1. 引言
动态规划(Dynamic Programming,DP)是解决最优化问题的一种常用范式。它通过将原问题拆解为子问题,并逐步求解这些子问题来构建整体最优解。
在实际开发中,我们经常使用两种核心策略来实现动态规划:
- Tabulation(表格法):自底向上构建解
- Memoization(记忆化搜索):自顶向下递归并缓存中间结果
本文将深入解析这两种方法的实现原理、优缺点以及适用场景,帮助你在实际项目中做出更合理的选择。
2. 动态规划基础
动态规划依赖于 Bellman 最优性原理:
原问题的最优解中,包含子问题的最优解。
也就是说,如果我们能将问题拆解为若干子问题,并且这些子问题之间存在重叠,那么就可以使用 DP。
DP 的核心在于:
- 递归结构:问题可以拆解为子问题
- 重叠子问题:不同阶段的子问题有重复
- 状态转移方程:描述子问题之间的关系
3. Tabulation(表格法)
Tabulation 是一种 自底向上 的 DP 实现方式。它从最基础的子问题开始求解,逐步向上构建更复杂的解。
3.1. 示例:最大金币收集路径
假设我们有一个 n x n 的网格,每个格子 (i, j) 中有 c[i][j] 枚金币。我们从 (1,1) 出发,只能向右或向下移动,求到达 (n,n) 时能收集的最大金币数。
示例图:
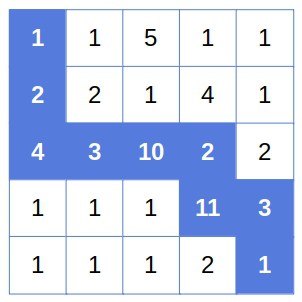
3.2. 状态转移方程
设 Y[i][j] 表示从 (1,1) 到 (i,j) 的最大金币数,则:
Y[i][j] = c[i][j] + max(Y[i-1][j], Y[i][j-1]);
边界条件:
- Y[1][1] = c[1][1]
- Y[1][j] = Y[1][j-1] + c[1][j]
- Y[i][1] = Y[i-1][1] + c[i][1]
3.3. 实现算法(Java)
public static int tabulationMaxCoins(int[][] c, int n) {
int[][] Y = new int[n + 1][n + 1];
Y[1][1] = c[1][1];
// 填充第一行和第一列
for (int j = 2; j <= n; j++) Y[1][j] = Y[1][j - 1] + c[1][j];
for (int i = 2; i <= n; i++) Y[i][1] = Y[i - 1][1] + c[i][1];
// 填充其余格子
for (int k = 2; k <= n; k++) {
for (int i = k; i <= n; i++) {
Y[i][k] = c[i][k] + Math.max(Y[i - 1][k], Y[i][k - 1]);
}
for (int j = k + 1; j <= n; j++) {
Y[k][j] = c[k][j] + Math.max(Y[k][j - 1], Y[k - 1][j]);
}
}
return Y[n][n];
}
3.4. Tabulation 的优缺点
✅ 优点:
- 迭代实现,无栈溢出风险
- 时间复杂度通常为
O(n^2),空间也为O(n^2)
❌ 缺点:
- 需要反向思考递归关系,实现起来不够直观
- 有可能计算了不必要的子问题
4. Memoization(记忆化搜索)
Memoization 是一种 自顶向下 的 DP 实现方式。它结合了递归的直观性与缓存的高效性。
4.1. 示例:带缓存的递归实现
public static int memoizationMaxCoins(int i, int j, int[][] c, int n, int[][] Y) {
if (Y[i][j] != 0) return Y[i][j];
if (i == 1 && j == 1) {
Y[i][j] = c[i][j];
} else if (i == 1) {
Y[i][j] = c[i][j] + memoizationMaxCoins(i, j - 1, c, n, Y);
} else if (j == 1) {
Y[i][j] = c[i][j] + memoizationMaxCoins(i - 1, j, c, n, Y);
} else {
Y[i][j] = c[i][j] + Math.max(
memoizationMaxCoins(i - 1, j, c, n, Y),
memoizationMaxCoins(i, j - 1, c, n, Y)
);
}
return Y[i][j];
}
调用方式:
int[][] Y = new int[n + 1][n + 1];
int result = memoizationMaxCoins(n, n, c, n, Y);
4.2. Memoization 的执行过程
下图展示了递归过程中缓存如何减少重复计算:
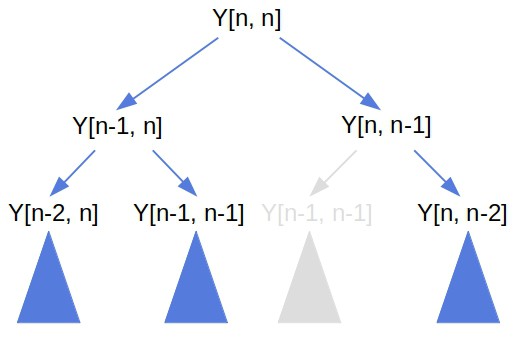
4.3. Memoization 的优缺点
✅ 优点:
- 逻辑清晰,贴近递归定义
- 只计算必要的子问题
❌ 缺点:
- 递归可能导致栈溢出(尤其在大数据量时)
- 缓存结构设计复杂(如哈希函数)
- 不被所有开发者认可为“标准 DP 技术”
5. 总结对比
| 特性 | Tabulation | Memoization |
|---|---|---|
| 实现方式 | 迭代 | 递归 + 缓存 |
| 时间复杂度 | O(n²) | O(n²) |
| 空间复杂度 | O(n²) | O(n²) |
| 优点 | 无栈溢出风险,效率稳定 | 实现直观,逻辑清晰 |
| 缺点 | 实现复杂,可能计算冗余 | 有栈溢出风险,缓存设计复杂 |
| 适用场景 | 数据量大、性能要求高 | 逻辑复杂、需要快速实现 |
6. 选择建议
- ✅ Tabulation 更适合 大规模数据处理,尤其在生产环境中避免栈溢出风险。
- ✅ Memoization 更适合 快速开发 或 逻辑复杂但数据量小 的问题。
两者本质都是动态规划,区别在于实现思路。理解它们的异同,有助于你根据实际场景选择更合适的策略。
💡 踩坑提醒:在使用 Memoization 时,务必注意递归深度。如果数据量较大,建议改用 Tabulation 或使用尾递归优化(如果语言支持)。