1. 简介
在本教程中,我们将讨论安全计算(Secure Computation)以及它试图解决的一些实际挑战。
我们还将介绍一些为应对这些挑战而发展起来的重要密码学构造。在此过程中,我们会理解它们的实际应用场景。
2. 安全计算的挑战
密码学已有相当长的历史,甚至早于计算机的出现。当然,现代密码学随着计算机的发展而兴起。但早期的重点主要集中在保护传输中和存储中的数据安全。
在过去几十年中,越来越多的敏感数据在云环境中被生成、处理、传输和存储。此外,分布式和去中心化计算环境也给密码系统带来了新的挑战。
这正是安全计算发挥作用的地方。安全计算指的是在整个计算过程中数据都保持安全。这里的重点是数据在使用过程中的安全性。安全计算在现实中有很多应用场景。
2.1 加密数据上的计算
一个典型的数据应用通常从安全网络上的某个存储中获取加密数据,然后需要先解密这些数据才能进行计算。之后,它可能会对结果进行加密并发送回存储系统:
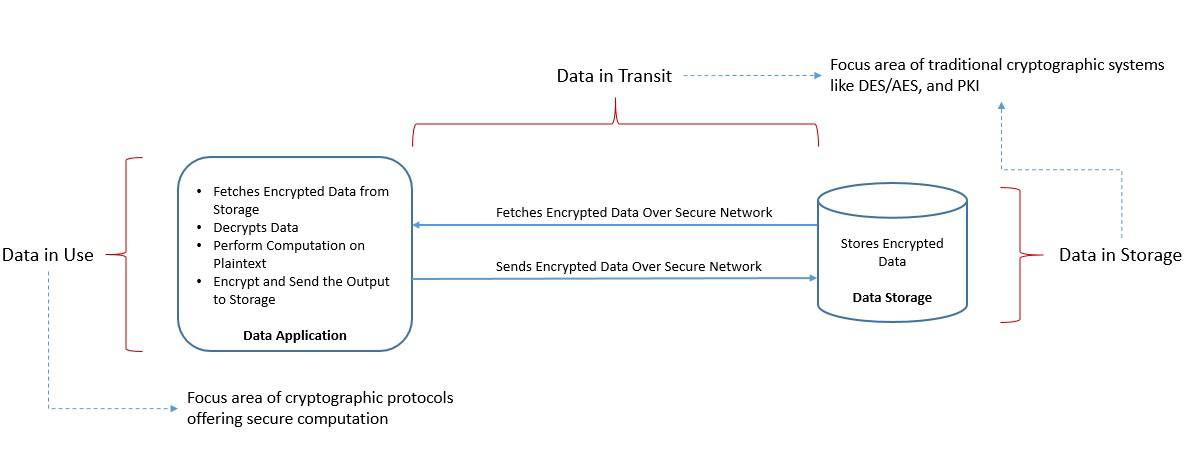
虽然这在大多数情况下是有效的,但数据在计算过程中仍然是暴露的。对于某些涉及敏感数据的应用场景来说,这可能并不理想。如果可以在不解密的情况下进行计算,那会不会更好?
2.2 安全分布式计算
分布式数据计算通常涉及两个或更多参与方。每个参与方可能通过加密方式安全地持有自己的数据。在一个典型场景中,其中一个参与方会扮演中心角色,从其他方获取数据、解密并执行计算:
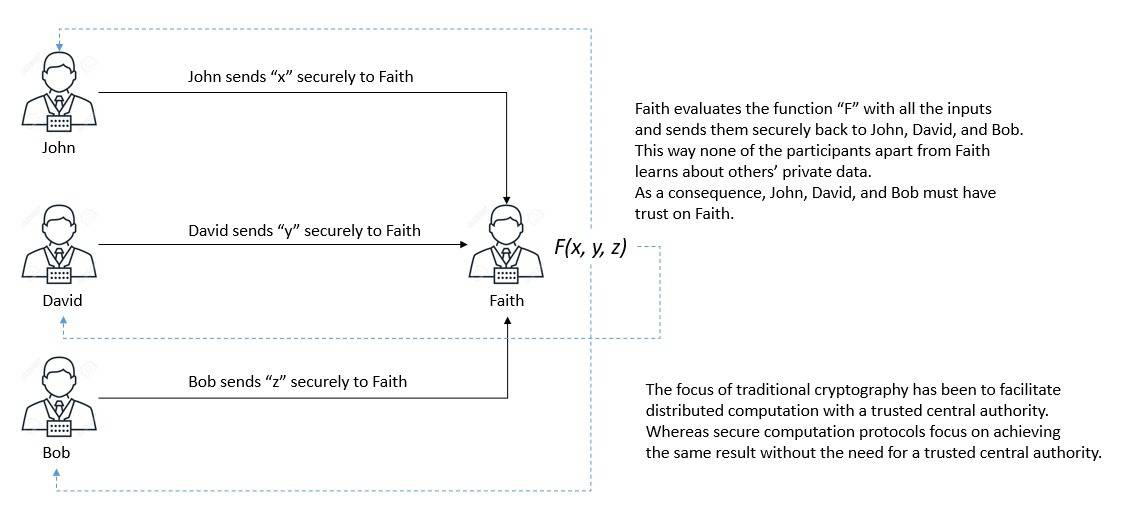
这隐式地要求中心方与其他所有参与方之间存在信任关系。但在某些情况下,每个参与方都希望在参与计算的同时保持自己的数据对其他方保密。这是否可能?
