1. Overview
Having vector representations of words helps to analyze the semantics of textual contents better. For some applications, such as part of speech tagging, we can use individual word representations. For others, such as topic modeling and sentiment analysis, we need to get the representation of the entire sentence. There are various methods we can use for this purpose.
In this tutorial, we’ll go over some of the most well-known ones. One group of these methods is based on the individual tokens’ representations (simple averaging, weighted averaging, and DAN). In contrast, the other group (Doc2vec, SentenceBERT, Universal Sentence Encoder, and BERT embeddings) can directly compute the sentence embeddings.
2. Simple Averaging
The simplest way to get the sentence representation from the individual word’s representations is by taking their average. While the most significant advantage of this method is its simplicity, it might not be the best option. One of the problems is that it ignores the order of the words in the sentences. Essentially, it becomes similar to a bag-of-words model. As such, it may work in some cases but fail in others.
Another problem is that all words are given the same weight. In some applications, such as sentiment analysis, most words don’t carry a sentiment, and the sentiment of the sentence is hidden in just a few words. So in the case of sentiment analysis, this could result in either a misleading or weakened representation.
The third issue is information loss. This can happen when there’s a frequently used word in the sentence. Averaging over the words can result in similar representations for sentences that contain frequently used words that don’t usually express sentiments.
3. Weighted Averaging
One way to fix some of the problems with the simple averaging method is to weigh the words. The weighting can happen in different ways. A frequently utilized option, especially in document similarity, is Term Frequency – Inverse Document Frequency (TF-IDF):
![[ W_{ij} = TF_{ij} \times log \frac{N}{DF_{i}}]](/wp-content/ql-cache/quicklatex.com-99084757eb58c381a24bffa020df5a60_l3.svg "Rendered by QuickLaTeX.com")
Here,  is the number of times the term
is the number of times the term  occurs in document
occurs in document  ,
,  is the number of documents containing the term , and
is the number of documents containing the term , and  is the total number of documents.
is the total number of documents.
In our case, we can consider each sentence a document. A word that occurs in most documents won’t be that informative. Therefore, its TF-IDF score shouldn’t be that high. While this method solves the problems of simple averaging to some extent, it can still suffer from not taking order into account. In addition, similar to simple averaging, it doesn’t capture the dependence between words and ignores the semantic information.
4. Deep Averaging Network (DAN)
Deep averaging network initially averages over the individual words, similar to the simple averaging method. Then it applies a multi-layer feed-forward neural network to the result. The following figure shows the architecture of DAN:
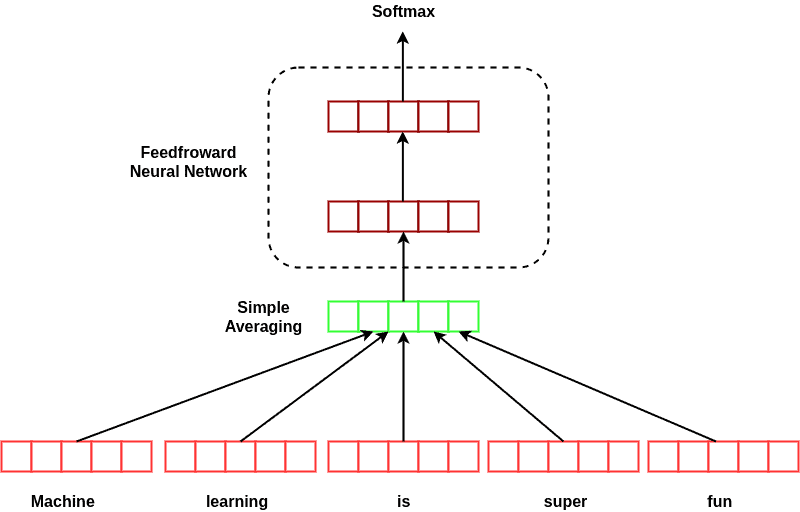
In this figure, we illustrated two layers for the feed-forward network; however, it can be deeper than that. The deeper the model, the better the network will be able to extract subtleties hidden in the sentence.
Although this model is still ignorant about the syntax and word order in the sentences, it can outperform other bag-of-words models. Furthermore, despite its simplicity and lightness in contrast with syntactically-aware models, such as recursive neural networks, deep averaging networks perform comparably.
