1. 简介
栈(Stack)是一种经典的线性数据结构,具有“后进先出”(LIFO, Last In First Out)的特点。实现栈的方式有多种,包括固定大小数组、动态数组和链表等。
本文将重点讲解使用固定大小数组实现栈的方式。这种方式实现简单,适合对栈大小有明确限制的场景。
2. 固定大小数组实现原理
固定大小数组实现的栈,核心包括以下三个关键元素:
elements[]:用于存储栈元素的固定大小数组top:一个整型变量,表示当前栈顶元素的索引capacity:栈的最大容量,即数组的长度
在本文讨论中,我们假设数组是1索引的(即第一个元素位于索引 1),这与部分教材或算法书保持一致。
举例说明
假设我们初始化一个容量为 6 的空栈:
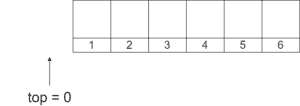
此时 top = 0,表示栈为空。
添加元素 11 后:

此时 top = 1,elements[1] = 11
继续添加 7 和 25:
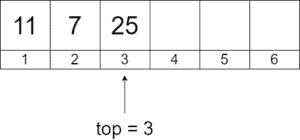
此时 top = 3,elements[3] = 25
如果弹出栈顶元素后:

此时 top = 2,但 elements[3] 的值仍然保留,只是不再被访问。
✅ 注意:弹出操作并不会清除旧值,只是移动指针。
3. 栈的操作与伪代码
3.1. Push(入栈)
algorithm PUSH(S, a):
// INPUT
// S = a stack
// a = the element to be added to the stack
// OUTPUT
// The element is added on top of the stack
if the stack S is full:
report an error or log the problem
return
S.top <- S.top + 1
S.elements[S.top] <- a
3.2. Pop(出栈)
algorithm POP(S):
// INPUT:
// S = a stack
// OUTPUT:
// The top element of the stack is removed
if the stack S is empty:
report an error or log the problem
return
element <- S[S.top]
S.top <- S.top - 1
return element
3.3. Top(获取栈顶元素)
algorithm TOP(S):
// INPUT:
// S = a stack
// OUTPUT:
// Returns the top element of the stack
// or null if the stack is empty.
if the stack S is empty:
report an error or log the problem
return null
return S.elements[S.top]
3.4. Empty(判断栈是否为空)
algorithm EMPTY(S):
// INPUT:
// S = a stack
// OUTPUT:
// Returns true if the stack is empty, false otherwise
if S.top = 0:
return true
return false
3.5. Full(判断栈是否已满)
algorithm FULL(S):
// INPUT:
// S = a stack
// OUTPUT:
// Returns true if the stack is full, false otherwise
if S.top = S.capacity:
return true
return false
4. 实现的优缺点分析
✅ 优点:
- 实现简单:逻辑清晰,易于理解和编码。
- 内存使用可控:由于容量固定,适用于内存或资源受限的场景。
- 避免动态扩容带来的性能波动:不会因为扩容操作而出现性能抖动。
❌ 缺点:
- 容量固定:无法动态扩展,如果栈容量预估不准确,容易出现栈满或浪费内存的情况。
- 不适合动态数据量场景:比如不确定入栈元素数量时,容易溢出或浪费空间。
- 缺乏灵活性:相比之下,链表或动态数组实现的栈可以根据需要自动扩展容量。
⚠️ 踩坑提醒:实际使用中如果栈大小不可预测,建议使用动态数组或链表实现。
5. 小结
本文详细介绍了使用固定大小数组实现栈的原理与操作逻辑。我们通过图文结合的方式展示了栈的运行过程,并提供了标准的伪代码实现。最后,我们分析了该实现方式的优缺点,帮助你在不同场景下做出合适的技术选型。
✅ 总结建议:固定大小数组实现的栈适合嵌入式系统、资源受限环境或栈大小可预知的场景。如果需要更灵活的实现,可以考虑动态数组或链表实现。