1. 概述
在本教程中,我们将学习两种在向量空间中衡量点之间距离的重要方法:欧氏距离(Euclidean Distance) 和 余弦相似度(Cosine Similarity)。
接着,我们会使用它们对一个样本数据集进行分析,提取特征信息,并探讨在不同场景下应该优先使用哪种方法,以及它们各自的优势。
2. 向量空间中的距离度量
2.1. 什么是距离?
欧氏距离和余弦相似度都是用来衡量向量空间中向量之间相似程度的方法。在开始之前,我们先明确什么是向量之间的“距离”。
我们来看下面这张图:
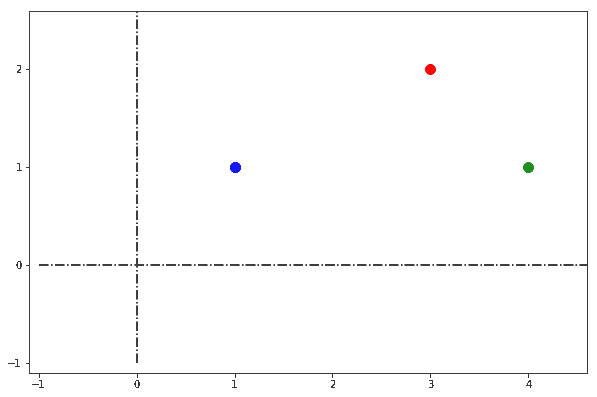
这是一个二维向量空间,其中有三个点:蓝色、红色和绿色。我们可以问:哪一对点之间的距离最近?
这个问题的答案可以有七种可能性(包括所有组合)。那我们如何判断哪一个是正确的?这就需要一个明确的距离度量方式。
2.2. 使用尺子度量距离
最直观的方式是用尺子测量两个点之间的直线距离。测量完所有点对后,我们可以列出一个表格:
| 点对 | 欧氏距离 |
|---|---|
| (red, green) | √2 |
| (blue, red) | √3 |
| (blue, green) | 3 |
可以看到,(red, green) 的距离最短。因此,从“尺子”角度看,红色和绿色点是最接近的。
2.3. 使用量角器度量距离
换一个角度,我们假设自己站在原点,观察这些点的方向。我们不关心它们离原点多远,只关注它们相对于参考轴的方向。
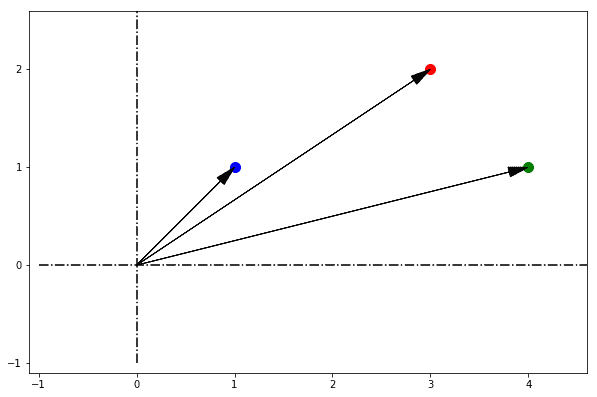
在这种视角下,我们关注的是方向差异,也就是它们之间的角度差异。计算出的角度距离如下:
| 点对 | 角度距离 |
|---|---|
| (blue, red) | 0.1973 |
| (red, green) | 0.3430 |
| (blue, green) | 0.5404 |
此时,最接近的点对变成了 (blue, red)。这说明,视角不同,结果也不同。
2.4. 推广到高维空间
上面的例子是二维的,但这个思路可以推广到任意维度的向量空间中:
- 欧氏距离:衡量的是向量之间的“绝对距离”,适用于我们从“鸟瞰图”视角下看到的距离。
- 余弦相似度:衡量的是向量之间的“方向夹角”,适用于我们站在原点看方向差异的视角。
3. 欧氏距离的正式定义
在 n 维空间 ℝⁿ 中,给定两个向量:
- x = (x₁, x₂, ..., xₙ)
- y = (y₁, y₂, ..., yₙ)
它们之间的欧氏距离定义为:
$$ ||x - y||_2 = \sqrt{(x_1 - y_1)^2 + (x_2 - y_2)^2 + \cdots + (x_n - y_n)^2} $$
这其实就是两个向量差的 L2 范数。
✅ 欧氏向量空间:像 ℝⁿ、ℂⁿ、ℤⁿ 这样的空间被称为欧氏向量空间。
在机器学习中,很多算法(如 K-Means)依赖于欧氏距离,因此在使用这些算法时,我们通常只能使用欧氏距离作为度量标准。
4. 余弦相似度的正式定义
余弦相似度衡量的是两个向量之间的夹角余弦值。其公式为:
