1. 概述
在本文中,我们将讲解计算机视觉中的两个常见概念:平移不变性(Translation Invariance) 与 平移协变性(Translation Equivariance)。
我们会先回顾“平移”的数学定义,然后通过图示和例子,详细解释这两个概念之间的区别。最后我们还会结合卷积神经网络(CNN)说明它们在实际应用中的意义。
2. 什么是平移?
平移是一种几何变换,它将图像中所有点沿相同方向移动相同距离。也可以理解为将坐标系的原点反方向移动相同距离。
数学上,平移可以表示为:
$$ T_{\mathbf{v}} (\mathbf{x}) = \mathbf{x} + \mathbf{v} $$
其中,$\mathbf{x}$ 是原始点,$\mathbf{v}$ 是平移向量。
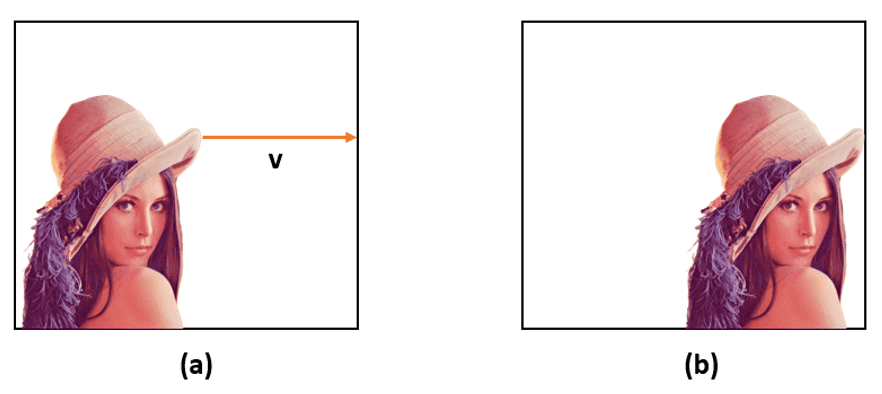
举个例子,下图中图像 (b) 是图像 (a) 中每个像素向左移动 150 像素后得到的:
3. 平移不变性(Translation Invariance)
一个属性如果是平移不变的,意味着它在图像平移后不会发生变化。
以图像识别为例,无论目标出现在图像哪个位置,我们都应该能正确识别出它的类别。比如,下图中无论人脸在左边还是中间,我们都应识别出“人”的类别。因此,图像分类器的输出就应具有平移不变性。
下面是一个形象的示意图,展示了图像分类器的平移不变性:
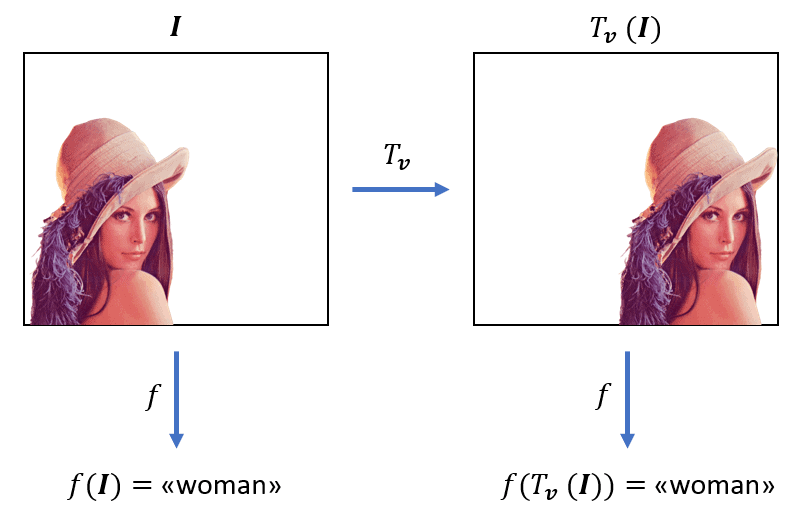
✅ 重点:分类器输出不变,即使输入图像被平移。
4. 平移协变性(Translation Equivariance)
平移协变性常与平移不变性混淆,它们的定义有本质区别。
数学定义:
函数 $f$ 对变换 $g$ 是协变的,当且仅当:
$$ f(g(x)) = g(f(x)) $$
即:先对输入做变换再经过函数处理,等价于先用函数处理再对输出做变换。