我们讨论的安全计算挑战,正是密码学领域长期研究的重点。为此,已经开发出了多种密码学构造。在本教程中,我们将介绍其中两种关键的密码学构造。
3. 同态加密(Homomorphic Encryption)
同态加密 是一种加密方式,允许我们在不解密数据的情况下对其执行计算,计算结果仍然保持加密状态:
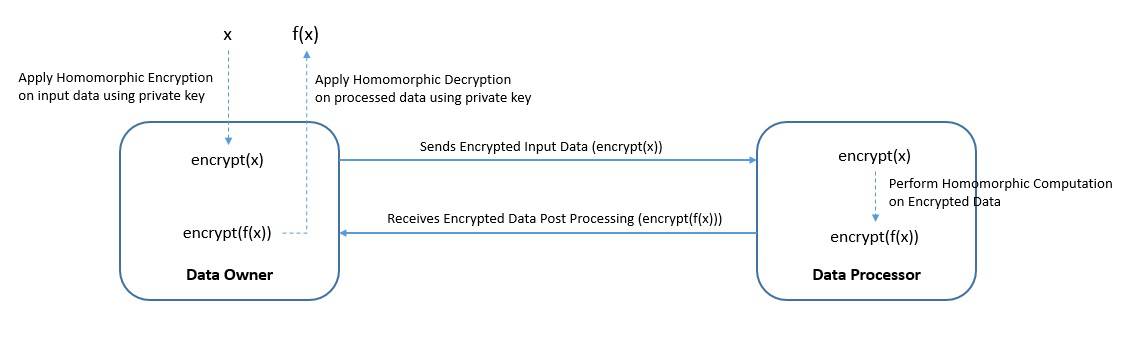
有趣的是,如果对结果进行解密,其输出将与在原始明文数据上执行相同计算的结果完全一致。
同态加密为敏感数据的外包服务提供了广泛的可能性。例如,我们可以将医疗数据发送给第三方进行预测分析,而无需担心数据隐私问题。
3.1 基本原理
代数中的 同态 是指两个相同类型代数结构之间的保持结构的映射。因此,它描述了将一个数据集转换为另一个数据集时,保持元素之间关系的过程:
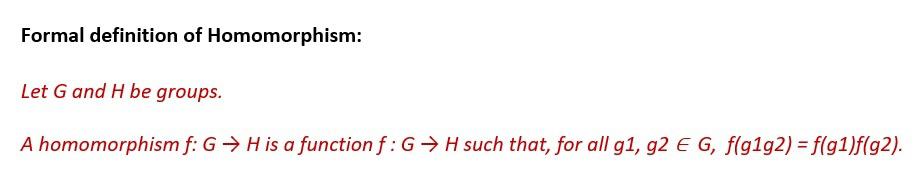
从这个定义延伸,我们可以将加密和解密函数视为明文和密文空间之间的同态映射。这是同态加密的基本工作原理。
在实践中,同态加密最适合处理以整数形式表示的数据,并使用加法和乘法等操作。它通常需要少量交互,并使用 算术电路,专注于加法和乘法。
每个操作都是一个数学函数,每个函数都可以转换为等效的电路。因此,对于每个函数  ,都存在某个电路
,都存在某个电路  ,使得
,使得  给出相同的输出。使用 电路计算模型 有助于简化加密方案的构造。
给出相同的输出。使用 电路计算模型 有助于简化加密方案的构造。
3.2 同态加密的类型
同态加密包括几种加密方案,允许我们对加密数据执行不同类别的计算:
- 部分同态加密(PHE):这些方案允许对密文执行一种定义好的操作(如加法或乘法),且可无限次执行。这些算法相对容易设计。
- 有限同态加密(SHE):这些方案允许对密文执行有限次数的加法和乘法操作。这些算法相对更难设计。
- 全同态加密(FHE):这些方案允许对密文执行无限次数的加法和乘法操作。这是最难设计的同态加密算法。
3.3 全同态加密的起源
全同态加密常被称为密码学的“圣杯”。考虑到密码学家为此投入的大量努力,这一说法是合理的。早在1978年(即RSA方案发布后不久),就有关于全同态加密的想法。
