1. Overview
This article discusses the types of approaches to spam detection that we can use in various circumstances. We’ll also see what training datasets are publicly available for the construction of spam detectors in English and in some other languages.
2. What Is Spam?
A message is considered spam if it’s unwanted by the receiver. This means that no message is, in abstract terms, a spam message; but rather all spam messages are such only in relation to a particular receiver that doesn’t want them.
This is a problem for us if we want to build a spam detector: different users have different preferences, and we can’t aprioristically predict which messages they’ll want to receive and which not. We can see what this means with an example.
Common spam emails are, for instance, those that relate to the sale of medicines, financial services, or adult content. They may not, however, be spam if the user is:
- currently searching for painkillers
- looking for a loan, or
- interested in adult content
Theoretically, we want the user to first express their preferences to us in a sufficiently clear manner, so we can then build a system that filters out all unwanted messages. Let’s, for now, imagine that this happened and that we have a clear picture of what the user wants and what they don’t.
So how do we then proceed to build a spam filter from here?
3. Rule-Based and Statistical Approaches to Spam Filtering
3.1. Rule-Based Approach
There are three main approaches to the creation of a system for the detection of spam in a corpus of emails. The first approach is rule-based and works by classifying as spam all texts that satisfy certain sets of RegEx patterns:
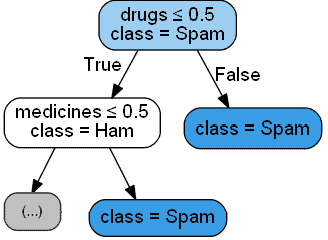
Programmers identify these patterns a priori, which leads them to be static and unchangeable.
We should select this approach when we have to share the same spam filter across multiple users; in doing so, keep in mind that the system will be difficult to scale since all rules must be input by hand.
3.2. Statistical Approach
Another approach is the statistical method, which we can implement by means of machine learning.
This method requires us to check features of words or texts and compare them against the associated spam labels. In doing so, a machine learning algorithm can then learn how to classify previously unseen texts as spam on the basis of a learned training dataset.
This is, for instance, how the coefficient matrix of a Bernoulli Naive Bayesian classifier for spam looks after training:
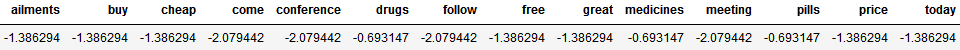
3.3. Hybrid Approaches
Finally, there are hybrid approaches that merge rule-based and statistical methods. They are somewhat less common and rarer to find in commercial applications, at least for emails in the English language, while statistical methods are the most common.
It should be noted that, while the statistical approach is the most suited for English, this is not generally valid for all languages. Some, and in particular Chinese, benefit more from using hybrid methods instead. This means that we should consider the specificity of language structures when building spam detectors.
Regardless of the approach we choose, when creating a spam filter we’ll need to first create a base detector that identifies spam, and then update it online with the preferences expressed by the user.
So how do we create a base spam classifier, which we can then adapt to the specific preferences of any individual user?
We need a training dataset. To find a dataset we have two options: either we develop it ourselves on the basis of the individual user’s behavior, or we find a premade one and adapt it.
4. Datasets for Spam Detection
4.1. User Preferences: Why We Can’t Always Use Them
When filtering spam for a user, the ideal dataset is the one which that user creates. By using that dataset, the spam filter would replicate exactly that user’s preferences, and not somebody else’s.
This means that, ideally, we’d like to ask the user to label for us all messages they receive. They would then tell us which emails they consider to be spam, and we’d guess whether they want any given new email on the basis of their preferences.
Users do exactly this when they flag an email as spam in an email client. As a consequence, we might think to take advantage of this behavior and use it to build our training dataset. This is however seldom possible for two main reasons:
- New users of an email service need time to receive enough spam emails and to label them for us
- Old users of an email service wouldn’t want to go through all their old emails and label them accordingly
This also means that building a base spam detector by using individual user preferences is unlikely to happen, though not impossible in principle. It can only happen though when new users receive many spam messages and diligently label them for us accordingly.
4.2. Publicly Available Datasets
The second solution which, while not ideal, is in practice very common, is to use a premade dataset for the identification of spam. Several datasets of this type are available, for both commercial and scientific purposes:
- The Spambase dataset from UCI is very popular as a training dataset for spam filters for emails. This is the dataset that we suggest to those who are approaching the problem of spam detection for the first time
- The SMS Spam dataset, also from UCI, is another frequently-used training dataset which is better suited for the classification of SMS or short texts rather than exactly emails
- The SpamAssassin dataset is another common training dataset for spam detection. Its main advantage is the subdivision of both spam and ham into further classes on the basis of their difficulty. This allows the testing of a spam filter against increasingly harder groups of texts
- The Enron Spam dataset contains the raw text of emails, which allows the training of algorithms on email headers as well as texts, rather than just word features
4.3. Datasets in Other Languages
For languages other than English a ready-made public training dataset for spam classification is not always available. We can, in that case, find datasets of texts, and of internet texts in particular, and work up from those.
If we can put some work into a text corpus we can sometimes re-adapt it for training a spam classifier. If, for example, a certain dataset lacks the labels for spam classification, that doesn’t mean we can’t use it. In that case, we can still either label the texts manually or use automatic methods for their labeling.
We can see here some text datasets for languages other than English:
- For Arabic, the Extended Arabic Web Spam 2011 Dataset is the best resource, though it relates to webpages and not specifically to emails. It uses word features rather than tokens, but some of these, such as word length, are applicable to emails as well as webpages
- For German, CodE ALLTAG contains a large corpus of anonymized emails but lacks labels for the classification of emails as spam or ham. We, therefore, need to label all texts by hand or automatically prior to usage
- For Italian, the EPHEMERA subcorpus of CORIS contains a section dedicated to letters, and can be used for research but not for commercial purposes. The texts lack spam labels, so we have to perform manual or automatic tagging for them
- For French, we can use a corpus of emails called CoMeRe simuligne. The corpus only contains ham, not spam, and we must thus complement it from other sources
4.4. Proprietary Datasets
Since user emails contain personal and sensitive information, it’s generally hard to find open datasets for the classification of emails. With the exception of the ones in English, indicated above, such datasets are generally not publicly available. If we still need a more specific dataset, we can sometimes obtain access to it from those who have one.
All email service providers own proprietary datasets, and can in some cases grant access to third parties. This type of access is normally given on the basis of a commercial or research contract. Programmers or researchers can negotiate this type of contract directly with the service providers.
5. Conclusions
In this article, we’ve seen what are the main approaches to spam filtering. We commonly use the rule-based approach when we share the same spam filter between multiple users. We use instead the statistical approach when the spam filter must be scalable.
We’ve also seen what are the most common public datasets for the initial training of spam classifiers. We discussed which ones are available in English and other languages, and have seen what features they possess.