$$ \text{cos}(\theta) = \frac{x \cdot y}{||x|| \cdot ||y||} $$
其中:
- $ x \cdot y $ 是向量的点积
- $ ||x|| $ 和 $ ||y|| $ 分别是向量的模长
⚠️ 注意:余弦相似度的取值范围是 [-1, 1]:
- 1 表示方向完全一致
- 0 表示正交
- -1 表示方向完全相反
如果我们想将余弦相似度转换成角度距离,可以使用下面的公式:
$$ \text{Angle Distance} = \frac{\cos^{-1}(\text{cos}(\theta))}{\pi} $$
5. 在 Iris 数据集中的应用
我们以经典的 Iris 数据集为例,来看欧氏距离和余弦相似度在实际中的表现。
5.1. 基于欧氏距离的聚类
下图是 Iris 数据集在二维空间中的分布,颜色代表不同种类的花:
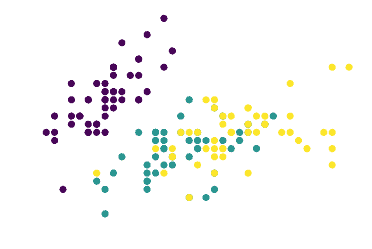
使用 K-Means 算法进行聚类后,我们得到了如下结果:
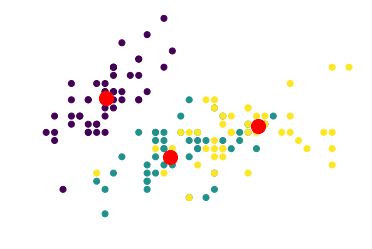
可以看到,紫色和青色簇之间的欧氏距离最小。这说明这两个类别的花在“花瓣长度和宽度”的绝对值上更接近。
5.2. 基于余弦相似度的聚类
如果我们使用球面 K-Means(Spherical K-Means),基于余弦相似度进行聚类,结果如下:

此时,青色和黄色簇之间的余弦相似度最高。这说明它们在“花瓣长宽比”上更接近,也就是说它们的形状相似,只是大小不同。
5.3. 对比与解读
我们来总结一下两种方法的含义:
| 度量方式 | 说明 |
|---|---|
| 欧氏距离 | 表示向量在空间中“位置接近”,适合比较“绝对值相近”的情况 |
| 余弦相似度 | 表示向量“方向一致”,适合比较“比例相似”的情况 |
在 Iris 数据集中:
- 欧式距离聚类:紫色和青色花更接近 → 表示它们的花瓣大小接近
- 余弦相似度聚类:青色和黄色花更接近 → 表示它们的花瓣形状更相似
✅ 总结:
- 向量之间欧氏距离小,说明它们在“丰富度”上相近
- 向量之间余弦相似度高,说明它们像是彼此的“缩放版本”
6. 何时使用哪种度量?
选择使用哪种度量方式,取决于具体任务:
| 场景 | 推荐度量方式 |
|---|---|
| 初步数据分析 | 两者都可,互补使用 |
| 文本分类 | 欧氏距离 |
| 相似文档检索 | 余弦相似度 |
| 需要关注“绝对值”差异 | 欧氏距离 |
| 需要关注“方向”或“比例”关系 | 余弦相似度 |
⚠️ 经验之谈:
- 欧氏距离更适合关注“数值大小”的场景
- 余弦相似度更适合关注“结构/比例”的场景
7. 总结
- ✅ 欧氏距离 是向量差的 L2 范数,衡量的是向量在空间中的“绝对距离”
- ✅ 余弦相似度 是向量点积除以模长乘积,衡量的是方向的一致性
- ✅ 向量之间欧氏距离小,说明它们在空间中“靠得近”
- ✅ 向量之间余弦相似度高,说明它们“方向一致”或“比例相似”
通过理解这两种度量方式背后的几何含义,我们能更准确地选择适合当前任务的度量方式,从而提升模型效果和分析深度。