此后近三十年,研究人员提出了许多具有部分成果的算法。例如,ElGamal 密码系统(支持无限次模乘法),以及 Goldwasser-Micali 密码系统(支持无限次异或操作)。
直到2009年,Craig Gentry 才提出了第一个可行的 FHE 构造方法。他的想法基于基于格的密码学:
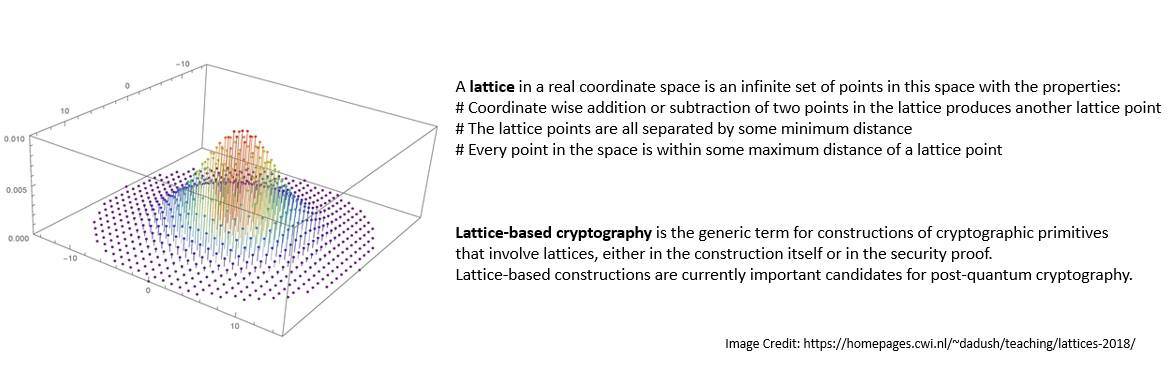
不久之后,Marten van Dijk 等人在2010年提出了另一个受 Gentry、Levieil-Naccache 和 Bram Cohen 早期工作启发的构造方法。
第一代密码系统的核心思想是构建一个有限同态加密系统,然后通过自举(bootstrapping)将其转换为全同态系统。然而,随着对密文执行的操作越来越多,密文中包含的“噪声”也会不断累积。
3.4 “圣杯”的持续追寻
第二代密码系统在同态计算过程中实现了噪声增长的大幅减缓。其中包括 2011 年提出的 Brakerski-Gentry-Vaikuntanathan (BGV) 方案和 2012 年提出的 Brakerski-Fan-Vercauteren (BFV) 方案等。
2013 年,Craig Gentry、Amit Sahai 和 Brent Waters 提出了第三代密码系统(GSW)。该方案的关键在于避免了同态乘法中的昂贵再线性化步骤。随后,FHEW(2014)和 TFHE(2016)对其进行了改进。
2016 年,Cheon、Kim、Kim 和 Song(CKKS)提出了第四代密码系统。它是一种支持块浮点运算的近似同态加密系统。对“圣杯”的追寻仍在继续,未来还将继续。
3.5 FHE 的实现
多个开源库提供了不同代际 FHE 方案的实现,例如:
- BGV/BFV(第二代)
- FHEW/TFHE(第三代)
- CKKS(第四代)
一些知名库包括:
- **HElib**:由 IBM 的 Shail Halevi 和 Victor Shoup 开发,用 C++ 实现,支持 BGV 和 CKKS 方案。
- **SEAL**:由微软研究院开发,也用 C++ 实现,支持 BGV/BFV 和 CKKS。
- **OpenFHE**:继承自早期的 PALISADE 和 SIPHER,2022 年发布,支持后量子公钥加密等功能。
3.6 FHE 的局限性
