1. 简介
当我们开发一个 HTTP API 时,除了设计 URL 路径、资源结构等,认证机制的选择也是一个关键决策点。
本文将介绍几种常见的 API 认证方式,包括它们的实现原理、优缺点,以及适用场景。
2. 传统认证方式
HTTP 协议本身提供了一些基础的认证机制,最常见的是 Basic 认证 和 Digest 认证。
2.1 Basic 认证
原理:客户端将用户名和密码用冒号拼接,再进行 Base64 编码,放在
Authorization请求头中。示例:
- 用户名:
baeldung,密码:superSecret - 拼接:
baeldung:superSecret - Base64 编码:
YmFlbGR1bmc6c3VwZXJTZWNyZXQ= - 请求头:
Authorization: Basic YmFlbGR1bmc6c3VwZXJTZWNyZXQ=
- 用户名:
缺点:
- 密码每次请求都发送,容易被截获
- 不加密,必须配合 HTTPS 使用
2.2 Digest 认证
- 原理:客户端和服务器通过摘要算法交换信息,避免明文传输密码。
- 优点:
- 密码不会直接暴露在网络中
- 缺点:
- 实现复杂
- 服务器必须保留明文密码用于验证
⚠️ 踩坑提醒:Basic 认证虽然简单,但不安全,不建议在生产环境使用,除非配合 HTTPS。
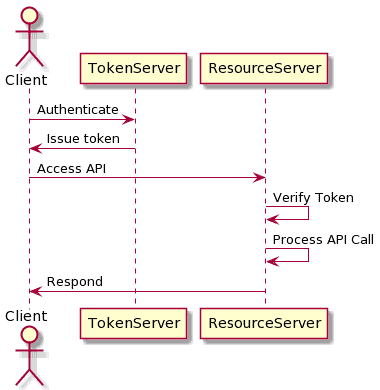
3. Token 认证
Token 认证是一种常见的现代认证方式,核心思想是:客户端首次认证后获得一个 Token,在后续请求中携带该 Token 即可完成身份验证。
3.1 Token 的优势
- 安全性更高:避免每次请求都传输用户名和密码
- 可控性强:Token 可设置过期时间、权限范围等
- 支持分布式:多个服务共享验证机制,无需统一登录中心
3.2 Token 类型
- 简单 Token:服务端维护 Token 映射表(如 Redis)
- **JWT (JSON Web Token)**:自包含 Token,包含用户信息和签名,无需查询数据库
3.3 Token 生命周期管理
- Token 通常有有效期(如 1 小时),防止长期泄露
- 支持刷新 Token(Refresh Token),延长访问权限
- Token 必须保证不可预测性,避免使用自增 ID,建议使用 UUID 或加密生成
3.4 Token 的验证机制
- JWT 可通过数字签名验证(如 HMAC、RSA)
- 多服务间共享签名密钥或使用公钥验证签名
✅ 优点:
- 支持跨服务认证
- 更适合前后端分离架构
- 易于实现无状态 API
❌ 缺点:
- Token 一旦签发,无法立即吊销
- 刷新 Token 机制复杂,需额外管理
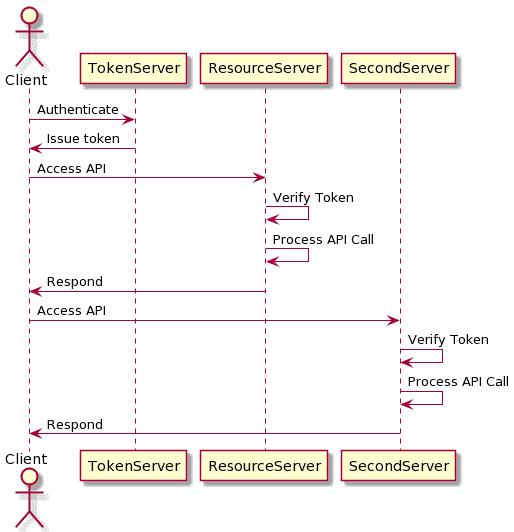
✅ 推荐方案:使用 OAuth2 + JWT 的组合,是目前主流的认证方式。
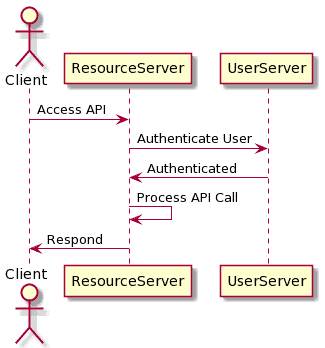
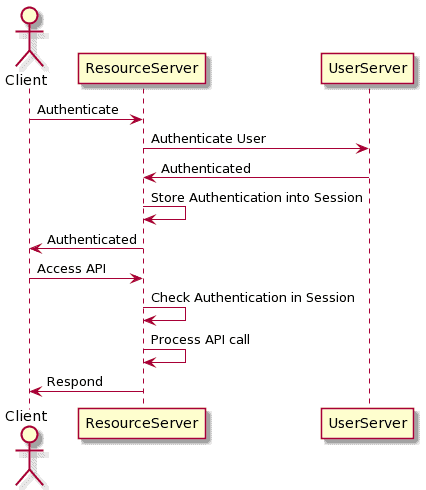
4. Session 认证
Session 是许多 Web 容器(如 Tomcat)内置的认证机制,适用于传统的 Web 应用,但在 API 场景中使用有限。
4.1 原理
- 用户登录后,服务端生成一个 Session ID,存储用户信息
- Session ID 通常通过 Cookie 传输
- 后续请求携带 Session ID,服务器根据 ID 查找用户信息
4.2 Session 的生命周期
- Session 通常依赖于浏览器会话或超时时间
- 服务端控制 Session 的创建、销毁、过期
- 支持主动登出(Logout)
4.3 Session 的缺点
- 需要 Session 存储(如内存、Redis),对集群环境不友好
- 多节点部署时需配置 Session 共享
- 不适合移动端或前后端分离架构
- Session ID 通过 Cookie 传递,容易受到 CSRF 攻击
⚠️ 踩坑提醒:Session 认证在前后端分离场景中维护成本高,建议优先考虑 Token。
5. 总结与建议
| 认证方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Basic Auth | 简单,易实现 | 明文传输,不安全 | 内部测试或开发环境 |
| Digest Auth | 密码不传输,安全性略高 | 实现复杂 | 旧系统兼容或特定场景 |
| Token (JWT) | 无状态,支持分布式,易于扩展 | 无法立即吊销 | 前后端分离、移动端、微服务架构 |
| Session | 容器支持好,适合传统 Web 应用 | 集群部署复杂,不适合 API 场景 | 传统 Web 应用(如 JSP、Thymeleaf) |
✅ 推荐做法:
- API 服务优先使用 Token(推荐 JWT + OAuth2)
- Web 应用可使用 Session,但需注意安全性和集群部署
- 多服务间认证建议使用统一认证中心(如 Keycloak、Auth0)
✅ 总结:Token 认证是当前主流趋势,Session 适合传统 Web 场景,但不适合现代 API 架构。选择合适的认证方式可以提升系统安全性、可扩展性和维护性。