1. 简介
在本篇文章中,我们将深入探讨迁移学习(Transfer Learning)与领域自适应(Domain Adaptation)之间的区别与联系。
迁移学习是一个广泛的概念,指的是将一个机器学习任务中获得的知识,迁移到另一个任务中。而领域自适应则是迁移学习的一种特殊情况,它主要关注数据分布的变化。
2. 经典监督学习
为了更好地理解迁移学习,我们先回顾一下经典监督学习的结构。
我们以一个猫狗图像分类任务为例。在监督学习中,我们从原始数据集  中提取特征 ,然后为其分配标签 。例如一张图像中包含狗的脚、脸、身体等特征,我们将其标记为“狗”。
模型训练完成后,我们将其部署到实际应用中,面对的是一个不同但相似的数据集,比如同样是猫狗图片,但可能来自不同角度、不同光照条件。
下图展示了监督学习中两个数据集  与  的关系:
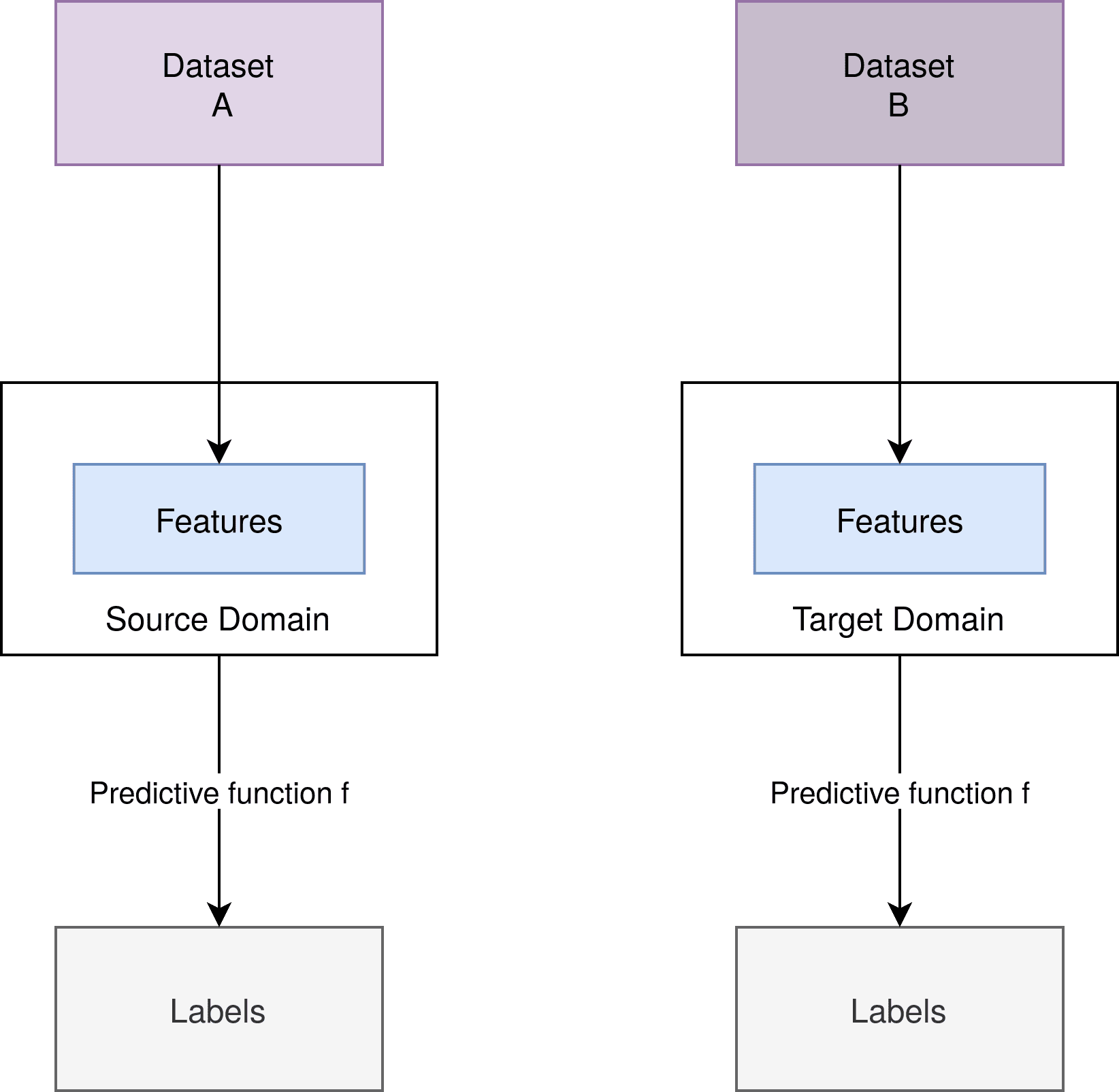
我们可以看到,特征提取方式和预测函数  在训练和部署阶段保持一致。
3. 迁移学习