尽管 FHE 有诸多承诺,但其应用仍然非常有限。主要原因在于所有全同态加密方案都带来巨大的计算开销。这体现在加密版本与明文版本的计算时间差异上。
据报道,使用 HElib 第一版进行同态操作的速度比明文操作慢了一万亿倍。当然,这已经显著改善,研究仍在继续提升性能。
此外,还有其他操作上的问题,例如:
✅ 运行非常大且复杂的算法效率不高
✅ 多用户支持复杂:系统可能需要为每个用户维护独立数据库以保障数据安全
4. 安全多方计算(Secure Multi-Party Computation)
安全多方计算 是密码学的一个子领域,它允许多个参与方共同计算一个函数,同时保持各自的输入隐私:
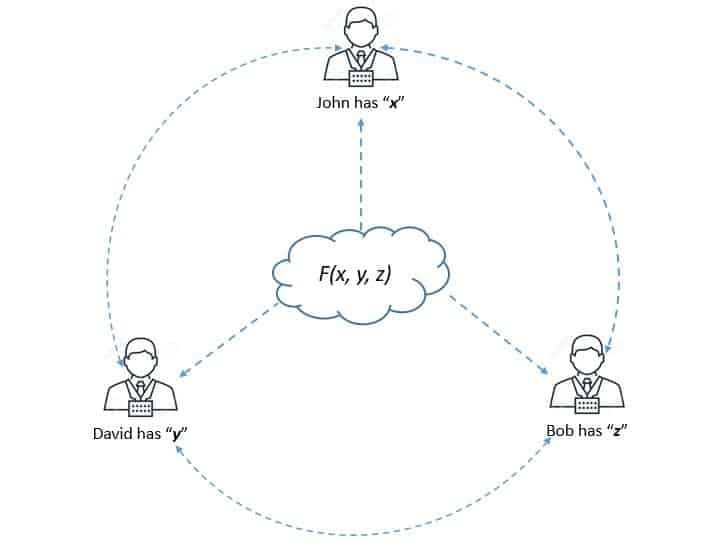
在传统密码学中,目标是防止外部攻击者窃取通信或存储内容。而在安全多方计算中,目标是保护参与方之间的隐私。
安全多方计算使数据科学家和分析师能够在不暴露数据的前提下合规、安全、私密地对分布式数据进行计算。它在电子拍卖、电子投票等场景中也有广泛应用。
4.1 基本原理
安全多方计算的基本模型包括多个参与方(如 p₁, p₂, ..., pₙ),每个参与方都有自己的私有数据(如 d₁, d₂, ..., dₙ)。目标是计算一个公开函数 F(d₁, d₂, ..., dₙ):
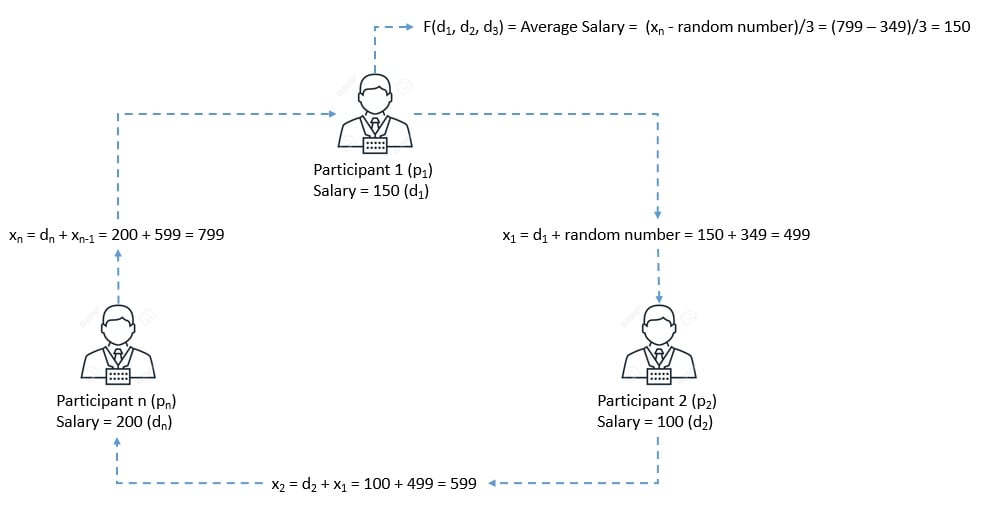
例如,目标是计算平均薪资,同时保持每个参与者的薪资对其他参与者保密。
一个实用的安全多方计算协议应具备以下基本特性:
- 输入隐私:参与者在协议执行过程中发送的消息不应泄露任何私有数据信息。
- 正确性:任何试图偏离协议的恶意参与方不能迫使诚实方输出错误结果。
4.2 多方计算的安全性
安全性是多方计算协议的关键考虑因素。不同于传统密码应用,多方协议的攻击者可能是协议的参与者之一。根据系统中这类攻击者的类型和数量,协议会有显著差异。
假设在一个协议中有 n 个参与方,其中 t 个可能是恶意的。若我们能假设诚实多数(t < n/2),则解决方案和协议会完全不同。
我们还可以根据攻击者偏离协议的意愿程度来分类安全性类型:
- 半诚实安全(Semi-honest):攻击者仅从协议中收集信息,不会偏离协议。此类协议效率较高。
- 恶意安全(Malicious):攻击者可能任意偏离协议以试图作弊。此类协议提供更高的安全性,但牺牲了效率。
