1. 简介
在本教程中,我们将展示如何找到树的中心节点。树的中心节点在图论中有明确定义:它是到树中其他所有节点的最长路径长度(称为偏心距)最小的那个节点。
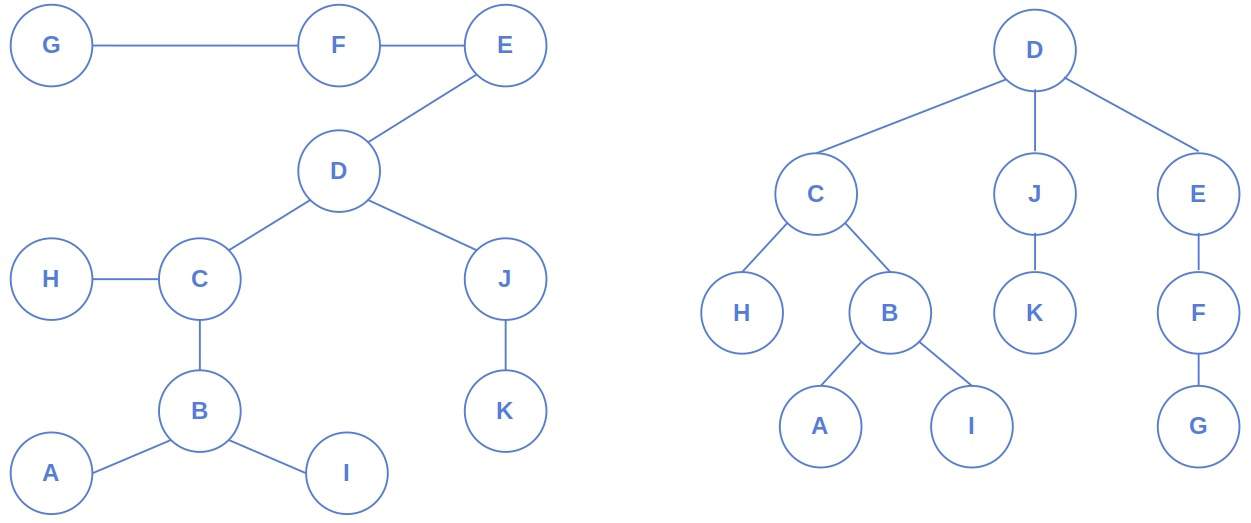
左边是未加权、无向、无根的树,右边是将中心作为根节点后的树结构。
这就是为什么我们要关注树的中心节点的原因。有时候,我们拿到的树只是普通的图结构,没有指定根节点。我们的任务是给它选一个合适的根节点进行建树,而选择中心节点作为根节点往往在很多应用场景中表现最佳。
我们假设所处理的树都是无权、无向且无根的。
1.1 中心与直径
树的直径是指树中最长的路径。一个树可能有多个直径路径。我们可以证明:树的中心节点一定位于其直径路径的中点位置。
假设直径的两个端点为 x 和 y,若该直径路径包含奇数个节点,那么它的中间节点为 z。若存在另一个节点 z' ≠ z 被认为是中心节点,并且 w 是 z' 最近的直径节点,那么可以证明 z' 的偏心距一定大于 z,因此 z' 不可能是中心节点。
若直径包含偶数个节点,则有两个中间节点,它们都是该树的中心节点。
2. 算法
基于上述特性,我们可以通过不断“剪枝”最外层节点的方式,逐步向树的中心逼近。
具体来说,每次移除当前最外层(度为1)的节点,直到只剩下1或2个节点为止。这些最终保留下来的节点就是树的中心节点。
algorithm FindingCenterOfUnweightedTree(T):
// INPUT
// T = an undirected, unrooted, and unweighted tree
// OUTPUT
// The center of T if T is not empty, an empty set otherwise
if T is empty:
return empty set
degrees <- the nodes degrees
surface <- find the nodes with only 1 neighbor
while |surface| > 2:
inner <- empty set
for node in surface:
parent <- the only neighbor of node
degrees[parent] <- degrees[parent] - 1
if degrees[parent] = 1:
inner <- inner union {parent}
surface <- inner
return surface
该算法隐式地构建了一个树的层次结构。同一轮中处理的节点属于同一层,下一轮处理的是它们的父节点。最终,中心节点会被保留下来,作为树的根节点。
2.1 示例演示
我们来看一个具体示例:
初始时,最外层节点为 A、G、H、I、K:
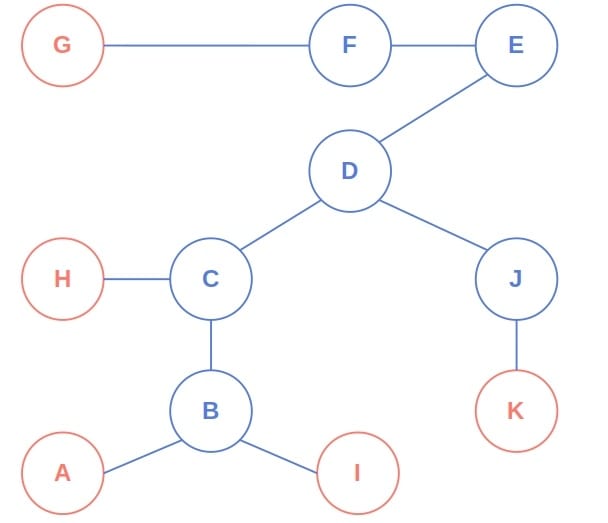
第二轮,最外层变为 B、J、F:

第三轮处理 C 和 E,最后只剩下 D,即中心节点。
2.2 正确性证明
设 T_i 是第 i 次迭代后保留下来的子树。我们维护一个循环不变式:T_i 与原始树 T 的中心节点相同。
- 初始状态:
T_0 = T,显然成立。 - 归纳假设:假设
T_i与T的中心相同。 - 归纳步骤:在
T_i中移除所有度为1的节点(即直径的端点),所有直径路径都会从两端各减少一个节点,因此中间节点不变,中心不变。
因此,最终保留下来的节点就是原始树的中心节点。最多只能有两个中心节点,因为每条直径最多有两个中点。
2.3 时间复杂度分析
- 初始化节点度数:如果邻居信息存储在数组中,可以在 O(1) 时间读取长度,整体为 O(n)
- 主循环中每条边只被处理一次,总边数为 n - 1,因此循环部分也为 O(n)
- 总体时间复杂度为 **O(n)**,线性时间
3. 小结
我们介绍了如何在线性时间内找出一个无权树的中心节点。这些节点位于树中最长路径的中点位置。每个树最多有两个中心节点。
该算法简单高效,适用于需要快速找到树的“中心”结构的场景,例如网络拓扑优化、树形结构的可视化布局等。