迁移学习是一种机器学习技术,其基本结构与监督学习相似,但允许源任务和目标任务之间在数据、特征、标签甚至模型结构上有较大差异。
3.1. 迁移学习架构
迁移学习的基本结构如下图所示:
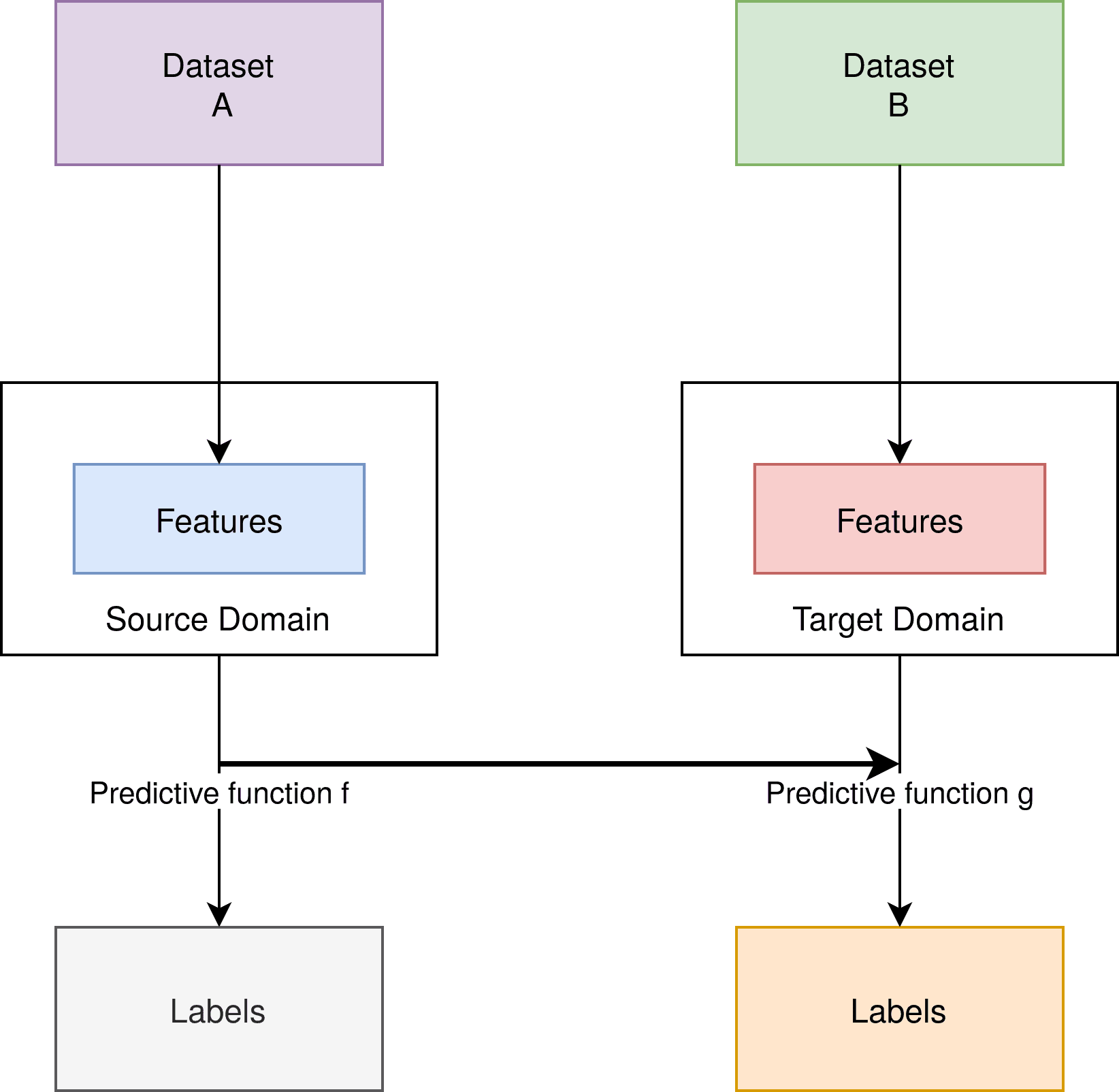
可以看到,源任务和目标任务之间的关键联系在于预测函数  与  的关系。通常,我们会利用  的一部分来构建 。
迁移学习涵盖了多种情况:
- 数据不同,特征不同,标签不同
- 数据不同,特征相同,标签不同
- 数据不同,特征不同,标签相同
3.2. 示例:图像分类任务
以猫狗分类模型为例,假设我们现在想识别牛和马的图片。
虽然牛马与猫狗差异很大,但它们都是哺乳动物,具有相似的轮廓结构。我们可以将源模型中用于提取轮廓的层“冻结(freeze)”,并将其作为新模型的一部分使用:
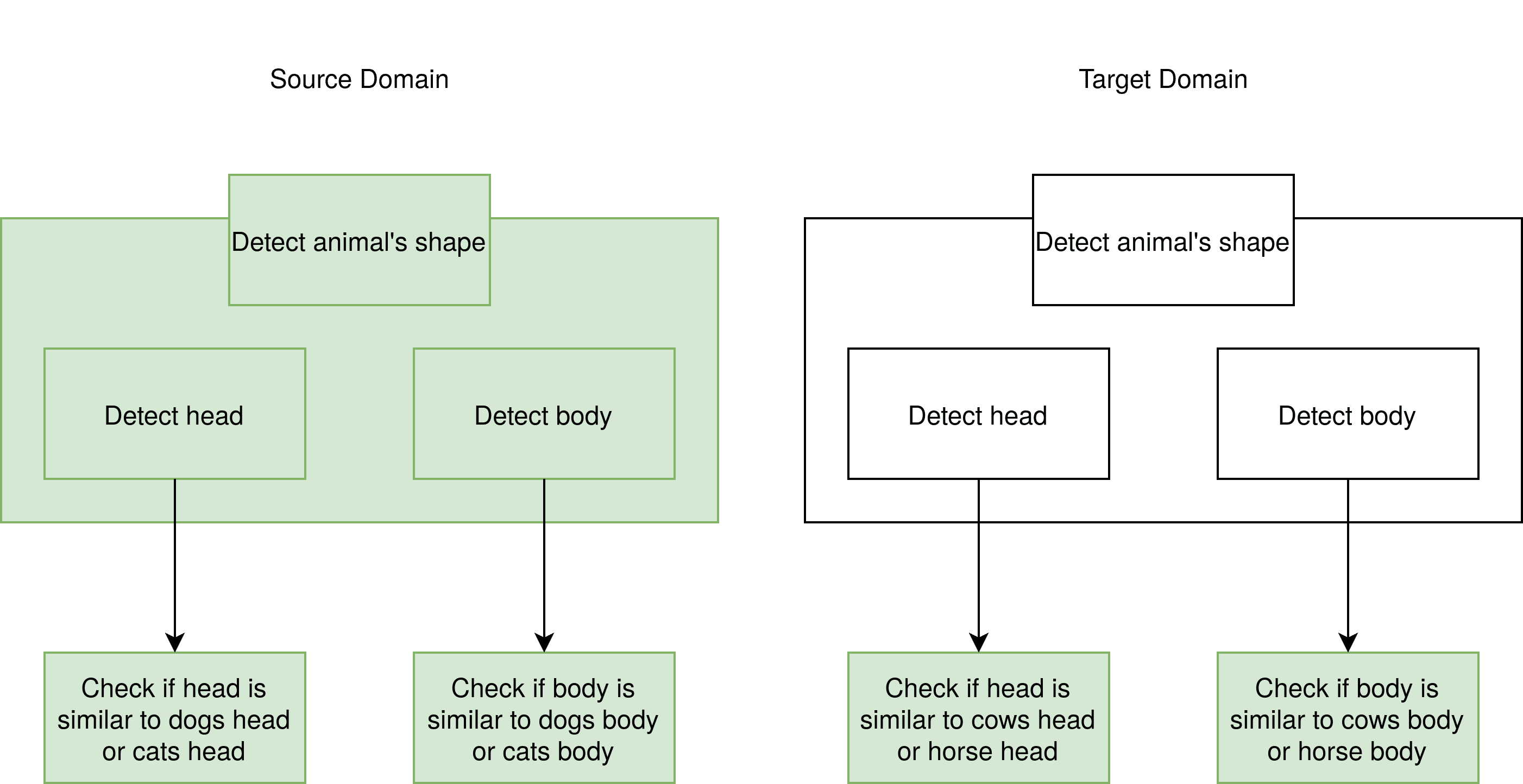
图中绿色部分表示需要训练的层,灰色部分为冻结层。冻结层在训练过程中不会被更新,仅用于提取通用特征。
