1. 引言
在本文中,我们将介绍自平衡二叉搜索树(Self-Balancing Binary Search Tree)——一种通过限制树高度来避免普通二叉搜索树(BST)某些缺陷的数据结构。我们还将实现其中一种流行变体:左倾红黑二叉搜索树(Left-Leaning Red-Black BST)。
2. 二叉搜索树(Binary Search Trees)
二叉搜索树(BST) 是一种二叉树结构,其每个节点的值满足:
- 大于等于其左子树中所有节点的值
- 小于等于其右子树中所有节点的值
例如,一个典型的 BST 可能如下图所示:
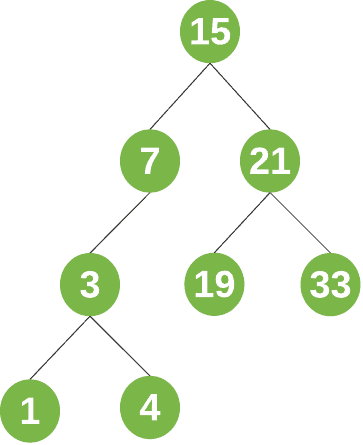
几个关键术语说明:
- 叶子节点(Leaf):没有子节点的节点
- 节点深度(Depth):从根节点到该节点路径上的节点数量(包含该节点)
- 树高度(Height):最深叶子节点的深度
- 平衡树(Balanced Tree):任意节点的左右子树高度差不超过1
如需 BST 基础知识复习,可参考这篇文章
3. BST 常见操作
标准 BST 通常支持以下操作:
- 插入(Insert)
- 删除(Delete)
- 查找(Search)
这些操作的时间复杂度取决于树的高度。最坏情况下,操作可能需要遍历从根节点到最深叶子的所有节点。
当树严重失衡时,例如下图:

查找、插入、删除等操作的时间复杂度会退化为 O(n),效率大打折扣。
如果树是平衡的,那么高度限制在 O(log₂n),每个操作的时间复杂度也维持在 O(log₂n)。这比 O(n) 有显著提升。
4. 自平衡 BST(Self-Balancing BST)
为了保证 BST 的高效性,我们引入自平衡 BST,它通过维护树的最小高度,确保操作始终维持在 O(log₂n) 的最坏时间复杂度。
这类树在每次插入或删除操作后都会检查是否破坏了平衡性,并通过一系列变换将其恢复为合法状态。
常见的自平衡 BST 有:
- 红黑树(Red-Black Tree)
- AVL 树
- 伸展树(Splay Tree)
- B 树
我们接下来将重点介绍左倾红黑树(Left-Leaning Red-Black Tree)
5. 左倾红黑树(Left-Leaning Red-Black BST)
左倾红黑树通过以下三个核心性质维持平衡:
- 树中每条边都有颜色:红色或黑色
- 每个节点最多只能连接一条红色边
- 从根节点到每个空叶子节点的路径中,黑色边的数量相同
当这些性质成立时,树的高度最多为 2 * log₂n,从而保证操作效率。
5.1. 平衡维护机制
在每次插入或删除操作后,我们检查树是否违反上述性质,若违反则通过以下三种变换恢复平衡:
- 左旋(Left Rotation)
- 右旋(Right Rotation)
- 颜色翻转(Color Flip)
5.2. 左旋(Left Rotation)
左旋用于将右向红色边调整为左向。过程如下图所示:
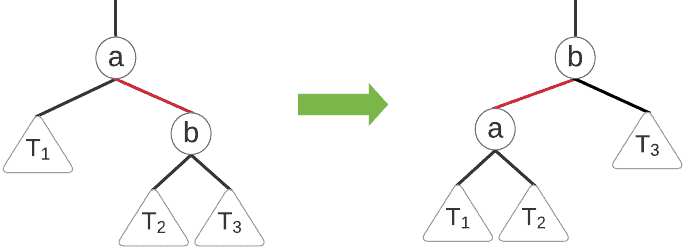
Java 伪代码如下:
algorithm LEFT_ROTATE(node):
// INPUT
// node = the node to rotate around
// OUTPUT
// the tree after performing a left rotation on the given node
x <- node.right
node.right <- x.left
x.left <- node
x.color <- node.color
node.color <- RED
return x
5.3. 右旋(Right Rotation)
右旋是左旋的镜像操作,用于将左向红色边调整为右向。图示如下:
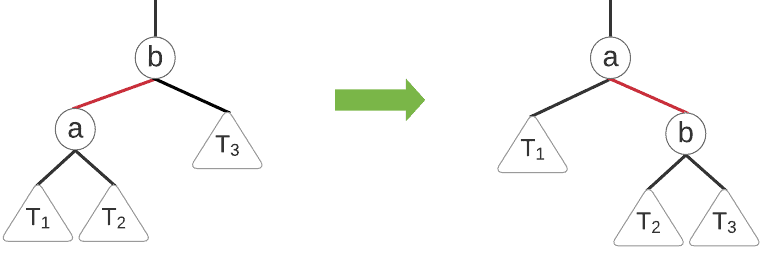
伪代码如下:
algorithm RIGHT_ROTATE(node):
// INPUT
// node = the node to rotate around
// OUTPUT
// the tree after performing a right rotation on the given node
x <- node.left
node.left <- x.right
x.right <- node
x.color <- node.color
node.color <- RED
return x
5.4. 颜色翻转(Color Flip)
当某个节点同时连接两条红色边时,我们执行颜色翻转操作,将其子节点设为黑色,自己设为红色。这样局部结构就合法了。
图示如下:

伪代码如下:
algorithm COLOR_FLIP(node):
// INPUT
// node = the node to perform a color flip on
// OUTPUT
// the node after swapping the colors of its children and itself
node.color <- RED
node.left.color <- BLACK
node.right.color <- BLACK
5.5. 判断节点是否为红色(Is Red)
我们还需要一个辅助函数判断节点是否为红色:
algorithm IS_RED(node):
// INPUT
// node = the node to check color of
// OUTPUT
// true if the node is red, false otherwise
if node.color = RED or node = null
return true
else:
return false
5.6. 插入操作(Insertion)
红黑树的插入操作与普通 BST 类似,只是插入后需要通过旋转和颜色翻转恢复平衡。
伪代码如下:
algorithm INSERT(value, node):
// INPUT
// value = the value to insert
// node = the current node in the tree
// OUTPUT
// the node after insertion, ensuring the red-black tree properties
if node = null:
return new node(value, RED)
else:
if value <= node.value:
node.left <- INSERT(node.left, value)
else if value > node.value:
node.right <- INSERT(node.right, value)
if IS_RED(node.right) and not IS_RED(node.left):
node <- LEFT_ROTATE(node)
if IS_RED(node.left) and not IS_RED(node.left.left):
node <- RIGHT_ROTATE(node)
if IS_RED(node.left) and not IS_RED(node.right):
COLOR_FLIP(node)
return node
5.7. 操作复杂度分析
当红黑树性质成立时,其高度不超过 2log₂n。每次旋转操作仅需常数时间。
因此,插入、删除和查找操作的最坏时间复杂度均为 O(log₂n)。平均和最优情况也保持在 O(log₂n)。
6. 总结
本文我们介绍了如何通过实现自平衡机制显著提升二叉搜索树的最坏情况性能。
我们重点讲解了左倾红黑树的实现原理,以及通过旋转和颜色翻转维护树结构平衡的技巧。
通过这几步变换,我们就能将一个普通的 BST 变成一个高效的自平衡 BST。这说明,算法设计中巧妙的变换机制,往往能带来巨大的性能提升。