举个例子:卷积操作
卷积操作具有平移协变性。例如:
- 如果我们对图像 $\mathbf{I}$ 先做平移 $T_{\mathbf{v}}$,再进行卷积操作,得到的特征图是 $f(T_{\mathbf{v}}(\mathbf{I}))$
- 如果我们先卷积再平移,结果是 $T_{\mathbf{v}}(f(\mathbf{I}))$
这两种方式的结果是相同的。
下图形象展示了卷积操作的平移协变性:
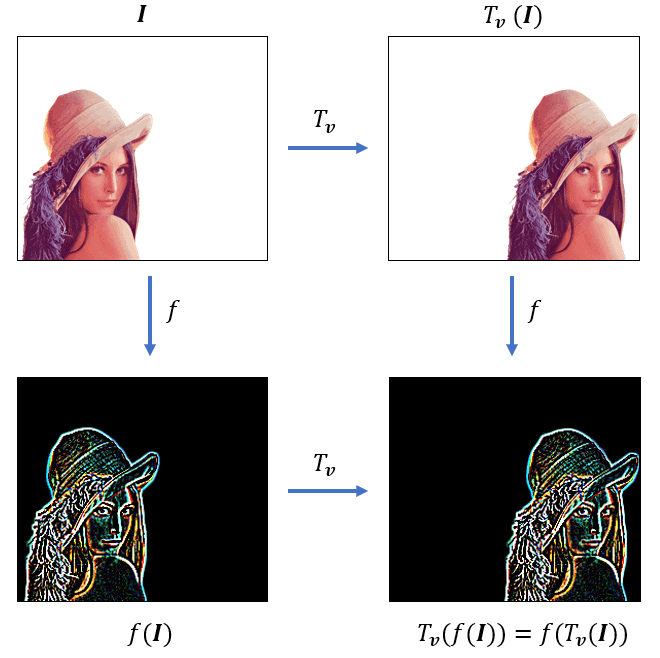
✅ 重点:输入平移 → 输出特征图也平移,但内容保持一致。
5. CNN 中的平移不变性与协变性
在卷积神经网络(CNN)中,平移不变性 和 平移协变性 是两个关键特性:
✅ 协变性来自卷积层
卷积层具有平移协变性。图像中某个区域的特征被检测到后,即使图像整体平移,特征图中该特征也会以相同方式平移。
✅ 不变性来自池化层(Pooling)
CNN 中的池化操作(如最大池化)会“模糊”特征位置,保留其存在性。这样,即使目标位置发生变化,最终分类结果仍能保持不变。
举个例子:
- 卷积层提取特征,保留位置信息(协变)
- 池化层压缩特征图,丢失具体位置(不变)
⚠️ 注意:CNN 不具备旋转、缩放、仿射等变换的不变性或协变性
因此,为了增强模型对这些变换的鲁棒性,通常需要使用数据增强(Data Augmentation)。
6. 小结
| 概念 | 定义 | 示例 | 在 CNN 中的表现 |
|---|---|---|---|
| 平移不变性 | 输入平移后输出不变 | 图像分类器输出“人”,无论人脸在图像中哪个位置 | 由池化层实现 |
| 平移协变性 | 输入平移后输出也平移 | 卷积特征图随输入图像平移而平移 | 由卷积层实现 |
✅ 总结:
- 卷积层负责保留位置信息(协变)
- 池化层负责提取抽象特征(不变)
- 两者结合使得 CNN 在图像分类任务中表现优异