ba.author_id
JOIN
book b ON ba.book_id = b.id
WHERE
b.title = 'Some title';
SQL can vary by database type. However, it follows ISO standards and most commands are portable between databases.
Notably, most RDBMSs also have a procedural form of SQL, such as functions or store procedures, which are precompiled blocks of reusable code used to group SQL logic. For example, we can look at PL/SQL for Oracle.
8. Advantages of Relational Databases
Let’s look at some key advantages of a relational database:
Advantages of Relational Databases
Description
Normalization
It reduces redundancy and ensures consistent data by organizing information into related tables. It supports complex queries and joins, making it suitable for intricate data relationship applications.
Data Integrity and Accuracy
Support for constraints like primary keys, foreign keys, and unique constraints to maintain data integrity and accuracy.
Transaction Safety
It is a robust mechanism for handling transactions safely. It ensures that all operations within a transaction are executed as a single unit and preserves the integrity of the database. It provides configurable isolation levels to balance concurrency and data integrity according to specific application requirements.
Security
Fine-grained access control mechanisms, including user roles and permissions, restrict unauthorized access to sensitive data. To protect against data breaches, support data encryption at rest and in transit.
Scalability
Although traditionally challenging and incomparable to a NoSQL database, RD offers vertical and horizontal scalability.
Maturity
A robust ecosystem of tools, plugins, and integrations for managing, visualizing, and analyzing data
RDBMS offers scalability using indexing and table partitioning and fast access to the data with optimized queries. Databases using replicas, such as master-slave installations, are common.
We have authentication, authorization, and integration with external systems for security. We also have data encryption, auditing, backup, and recovery strategies.
9. NoSQL Databases and Relational Databases Limitations
Relational databases have limitations we can understand if we compare them with NoSQL types.
9.1. RDBMS vs. NoSQL Database
NoSQL Databases offer a more flexible approach to data storage, often without a fixed schema, making them more adaptable to changes a data model might have. They can handle unstructured or semi-structured data and optimization for specific types of operations.
They can scale horizontally using shards across distributed systems and for high-volume read and write operations, making them ideal for handling large-scale data efficiently.
Although also available in RDBMS, sharding is more challenging due to the complex table relationships we might have.
However, NoSQL data consistency is less reliable due to more relaxed ACID principles.
9.2. Future of DBMS: NewSQL Databases
NewSQL databases are a modern category of databases that aim to combine the best features of traditional relational databases with the scalability of NoSQL databases.
They are relatively new and may lack the maturity and ecosystem support of established RDBMS or NoSQL solutions.
Nonetheless, they provide NoSQL systems’ scalability and performance benefits while maintaining traditional relational databases’ ACID properties and SQL support.
10. Popular Relational Database Management Systems (RDBMS)
Let’s quickly look at the most common relational databases in use today:
- MySQL is an open-source RDBMS developed by Oracle Corporation. It is one of the most popular databases used worldwide due to its robustness, reliability, and ease of use. We can also look at MariaDB as a MySQL fork.
- PostgreSQL is an open-source RDBMS known for its advanced features and extensibility. It is known for its compliance with SQL standards and great support for complex queries, text search, JSON data type, and geospatial (GIS) data.
- Microsoft SQL Server is a relational database developed by Microsoft and primarily used in enterprise environments.
- Oracle Database is a leading RDBMS known for its high performance and reliability. It is popular in large enterprises and complex applications.
Notably, most cloud providers, such as AWS, Azure, or GCP, offer cloud instances of these databases, such as RDS for MySQL in AWS.
11. Conclusion
In this article, we saw how a relational database works and its main components. It has tables, constraints, relations, normalization forms for data modeling, transactionality, and the ACID principles. We also compared it with the NoSQL database while outlining the main limitations of RDBMS. Finally, we saw how NewSQL databases could combine the best features of SQL and NoSQL databases in the future.