✅ 踩坑提醒:迁移学习中,冻结层的选择非常关键。太浅的层提取的是边缘等低级特征,可能不够泛化;太深的层则可能过度依赖源任务的语义信息。
4. 领域自适应
领域自适应是迁移学习的一个子集,其核心在于仅改变数据分布(领域),保持特征空间和标签空间一致。
4.1. 架构示意
领域自适应的结构如下图所示:
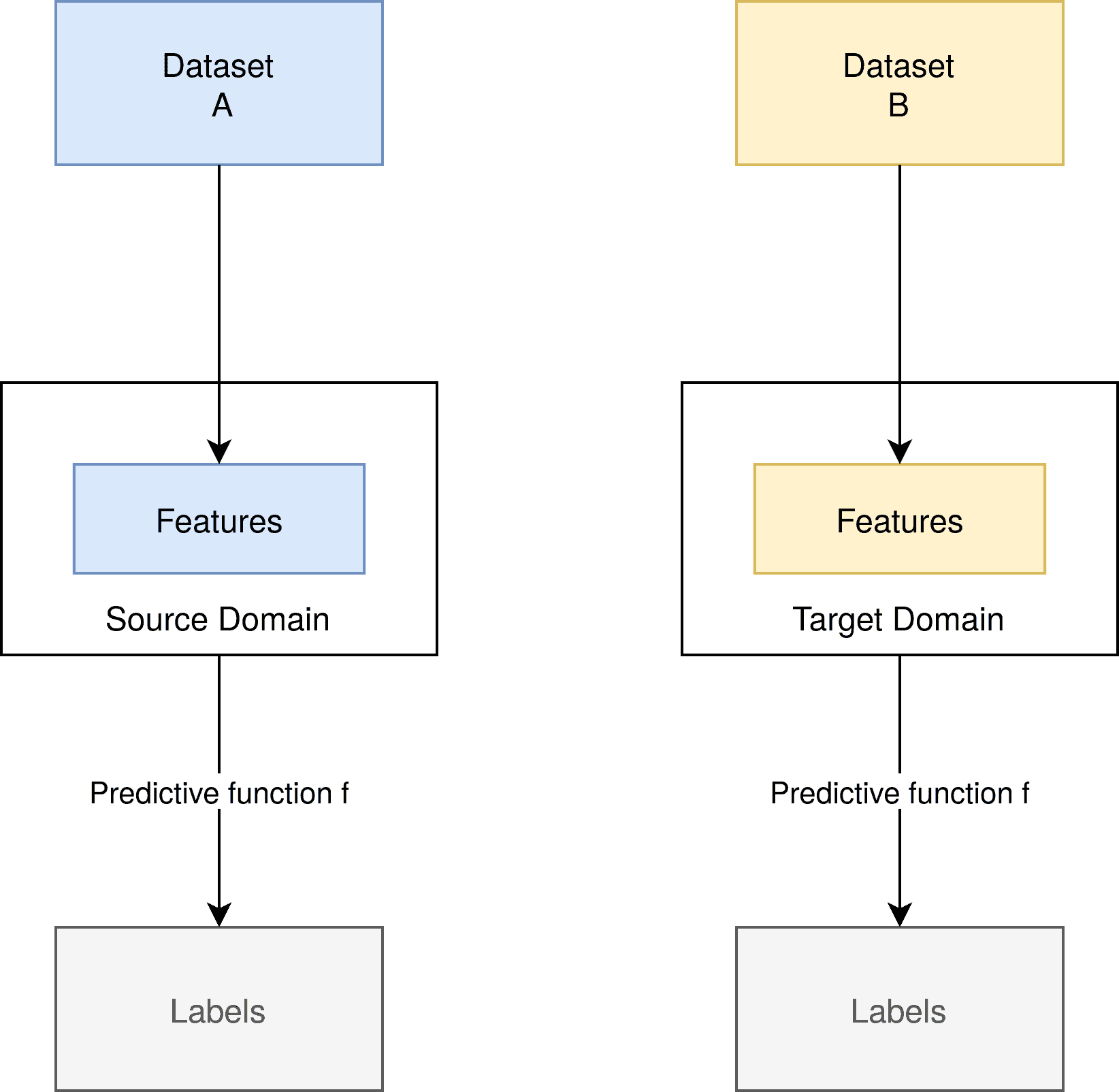
可以看到,源域和目标域的特征空间相同,预测函数  保持不变,但数据分布不同。
4.2. 应用场景
例如,源域中我们只有贵宾犬和黑猫的图像,而目标域中则是雪纳瑞犬和白猫的图像。
虽然两类图像都属于猫狗类别,但颜色、体型等特征有较大差异。领域自适应的目标就是让模型在目标域上依然保持良好表现。
4.3. 类型划分
根据目标域中标签的可用情况,领域自适应可以分为三类:
- ✅ 无监督领域自适应(Unsupervised Domain Adaptation):目标域无标签