4.3 两方计算协议
虽然专用协议在 1970 年代就已出现,但安全计算作为安全两方计算(Secure Two-Party Computation)由 Andrew Yao 在 1982 年正式提出,用于解决著名的“百万富翁问题”。
后来,Yao 在 1986 年提出了一个通用协议,用于评估任何可行的计算。这两篇论文启发了后来被称为 Yao 混淆电路协议 的发展。
Yao 协议对半诚实攻击者是安全的,并且在轮次效率上非常高效。函数在此被设想为一个 布尔电路,即由门连接的三种不同类型导线组成的电路:
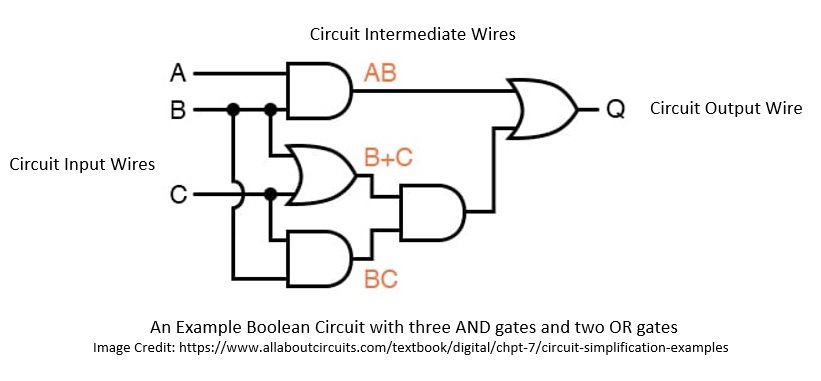
Yao 协议建议如何 混淆电路,使得两方可以仅学习电路输出。发送方准备混淆电路并发送给接收方,后者在不知情的情况下评估电路:
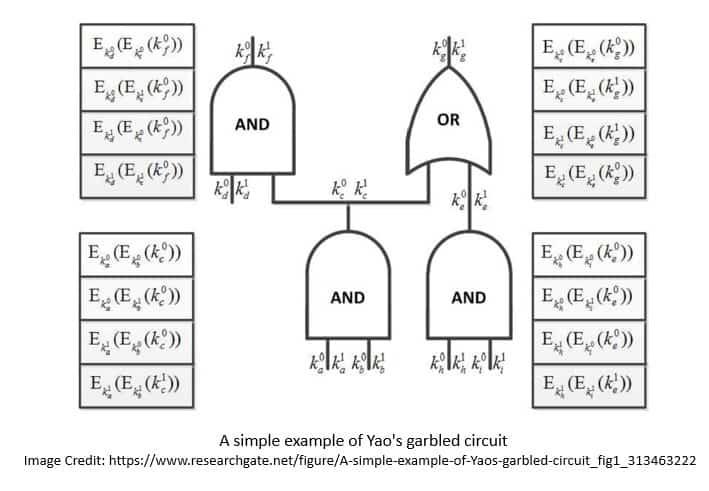
接收方学习其与发送方输出的编码,并将发送方的编码返回。发送方完成自己部分的输出,然后将接收方输出编码到比特的映射发回,使接收方获得其输出。
4.4 多方计算协议
两方计算协议后来由 Goldreich、Micali 和 Wigderson(GMW)推广到多方计算。该计算基于所有输入的秘密共享(secret sharing)和潜在恶意情况下的零知识证明。
在基于 秘密共享 的方法中,每根导线的数据在参与方之间共享,然后使用协议评估每个门。函数在此被定义为有限域上的电路,也称为 算术电路。
常用的秘密共享方案包括:
- Shamir 秘密共享
- 加法秘密共享
两者都可以将秘密分发给多个参与方,每个参与方获得随机的有限域元素作为份额:
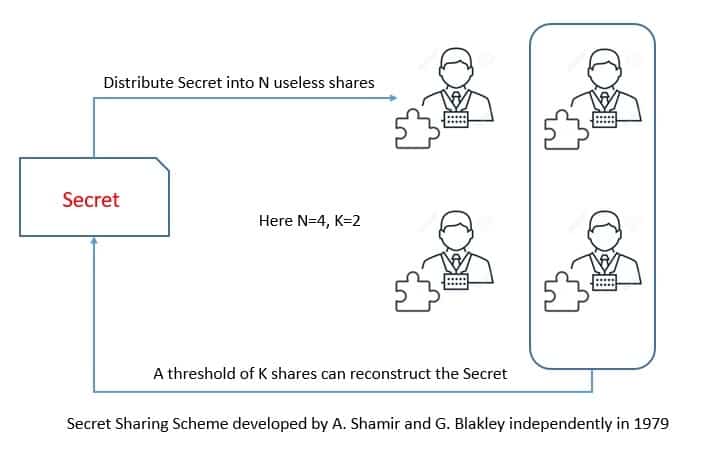
不同的方案能容忍不同数量的攻击者。例如:
- Shamir 秘密共享在被动攻击者下容忍 t < n/2,在主动攻击者下容忍 t < n/3
- 加法秘密共享在主动攻击者下也能容忍 t < n - 1
SPDZ 是一个流行系统,使用加法秘密共享并支持主动安全。
4.5 SMPC 的实现
多年来,出现了多个实用的多方协议实现。例如:
- **Fairplay 系统**:最早的两方和多方计算系统之一,基于 Yao 协议和 BMR 协议。
后续的改进包括:
