1. 词向量简介
在自然语言处理(NLP)中,我们希望计算机能像人类一样理解文本。但要实现这一点,首先需要让计算机将文字转化为它能处理和理解的形式。
本文将介绍如何通过 词向量(Word Embeddings) 实现这一目标。我们会讲解什么是词向量,以及它为什么重要。同时,还会介绍两种主流的词向量生成方法:CBOW 和 Skip-Gram。
2. 什么是词向量?
词向量是词语的数值化表示方式,类似于 RGB 表示颜色的方式。
最基础的表示方法是 One-Hot 编码。它将每个词用一个向量表示,向量长度等于词汇表中词的数量。所有值为 0,只有一个位置为 1,代表该词。
举个例子:
句子:"the pink horse is eating"
该句有 5 个词,因此每个词用长度为 5 的向量表示:
$$ \text{the} \rightarrow \begin{bmatrix} 1 \ 0 \ 0 \ 0 \ 0 \end{bmatrix}, \quad \text{pink} \rightarrow \begin{bmatrix} 0 \ 1 \ 0 \ 0 \ 0 \end{bmatrix}, \quad \text{horse} \rightarrow \begin{bmatrix} 0 \ 0 \ 1 \ 0 \ 0 \end{bmatrix}, \quad \text{is} \rightarrow \begin{bmatrix} 0 \ 0 \ 0 \ 1 \ 0 \end{bmatrix}, \quad \text{eating} \rightarrow \begin{bmatrix} 0 \ 0 \ 0 \ 0 \ 1 \end{bmatrix} $$
这种方式的问题在于:
✅ 词汇表越大,向量维度越高,容易导致 维度灾难(Curse of Dimensionality)
✅ 词汇增减会影响所有词的表示
❌ 最致命的是:不包含语义信息,词之间没有任何关系表达
为了解决这个问题,我们需要一种能捕捉语义和句法信息的词向量表示方式。Word2Vec 就是其中一种广泛应用的技术。
Word2Vec 中的两个核心算法是:
- CBOW(Continuous Bag of Words)
- Skip-Gram
它们都基于上下文(context)来学习词向量。简单来说,如果一组词总是出现在相同的上下文中,它们的词向量会趋于接近。
上下文窗口(Context Window)示例:
假设窗口大小为 2,对于句子:
"the pink horse is eating"
我们构造的词对如下:
| 当前词 | 上下文词对 |
|---|---|
| the | (the, pink), (the, horse) |
| pink | (pink, the), (pink, horse), (pink, is) |