- ✅ 半监督领域自适应(Semi-supervised Domain Adaptation):目标域部分有标签
- ✅ 监督领域自适应(Supervised Domain Adaptation):目标域全部有标签
5. 领域自适应方法
由于领域自适应仅改变数据分布,因此我们可以通过以下方法来优化模型表现。
5.1. 基于分布差异的方法(Divergence-based)
这类方法的核心思想是:让模型学习到在源域和目标域都表现良好的特征表示。
常用技术包括:
- ✅ Maximum Mean Discrepancy (MMD)
- ✅ Correlation Alignment (CORAL)
- ✅ Contrastive Domain Discrepancy
- ✅ Wasserstein Metric
这些方法的目标是最小化两个领域之间的分布差异,从而提升模型在目标域上的泛化能力。
5.2. 迭代方法(Iterative Approach)
迭代方法的基本思路是:
- 使用源域模型对目标域样本进行预测;
- 对置信度高的样本打标签;
- 用这些样本重新训练模型;
- 逐步加入置信度较低的样本。
这种方法通过逐步提升模型对目标域的理解,从而实现更好的自适应效果。
📚 参考论文:https://arxiv.org/abs/2001.04129
6. 总结
迁移学习为我们提供了一种高效的方法,将已有模型的知识迁移到新任务中。而领域自适应作为其子集,专门解决数据分布变化带来的挑战。
在实际应用中,我们经常遇到训练数据与实际数据分布不一致的问题。此时,使用基于分布差异或迭代的方法,可以有效提升模型表现。
✅ 总结要点:
| 概念 | 是否改变数据 | 是否改变特征 | 是否改变标签 | 是否改变模型结构 |
|---|---|---|---|---|
| 迁移学习 | ✅ | ✅ | ✅ | ✅ |
| 领域自适应 | ✅ | ❌ | ❌ | ❌ |
⚠️ 关键区别:领域自适应只改变数据分布,其余保持一致;而迁移学习可以改变更多维度。
迁移学习和领域自适应是当前深度学习研究的重要方向,尤其在跨领域任务、小样本学习等场景中具有广泛的应用前景。