5. Paragraph Vector (Doc2vec)
This model is based on, and greatly inspired by, the word2vec algorithm. In fact, it’s only slightly different from word2vec. To compute the paragraph vector, we train the model to predict the next word by using some of the previous words and the previous paragraph. By doing so, we average or concatenate the presentations of individual words in the sequence:
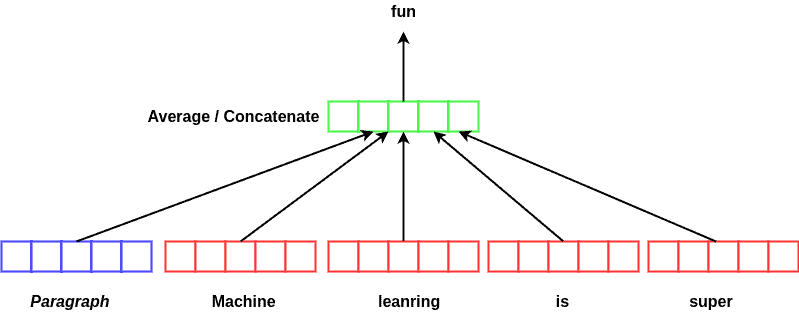
Training the model this way will force the paragraph vector to store the representation of the paragraphs. Here, a paragraph can be any sequence of various lengths. We can consider the paragraph vector as a type of memory that remembers the context of the word we want to predict. As a result, we can predict a more related word for that position.
Similar to word2vec, which takes order and syntax into consideration, paragraph vectors learn the syntax of the sentence. Therefore, they overcome the problems that impact bag-of-words models. In addition, since doc2vec is an unsupervised model, it can be advantageous when we don’t have a large labeled dataset but instead many unlabelled examples.
6. SentenceBERT
SentenceBERT is another well-known architecture that we can use for obtaining sentence representations. To train it, we input the sentences into two parallel BERT models and use pooling to extract the sentence representations from the result. The pooling can be the representation for the  token, the mean of the entire sequence tokens, or the max-over-time of the output vectors:
token, the mean of the entire sequence tokens, or the max-over-time of the output vectors:
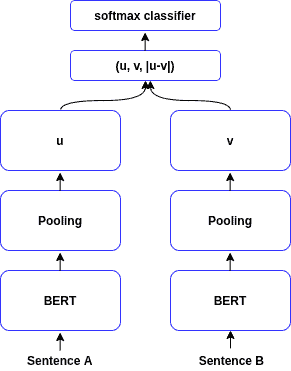
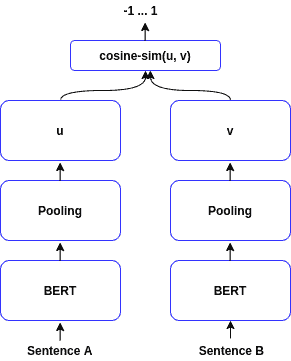
We can train SentenceBERT with two different objectives. One is classification (left diagram above), and the other is a regression (right diagram above). The SentenceBERT architecture makes the computation of some tasks much faster, such as finding similar sentences in a corpus.
If we want to find the most similar sentence pairs in a corpus using BERT, we have to insert all the sentence pairs to see which ones are more similar. This can take a considerable amount of time (tens of hours). However, SentenceBERT can do the same task in a couple of seconds.
7. Universal Sentence Encoder
From the name of this model, we can infer that it’s a model for various tasks, such as sentiment analysis and sentence similarity. It uses the encoder part of the Transformer model, and learns a general-purpose embedding that can be used to perform a variety of downstream tasks:

Universal Sentence Encoder (USE) works better than bag-of-words and the deep averaging network. However, it’s computationally more expensive. While the former models operate with a linear order, USE functions in a quadratic order. It’s also worth noting that USE compared to SentenceBERT has an inferior performance.
8. BERT Embedding
In addition to the methods explained above, we can also use the BERT model itself to extract the word embeddings, as well as the representation of a sentence. This is possible due to the particular structure of the input sequence that we want BERT to process. We can see this in the following figure:
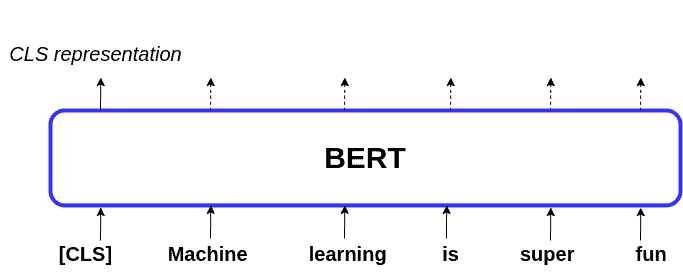
As we can see, in addition to the sequence words, there’s also a token called . This is called the class token, which we use to classify the sentence. As such, we can consider the embeddings stored in this token as the representation of the entire sentence. We can also use the average of the representations of the words in the sequence as the sentence’s representation.
9. Conclusion
In this article, we discussed vector representations of sentences using token representations. Then we learned about some of the existing methods that we can use to get the sentence representations.