| horse | (horse, the), (horse, pink), (horse, is), (horse, eating) |
| is | (is, pink), (is, horse), (is, eating) |
| eating | (eating, horse), (eating, is) |
3. Skip-Gram 模型
Skip-Gram 的核心思想是:给定一个目标词,预测其上下文词。
以 "horse" 为例,我们希望模型能通过输入 "horse",预测出 "the", "pink", "is", "eating"。
具体流程如下:
- 使用 One-Hot 编码表示输入词(如 "horse")
- 输入神经网络模型
- 输出层预测上下文词的概率分布
模型结构如下图所示:
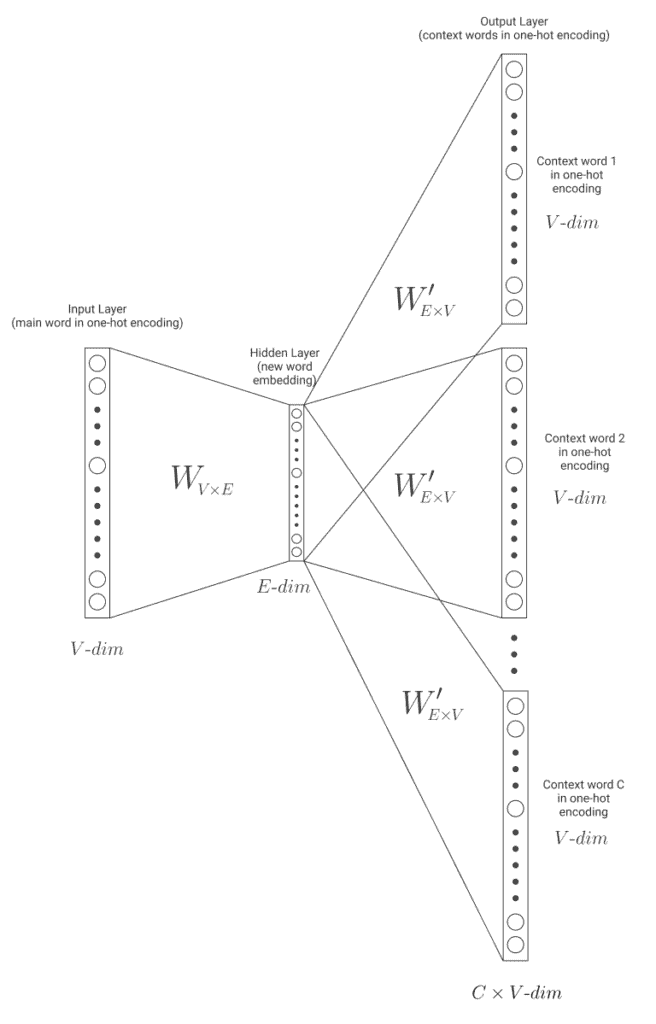
模型参数说明:
- 输入层大小:
1xV(V 是词汇表大小) - 隐藏层大小:
1xE(E 是词向量维度) - 输出层大小:
1xV
模型训练完成后,权重矩阵 W(大小 VxE)即可用于生成词向量。如果训练得当,相似词的向量在空间中会更接近。
4. CBOW 模型
CBOW 的核心思想与 Skip-Gram 相反:给定上下文词,预测目标词。
继续以 "horse" 为例,输入是上下文词 "the", "pink", "is", "eating",输出是目标词 "horse"。
模型结构如下图所示:
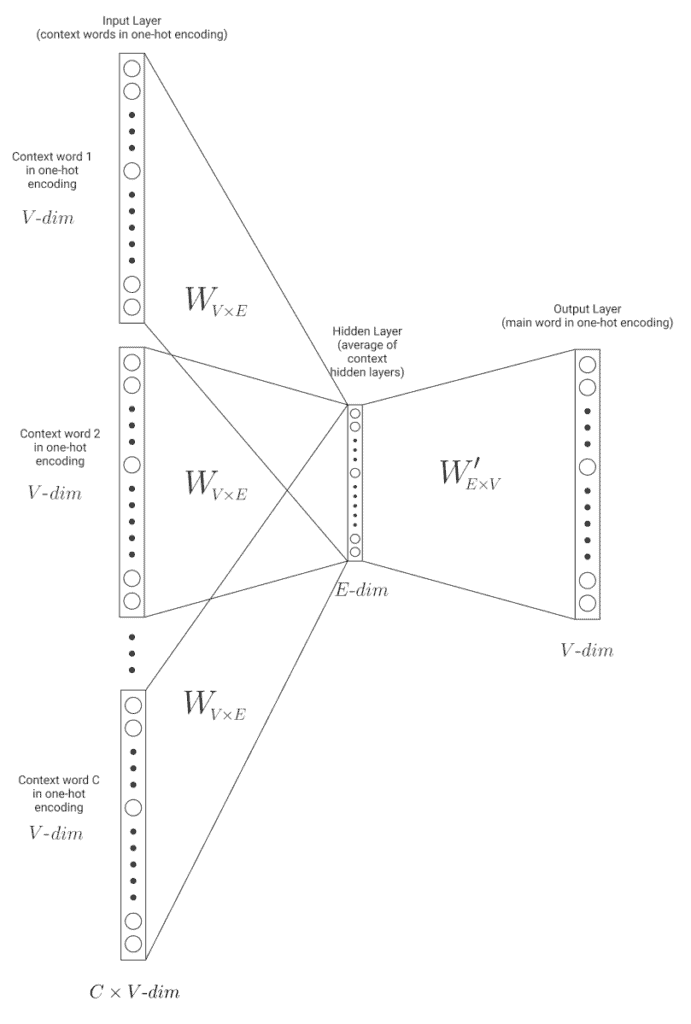
具体流程如下:
- 输入多个上下文词的 One-Hot 向量
- 分别通过权重矩阵
W得到隐藏层表示 - 对这些隐藏层进行平均
- 输入输出层,预测目标词
训练完成后,同样使用权重矩阵 W 生成词向量。
5. CBOW vs Skip-Gram:如何选择?
根据 Mikolov 等人在 Word2Vec 原始论文 中的结论:
| 比较维度 | CBOW | Skip-Gram |
|---|---|---|
| 训练速度 | ✅ 更快 | ❌ 更慢 |
| 小数据集表现 | ❌ 一般 | ✅ 更好 |
| 稀有词表现 | ❌ 一般 | ✅ 更好 |
| 常见词表现 | ✅ 更好 | ❌ 一般 |
选择建议:
✅ 优先选 Skip-Gram:如果你的数据量小,或者需要较好表示稀有词
✅ 优先选 CBOW:如果你追求训练效率,且稀有词不是关键因素
6. 小结
本文介绍了词向量的基本概念和作用,以及两种主流的词向量生成方法:CBOW 和 Skip-Gram。
总结如下:
- One-Hot 编码虽然简单,但无法表达语义信息
- Word2Vec 通过上下文学习词向量,能有效捕捉语义和句法信息
- Skip-Gram 更适合小数据集和稀有词建模
- CBOW 更快,适合大数据集和常见词建模
选择哪种模型,取决于你的具体任务需求。理解它们的差异,有助于你在实际项目中做出更合适的技术选型。