1. Introduction
In this tutorial, we’ll learn the theory behind tokenizers, focusing on their importance, types, and the process of building a tokenizer for a generative pre-trained transformer (GPT) model.
2. Tokenization in Natural Language Processing (NLP)
Tokenization is a fundamental step in natural language processing (NLP), transforming raw text into a format that can be understood and processed by machine learning models. Tokenizers are responsible for breaking down text into tokens, the smallest units of meaning, such as words, subwords, or characters.
Tokenization is essential for several reasons. Firstly, it ensures standardization by converting text into a uniform form, simplifying further processing and analysis. When dealing with natural language, text data can vary widely in structure, format, and presentation. Tokenization addresses this issue by breaking down complex text strings into manageable, standardized tokens, allowing for more straightforward analysis and processing.
Secondly, tokenization aids in handling out-of-vocabulary (OOV) words by breaking them down into subwords or characters, thereby managing words that are not present in the training vocabulary. These OOV words can disrupt the model’s performance, as it might struggle to understand or process them accurately. Tokenization mitigates this problem by using familiar subunits to infer the meaning of the new, composite word.
Lastly, it enhances efficiency by reducing the complexity of the text, making it easier and faster for models to process. Tokenized data allows machine learning models to focus on the essential components of the text, without being bogged down by extraneous details or irregularities. Tokenization facilitates parallel processing, we can distribute smaller tokens across multiple computational units for faster analysis.
3. Byte Pair Encoding (BPE) Tokenization
Byte Pair Encoding (BPE) serves as a widely used subword tokenization technique, especially in GPT models. It iteratively merges the most frequent pairs of bytes (characters) to create new subword units. This merging process continues until the tokenizer reaches a predefined vocabulary size.
In BPE tokenization, the process begins by initializing a vocabulary that includes all characters in the training corpus along with their frequencies. During the pair merging phase, the tokenizer identifies and merges the most frequent pair of adjacent tokens to form a new token:
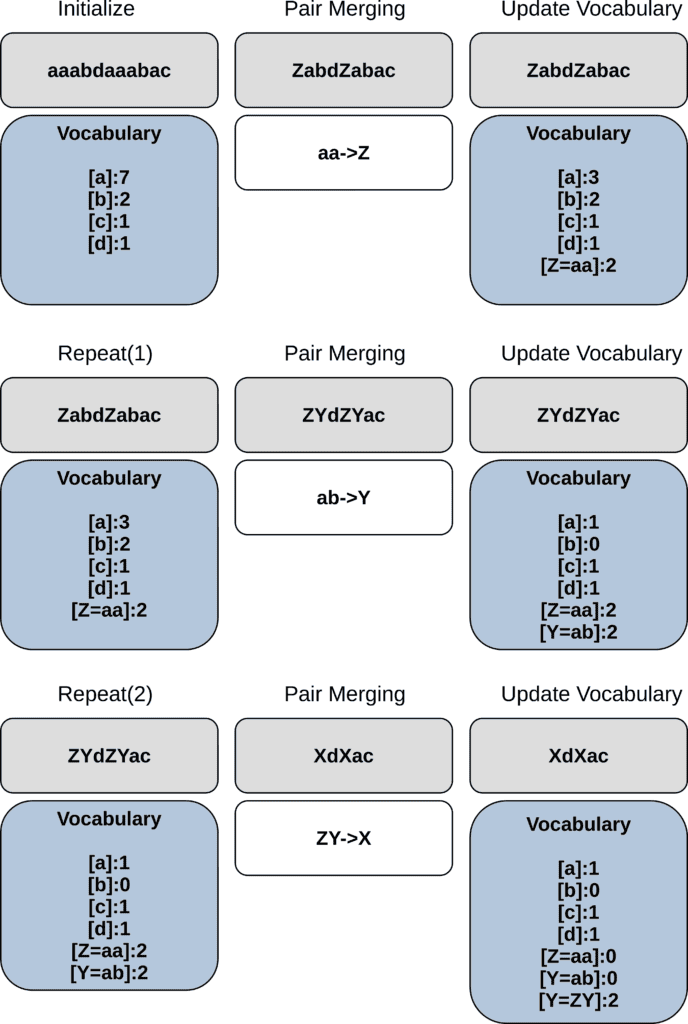
The tokenizer then updates the vocabulary by replacing all occurrences of the merged pair in the text with the new token. This merging process repeats until the tokenizer achieves the desired vocabulary size, resulting in a compact and efficient token representation.
4. Building a GPT Tokenizer
Building a GPT tokenizer involves several key steps, and we’ll walk through each one together.
4.1. Corpus Preparation
Let’s start by gathering a large and diverse text corpus that represents the language and domain we’re interested in. The quality and size of the corpus will significantly impact the tokenizer’s performance, so we want to make sure we include a wide variety of text.
4.2. Data Preprocessing
Next, we need to clean our text data. This involves removing any noise, special characters, and unnecessary spaces. We should standardize the text to ensure consistency in tokenization. This step is crucial, as it ensures that the text is in its best form for the tokenizer to process.
4.3. Training the Tokenizer
Now, we can proceed to train the tokenizer using the Byte Pair Encoding (BPE) algorithm. We’ll iteratively merge frequent pairs of characters or subwords to create a compact and efficient vocabulary. Our goal here is to have tokens that capture the nuances and variations in the language, which will help the GPT model understand and generate text more effectively.
4.4. Evaluating the Tokenizer
After training, we need to evaluate the tokenizer’s performance. We should check how well it handles different types of text, including rare words, compound words, and various linguistic structures. Based on our evaluation, we can adjust the vocabulary size and merging rules to improve the tokenizer’s effectiveness.
4.5. Integration and Usage
Finally, after training and evaluating, we’ll integrate the tokenizer with the GPT model. The tokenizer will convert input text into tokens, which the model will process to generate predictions or outputs. It can also convert the tokens back into human-readable text, ensuring that the output is understandable and relevant.
By following these steps, we’ll be able to build a robust GPT tokenizer that effectively processes and understands our text data, enhancing the overall performance of the GPT model.
5. Conclusion
In this article, we learned that tokenization is a fundamental step in natural language processing (NLP). Byte pair encoding (BPE) is a commonly employed subword tokenization technique in GPT models. Constructing a GPT tokenizer involves several steps: collecting and cleaning a text corpus, followed by the training and evaluation of the tokenizer, and finally, integrating it into the model.