1. 概述
在软件开发中,我们通常会将程序生命周期划分为不同的阶段。其中,编译时(Compile Time) 和 运行时(Runtime) 是两个非常关键的概念。本文将详细解释这两个术语的含义、它们之间的区别,以及它们在开发和调试过程中的实际意义。
2. 软件开发的主要阶段
一个完整的软件开发流程通常包括以下几个阶段:
- 编写源代码
- 编译成中间代码或机器码
- 加载和链接(如有需要)
- 执行程序
下图展示了典型的编译型语言(如 Java、C/C++)的开发流程:
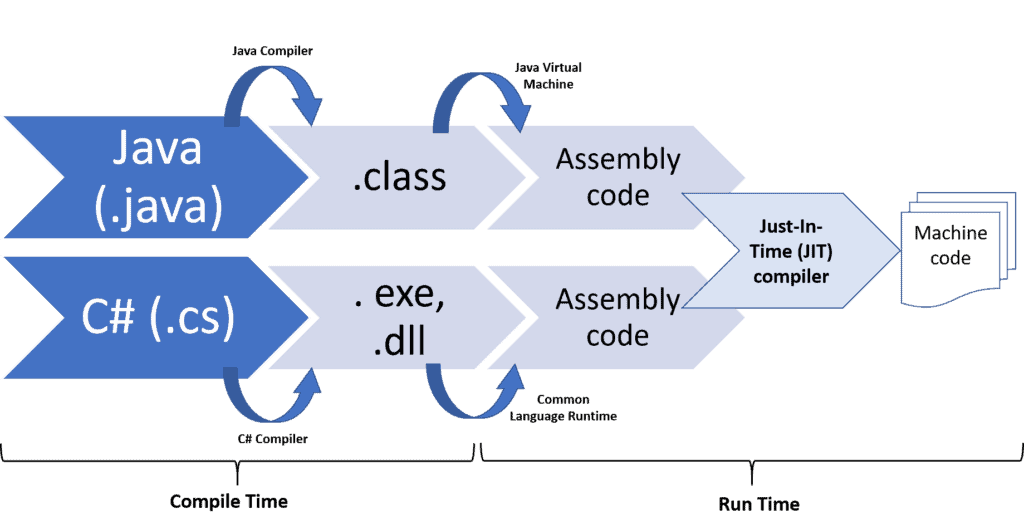
简单来说:
- 编译时(Compile Time):指的是源代码被编译器翻译成目标代码的阶段。
- 运行时(Runtime):指的是程序被加载并实际执行的阶段。
3. 编译时详解
大多数现代语言(如 Java、C++)使用高级语言编写,最终需要被转换为机器能理解的格式。在 Java 中,源文件(.java)会被编译为字节码文件(.class)。
✅ 编译时主要职责:
- 检查语法是否正确
- 进行类型检查(type checking)
- 将源代码翻译为中间代码或目标代码
3.1 输入与输出
| 类型 | 内容说明 |
|---|---|
| 输入 | 源代码、依赖库、接口定义、第三方 jar 包等 |
| 输出 | 成功时输出 .class 文件;失败则输出编译错误信息 |
3.2 编译时错误类型
语法错误(Syntax Error)
比如括号不匹配、缺少分号、关键字拼写错误等。语义错误(Semantic Error)
例如变量未声明、函数参数类型不匹配、类型推断失败等。
⚠️ 踩坑提醒:Java 中泛型擦除导致的编译错误,有时让人摸不着头脑,比如
List<String>和List<Integer>在编译后其实是相同的类型。
4. 运行时详解
当程序被 JVM 或操作系统加载并执行时,就进入了运行时阶段。这个阶段是程序实际“活”起来的时候。
常见运行时错误类型:
- 除以零:
int result = 5 / 0; - 空指针异常:
String s = null; s.length(); - 内存溢出:例如
OutOfMemoryError - 数组越界访问:
int[] arr = new int[3]; arr[5] = 1;
示例代码:
public class RuntimeExample {
public static void main(String[] args) {
int a = 5;
int b = 0;
int result = a / b; // ❌ 运行时错误:ArithmeticException
System.out.println(result);
}
}
这个错误在编译阶段不会被发现,只有在运行时才会抛出异常。
5. 编译时 vs. 运行时:关键区别
| 对比项 | 编译时(Compile Time) | 运行时(Runtime) |
|---|---|---|
| 发生时间 | 源代码翻译成目标代码阶段 | 程序被加载并执行的阶段 |
| 主要任务 | 语法检查、类型检查、生成字节码 | 实际执行指令、内存分配、资源调度等 |
| 错误检测方式 | 编译器在未执行程序时即可发现错误 | 错误只有在执行路径中才会暴露 |
| 错误修复方式 | 修改源码后重新编译 | 需要修改代码并重新部署,有时需重启服务 |
| 影响范围 | 影响构建流程 | 影响用户使用、系统稳定性、性能等 |
6. 小结与建议
理解 编译时 和 运行时 的区别,对于排查问题、优化代码结构、提升开发效率都非常重要。
- ✅ 编译时错误更容易发现和修复,因为它们在构建阶段就被拦截。
- ❌ 运行时错误则可能影响用户体验,甚至导致系统崩溃,必须通过日志、测试、监控等手段来预防。
- ⚠️ 建议:尽可能在编译阶段通过类型系统、静态检查工具(如 ErrorProne、Lombok、Linter)捕捉潜在问题,减少运行时风险。
掌握这两个阶段的本质区别,有助于你写出更健壮、更安全、更易维护的代码。