1. 概述
稀疏编码神经网络是一种机器学习技术,其核心思想是通过学习一组基函数(basis functions),将输入数据表示为这组基函数的线性组合,且组合系数尽可能稀疏(即大多数系数为零或接近零)。
这种方式能带来几个优势:
✅ 数据表示更加紧凑、高效
✅ 可用于去噪、压缩、分类等任务
✅ 支持无监督学习,适用于各种数据类型
简而言之,稀疏编码的目标是找到一个稀疏表示,使得在重构误差最小的前提下,数据能被尽可能少的基函数线性组合所表达。
2. 稀疏编码原理
稀疏编码的基本思路是将原始数据映射到一个高维特征空间,然后使用少量的基函数来表示数据。
具体来说:
- 通过一个编码矩阵 D(也称为字典)将数据 X 表示为稀疏向量 h
- 同时通过解码过程,使用同样的字典 D 从稀疏表示 h 中重建原始数据 X
因此,整个过程包含两个关键步骤:
- 字典学习(Dictionary Learning):从训练数据中学习字典 D
- 稀疏编码(Sparse Encoding):给定新数据 X 和已学习的字典 D,求出其稀疏表示 h
数学上,稀疏编码的目标函数通常表示为如下形式:
(1) $$ \mathbf{X} \approx \sum_{i=1}^n h_i \mathbf{d}_i = h\mathbf{D} $$
(2) $$ \begin{array}{r} \min D \frac{1}{N} \sum{k=1}^N \min _{h_k} \frac{1}{2}\left|x_k-D h_k\right|_2^2+\lambda\left|h_k\right|_1 \ \text { subject to }\left|D_i\right|_2^2 \leq C \quad \forall i=1, \ldots, N \end{array} $$
其中:
- X 是输入数据
- D 是字典矩阵(decoder matrix)
- h 是稀疏表示向量
- λ 是稀疏性约束系数
- C 是字典中每个基向量的范数约束
这个优化问题包含两个嵌套的最小化过程:
- 外层优化:调整字典 D,以最小化数据重构误差
- 内层优化:通过最小化 L1 范数,使稀疏表示 h 尽可能稀疏
2.1 Java 实现示例
下面是一个简化的稀疏编码学习过程的伪代码实现:
algorithm SparseCodingLearningProcess(X, N, D):
// INPUT
// X = the dataset with N samples and D features
// K = dictionary size
// λ = sparsity constraint
// max_iter = maximum number of iterations
// OUTPUT
// D = the dictionary of basis functions
// Initialize the dictionary of basis functions
D <- a random K x D matrix
while there is an x in X:
r <- x
while i < max_iter:
while there is d in D:
D` <- apply Eq.(2)
D_x <- D`
return D
⚠️ 注意:实际应用中建议使用成熟的数值计算库(如 NumPy、Scikit-learn)来实现稀疏编码,而不是手动实现底层算法。
3. 稀疏编码神经网络
从生物神经学的角度来看,稀疏编码是神经编码(neural coding)的一种表现形式。设想一个包含 N 个二值神经元的神经网络:
- 网络接收输入并产生输出
- 某些神经元频繁激活,而大多数神经元保持沉默
- 对于特定输入,激活的神经元组合构成了该输入的“神经编码”
因此,稀疏编码可以理解为:
- 输入数据被稀疏地激活,即只有少数神经元参与响应
- 这种稀疏激活模式形成了数据的高效内部表示
下图展示了一个稠密神经网络与稀疏神经网络的对比:
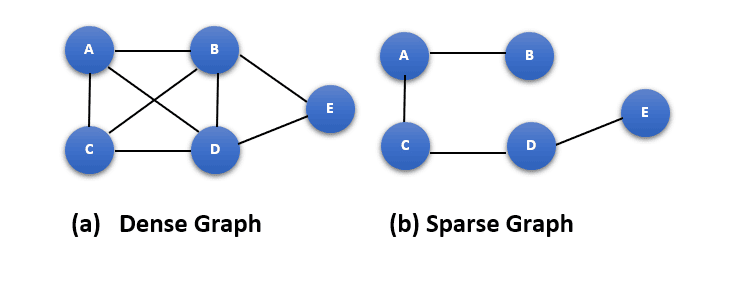
✅ 稀疏神经网络的优势:
- 更低的计算资源消耗
- 更强的泛化能力
- 更接近生物神经系统的运行机制
4. 稀疏编码的应用
稀疏编码已被广泛应用于多个领域,包括:
- 脑成像:用于分析大脑活动模式
- 自然语言处理:用于词向量学习和语义建模
- 图像与语音处理:用于特征提取、降噪、压缩等任务
在实现层面,Python 的 Scikit-learn 库提供了 SparseCoder 模块,支持字典学习和稀疏编码功能,非常便于快速实验和部署。
5. 总结
稀疏编码是一种强大的机器学习技术,能够从复杂数据中提取出紧凑且高效的表示形式。
其核心思想是:
✅ 使用少量基函数组合表达数据
✅ 强制系数稀疏以提高模型泛化能力
✅ 支持无监督学习,适用范围广
从图像处理到脑科学研究,稀疏编码都展现了良好的表现力和实用性。
如果你正在处理高维、非结构化数据,稀疏编码是一个值得尝试的建模思路。