1. Overview
In the dynamic realm of modern data management, the need for scalable and performant databases has become paramount. Further, organizations and applications generate vast volumes of data daily, necessitating database solutions that can seamlessly expand to accommodate this exponential growth. Thus, sharding become a popular strategy for organizing modern databases.
In this tutorial, we’ll discuss the fundamentals of sharding and details of how it works. Moreover, we’ll elaborate on the benefits and drawbacks and compare sharding with traditional database scaling. Lastly, we’ll debate when and how to consider if sharding is the right tool for our software.
2. Sharding Process
Sharding, at its core, is a horizontal partitioning technique. It involves breaking down a large database into smaller, more manageable pieces called shards. Thus, each shard operates as an independent database, consistent with its own schema, indexes, and data subsets. Furthermore, sharding introduces the concept of data distribution, where predefined criteria assign specific data subsets to individual shards. We can see an example of sharding a large database into smaller ones below:

Firstly, the process starts by selecting a shard key, a field, or an attribute within the dataset that determines how data distributes across shards. Shard key plays a pivotal role in shard assignment, and its selection requires careful consideration.
Secondly, sharding employs distinct methods for distributing data across shards. Two primary methods include range-based sharding, which partitions data based on predefined ranges, and hash-based sharding, which distributes data using a hashing algorithm. Understanding these methods is vital in shaping the sharding strategy.
Further, once the shard key and distribution method are defined, data is distributed across shards based on these criteria. This distribution process ensures that each shard contains a portion of the dataset, making it responsible for managing specific data subsets. For example, shards can be organized in vertical or horizontal ways:
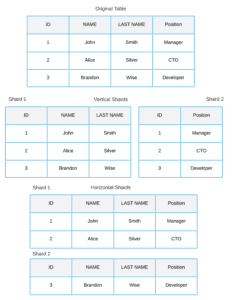
In the image, we can see horizontal and vertical approaches. At the top, we can see data distributed vertically divided by columns.
The bottom portion illustrates horizontal sharding, showing multiple identical database servers, each referred to as a “shard.”
Finally, we can scale a shared database if needed. The brief process of scaling a sharded database consists of:
- Evaluate Needs: Assess the database’s growth and performance demands
- Choose Scaling Method: Decide between vertical scaling or horizontal scaling
- Implement Load Balancing: Distribute traffic evenly across servers to prevent overload
- Optimize Queries: Review and optimize database queries to reduce server load
- Database Replication: Use read replicas for improved performance and failover
- Caching: Implement caching mechanisms to reduce the need for database queries
- Database Indexing: Efficiently use and maintain indexes to improve query performance
- Archiving and Pruning: Regularly remove outdated data to manage database size
- Cloud Solutions: Consider managed database services from cloud providers for scalability
- Regular Monitoring: Continuously monitor performance and adjust strategies as needed
3. Sharding vs. Traditional Scaling
In this section, we’ll compare sharding with traditional scaling and see how those techniques can be combined.
3.1. Scalability
Sharding is unparalleled when it comes to scalability. Thus, it excels at distributing the data load across multiple shards, allowing for nearly linear scalability as new shards are added. Furthermore, this horizontal scaling approach is well-suited for applications with rapidly growing datasets or unpredictable spikes in traffic.
In contrast, traditional scaling, while capable of improving a server’s performance to some extent, has inherent limitations. It often encounters bottlenecks as resources on a single server are maxed out. Moreover, expanding vertically can be costly, and there’s a point at which it becomes impractical or prohibitively expensive.
3.2. Fault Tolerance
Sharding lends itself well to fault tolerance through data redundancy. By replicating shards across different servers or data centers, ensures that even if one shard or server fails, the system can continue to operate using backup shards. Therefore, redundancy minimizes the risk of data loss and downtime.
Traditional scaling, on the other hand, is more vulnerable to hardware failures. A single server failure can lead to service interruptions. While techniques like clustering can improve fault tolerance to some degree, they may not match the redundancy capabilities of sharding.
3.3. Resource Utilization
Sharding allows for precise resource allocation. Each shard can be provisioned with the resources it needs, optimizing performance and cost-efficiency. Therefore, this granularity ensures that resources are allocated where they are most effective.
Traditional scaling can be less efficient in resource utilization. Thus, scaling up a single server often involves over-provisioning resources, leading to underutilization in some cases. Further, this inefficiency can increase operational costs.
3.4. Geographical Distribution
The geographical distribution of data is increasingly important. Sharding supports this need by allowing data to be stored closer to end-users in different regions. This can significantly reduce latency and enhance user experience.
