1. 概述
支持向量机(SVM) 是一种强大的机器学习方法,广泛用于分类 和 回归 任务。在应用SVM解决实际问题时,一个关键决策是选择 间隔(margin) 的类型。本文将深入解析SVM中硬间隔(Hard Margin)和软间隔(Soft Margin)之间的区别。
2. SVM中间隔的作用
假设我们有一组需要分为两类的数据点。这些数据可能是线性可分的,也可能是非线性可分的。当数据是线性可分且我们不希望有任何误分类时,应使用硬间隔SVM。而当线性边界不可行,或我们愿意容忍一些误分类以换取更好的泛化能力时,则应选择软间隔SVM。
2.1. 硬间隔SVM
假设我们用于分类的超平面为:
$$ \pmb{w^T x} + b = 0 $$
如图所示,间隔由两个平行于该超平面的边界构成:
$$ \pmb{w^T x} + \alpha = 0 $$ $$ \pmb{w^T x} + \beta = 0 $$
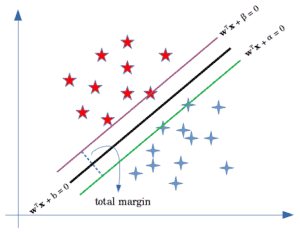
这两个边界分别对应图中的绿色和紫色线。在硬间隔SVM中不允许任何误分类,我们希望最大化这两个边界之间的距离。
通过点到平面的距离公式,可以推导出间隔的总宽度为:
$$ \frac{|\alpha - \beta|}{||\pmb{w}||} $$
为了简化优化问题,我们通常设 $\alpha = b + 1$,$\beta = b - 1$,这样间隔变为:
$$ \frac{2}{||\pmb{w}||} $$
因此,最大化间隔等价于最小化:
$$ \frac{1}{2} ||\pmb{w}||^2 $$
同时满足以下约束:
$$ y_i (\pmb{w}^T \pmb{x}_i + b) \geq 1 $$
这就是SVM的原始优化问题(primal problem),其目标是找到一个全局最优解。
我们可以通过引入拉格朗日乘子 $\alpha_i$ 将其转化为对偶问题(dual problem):
$$ L(\pmb{w}, b, \alpha_i) = \frac{1}{2} \pmb{w^T w} - \sum_{i=1}^{n} \alpha_i (y_i (\pmb{w^T x}_i + b) -1) $$
通过对其求导并代入,最终得到对偶形式:
$$ \mathop{\textnormal{max}}{\pmb{\alpha}} \hspace{1mm} -\frac{1}{2} \sum{i=1}^{n} \sum_{j=1}^{n} \alpha_i \alpha_j y_i y_j x_i^T x_j + \sum_{i=1}^{n} \alpha_i $$
$$ \textbf{s.t.} \hspace{3mm} \sum_{i=1}^{n} \alpha_i y_i = 0 $$
对偶问题的优势在于仅涉及拉格朗日乘子,并且其依赖于训练数据的内积,便于后续扩展到非线性情况。
2.2. 软间隔SVM
软间隔SVM的优化过程与硬间隔类似,但允许部分误分类。为此,我们引入松弛变量 $\zeta_i$ 来衡量误分类的损失,通常使用 hinge loss:
$$ \textnormal{max} {0, 1 - y_i (\pmb{w}^T \pmb{x}_i + b) } $$
软间隔的原始优化问题变为:
$$ \textnormal{min} \hspace{1mm} \frac{1}{2} ||\pmb{w}||^2 + C \sum_{i=1}^{n} \zeta_i $$
$$ \textnormal{\textbf{s.t.}} \hspace{3mm} y_i (\pmb{w}^T \pmb{x}_i + b) \geq 1 - \zeta_i \hspace{4mm} \forall i=1, ..., n, \hspace{1mm} \zeta_i \geq 0 $$
其中,超参数 $C$ 控制最大化间隔与最小化误分类损失之间的权衡。
对应的对偶问题为:
$$ \textnormal{max} \hspace{1mm} -\frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_i \alpha_j y_i y_j x_i^T x_j + \sum_{i=1}^{n} \alpha_i $$
$$ \textbf{s.t.} \hspace{3mm} \sum_{i=1}^{n} \alpha_i y_i = 0, \hspace{2mm} 0 \leq \alpha_i \leq C $$
✅ 注意:相比硬间隔,软间隔对偶问题的唯一区别是拉格朗日乘子 $\alpha_i$ 有上限 $C$。
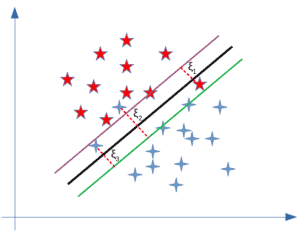
3. 硬间隔 vs. 软间隔:关键区别
- ✅ 数据线性可分时,应使用硬间隔SVM。
- ✅ 数据非线性可分或存在噪声点,应使用软间隔SVM。
- ✅ 即使数据线性可分,但间隔非常小,硬间隔容易过拟合,此时使用软间隔可以提升模型泛化能力。
⚠️ 踩坑提示:不要盲目追求训练集上的完美分类(即硬间隔),这可能导致模型在测试集上表现不佳。
4. 小结
本文介绍了SVM中硬间隔与软间隔的核心区别:
| 项目 | 硬间隔 | 软间隔 |
|---|---|---|
| 数据要求 | 必须线性可分 | 可非线性可分 |
| 误分类 | 不允许 | 允许 |
| 松弛变量 | 无 | 有 |
| 拉格朗日乘子约束 | 无上限 | 上限为 $C$ |
| 模型泛化能力 | 易过拟合 | 更强 |
✅ 选择软间隔通常更安全,尤其在实际数据中存在噪声或非线性关系时。