✅ 效率提升:如使用混淆技术和“cut-and-choose”范式实现主动安全
✅ 大规模并行实现:如 Kreuter 等人实现的在 521 核心集群上的运行
在实际应用方面,也有多个成功案例,例如:
✅ 波士顿女性劳动力委员会报告(2016):原始数据由当地雇主保管,使用 SMPC 完成分析
尽管如此,大规模实际应用仍然有限。一些项目如 SEPIA 和 SCAPI 正在推动实用化发展。
4.6 SMPC 的局限性
由于 SMPC 协议通常使用秘密共享机制,因此需要各参与方之间的通信与连接。这导致:
❌ 通信成本高于明文计算
❌ 协议复杂性带来计算开销:如生成随机数保证安全性
❌ 易受合谋攻击:尽管有更强协议,但通常效率更低
5. FHE 与 SMPC 的应用考量
安全计算是一个历史悠久但仍非常活跃的研究领域。我们已经了解了同态加密和安全多方计算。这些技术已经成熟到可以在生产系统中规模化使用的程度。
虽然它们在基本形式上解决的是安全计算的不同方面,但它们的功能非常相似。事实上,已有尝试将同态加密扩展为支持多密钥以实现多方计算。
也有将这两种技术结合使用的情况,例如:
✅ 将同态加密作为子程序生成相关随机性以辅助多方计算
它们的应用还取决于性能因素:
✅ 在高带宽场景下,多方计算通常优于同态加密
这些技术正被广泛应用于金融和医疗行业,用于外包数据分析。同时也在推动分布式投票、私密竞标和拍卖等新场景的发展。
6. 其他安全计算技术
同态加密和多方计算并不是安全计算领域的唯一技术。还有其他一些服务于特定目的的技术,例如:
- 函数加密(Functional Encryption):允许对加密数据执行特定函数。
- 零知识证明(Zero-knowledge Proof):在不泄露额外信息的情况下证明一个陈述为真。
- 差分隐私(Differential Privacy):在共享数据集统计信息时保护个体隐私。
- 不经意传输(Oblivious Transfer):发送方发送多个信息中的一部分,但不知道接收方获取了哪一部分。
7. 总结
在本教程中,我们讨论了安全计算及其在该领域存在的挑战。我们深入介绍了同态加密和安全多方计算,涵盖了一些可用的协议和实现。
随着数据隐私需求的增加,这些技术正变得越来越重要。尽管存在性能和实用性方面的挑战,但它们正在被越来越多地应用于金融、医疗、选举和竞拍等关键领域。