Traditional scaling may struggle to achieve geographical distribution, as it relies on a single server. Thus, data must often be centralized, leading to potential latency issues for distant users.
3.5. Comparison
There are two primary approaches to database management and scaling: sharding and traditional scaling. Sharding distributes data across smaller servers for scalability and performance, while traditional scaling boosts a single server’s hardware temporarily. In this table, we’ll provide a concise comparison to guide data and application management choices:
Sharding
Traditional scaling
Precise resource allocation
Less efficient in resource utilization, may increase costs
Provides a lot of efficient scaling ways
Less efficient in scalability, can encounter bottlenecks
Reliable fault tolerance through data redundancy
More vulnerable to hardware failures
Sharding supports geographical distribution well and this can lead to significantly reducing latency
It may struggle to achieve geographical distribution, as it relies on a single server
4. Is Sharding the Right Solution?
The decision to implement sharding in the organization’s database should be considered carefully. Thus, it requires a comprehensive understanding of our organization’s needs, goals, and constraints. In this section, we’ll provide a few steps to determine whether sharding is the right solution.
Firstly, we need to evaluate our organization’s scalability requirements. Do we anticipate rapid data growth or sudden spikes in traffic? Moreover, consider the scalability limitations of our current database solution. If we find that the existing system struggles to handle increasing data volumes and user loads, sharding may be a suitable solution.
Furthermore, examine how our data is distributed and accessed. Are there natural divisions within our dataset that could be assigned to different shards? If our data can be logically partitioned based on certain criteria, such as user location or product categories, sharding becomes a viable option.
Moreover, we need to assess the organization’s budget for database management. While sharding can offer excellent scalability, it may involve additional costs, such as setting up and maintaining multiple servers or cloud instances. Thus, ensure that the organization is financially prepared for the investment required.
Further, we need to consider the importance of fault tolerance and high availability. Does our organization require uninterrupted service even in the face of hardware failures or server outages? Sharding can provide redundancy and fault tolerance, but it’s essential to weigh this against the organization’s specific needs.
Sharding allows for precise resource allocation, ensuring that each shard is provisioned with the necessary resources. Evaluate whether optimizing resource utilization aligns with our organization’s performance and cost-efficiency goals.
We should consider data privacy and compliance requirements, especially if the organization deals with sensitive or regulated data. Sharding can impact how data is stored and accessed, potentially affecting compliance efforts.
Finally, it’s important to think about the organization’s long-term plans. Will the data management needs continue to evolve? Does our roadmap include expansion to new regions or markets? Sharding’s scalability and geographical distribution capabilities can be advantageous for accommodating future growth.
5. Drawbacks
In the previous sections, we’ve mentioned a lot of sharding’s benefits. Although, while sharding offers numerous advantages, it could also provide some limitations.
Firstly, implementing sharding can be complex. It requires careful planning, including shard key selection, data distribution strategies, and query routing mechanisms. Therefore, this complexity can be a barrier for organizations with limited expertise in database management.
Secondly, while sharding can provide scalability, it may also come with additional costs. Further, setting up and maintaining multiple servers or cloud instances can increase operational expenses. Thus, organizations must carefully assess their budget and financial readiness.
Further, sharding can impact data privacy and compliance efforts. Data may be distributed across different shards, potentially complicating compliance with regulations such as GDPR or HIPAA. This necessitates a thorough understanding of data governance and compliance requirements.
Lastly, sharding may not be necessary for small or moderate-sized datasets. Implementing sharding from the outset may introduce unnecessary complexity and costs. Thus, must consider whether the benefits of sharding outweigh the initial overhead for their specific dataset size.
6. Pros vs. Cons
Sharding, the practice of dividing a database into smaller segments or shards, offers numerous advantages and some challenges. In this table, we’ll briefly explore the key benefits and drawbacks of sharding, considering decisions regarding database management, scalability, and performance optimization:
Pros
Cons
Provides efficient scalability
Choosing the appropriate shards can be complex and impact the efficiency
Lots of servers and clouds provide automated sharding
Those solutions can increase the costs
Sharding is effective in protecting the data and handling failures
Sharding can impact data storing regulations and compliance efforts
Sharding allows individual instances to not be overly huge, increasing performance
Joining data between shards can be complex and overwhelming
7. Conclusion
In this article, we described sharding in detail. Sharding offers scalability, fault tolerance, and efficiency but demands careful consideration.
Sharding is not well suited for every database. Moreover, it requires careful implementation, especially while choosing sharding techniques. Further, it can be a complex and costly solution.