1. 概述
本文将探讨树结构在实际场景中的应用,包括游戏开发、数据库索引以及机器学习等领域的具体案例。
我们会介绍树结构如何帮助解决这些领域中的核心问题,例如提升性能、减少计算复杂度、优化数据组织方式等。
2. 树结构简介
树 是一种经典的抽象数据结构,用于表示层次化的数据关系。它由一个根节点(root)开始,每个节点可以拥有多个子节点,形成一个树状结构。
树结构在计算机科学中无处不在。很多算法都基于树实现,而这些算法通常具有 **对数级的时间复杂度(O(log n))**,效率非常高:
3. 游戏开发中的树结构
在 3D 游戏中,玩家控制的角色(avatar)需要与虚拟世界中的其他物体进行交互,比如碰撞检测。随着场景中物体数量的增加,直接对所有物体进行碰撞检测将变得非常低效。
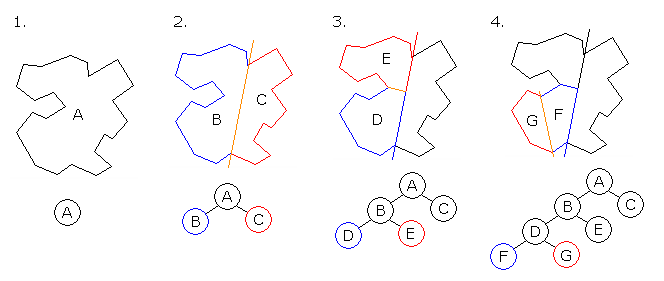
为了解决这个问题,游戏开发中通常使用 空间划分树结构(space partitioning trees) 来优化性能。
原理
- 递归划分空间:将整个空间不断细分为更小的区域,直到达到最小单元(cell)。
- 每个叶子节点代表一个区域,并记录该区域中包含的物体。
- 碰撞检测只需检查角色所在区域及其相邻区域的物体。
常见类型
- Quadtree(四叉树):适用于二维空间划分。
- Octree(八叉树):适用于三维空间划分。
这种结构极大地减少了需要检查的物体数量,从而实现实时碰撞检测:
4. 数据库中的树结构
数据库是现代应用的核心组件。随着数据量的增长,如何高效地存储和检索数据成为关键问题。
背景
传统的存储设备(如机械硬盘)访问速度较慢,无法支持频繁的全表扫描。因此,数据库引入了 索引机制,以实现快速查找。
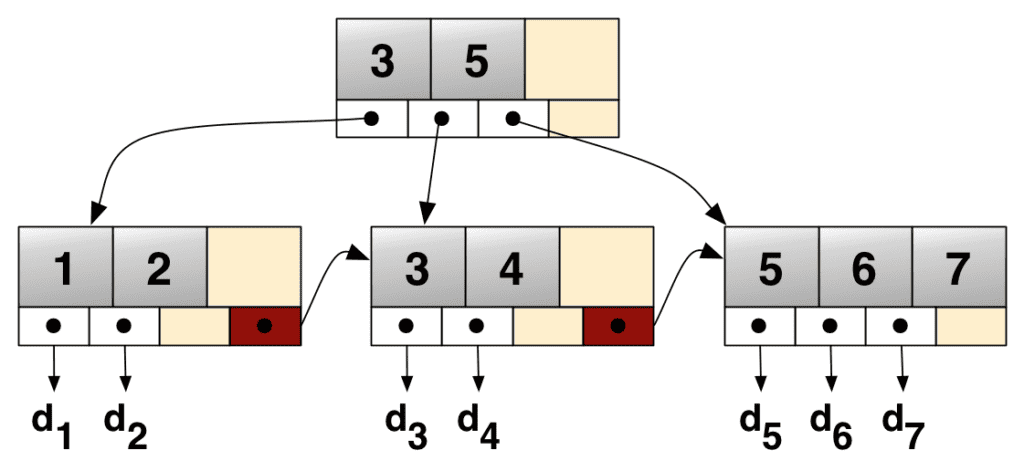
B+ 树的作用
数据库索引通常基于 B+ 树(B+ Tree) 实现:
- B+ 树是一种多路平衡搜索树,适合磁盘存储。
- 它将键值划分为多个区间,每层树节点对应一个区间划分。
- 叶子节点包含指向实际数据块的指针。
- 叶子节点之间通过指针相连,便于范围查询。
查询流程
- 从根节点开始,根据查询键值向下查找。
- 找到对应的叶子节点后,通过指针定位到磁盘上的数据块。
- 加载数据并返回。
虽然实际实现中会更复杂,但 B+ 树构成了数据库索引的核心基础:
5. 机器学习中的树结构
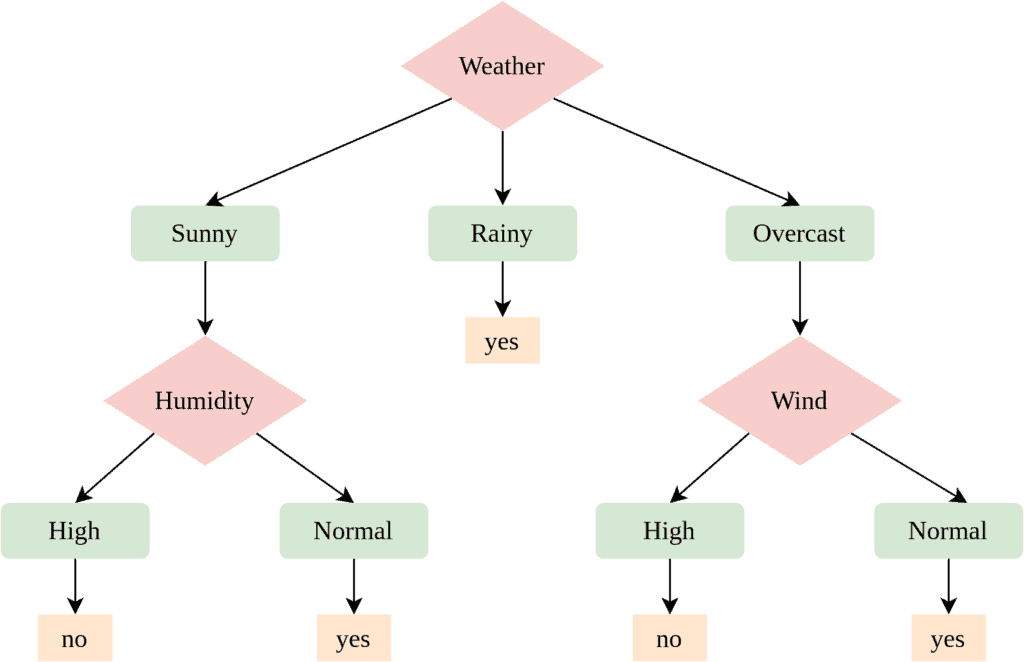
在机器学习中,决策树(Decision Tree) 是一种基础但非常实用的模型。
特点
- 决策树本身是模型的核心,而非辅助结构。
- 每个节点表示一个属性判断。
- 每个分支表示该属性的一个取值。
- 叶子节点表示最终决策结果。
使用场景
- 分类任务(如判断邮件是否为垃圾邮件)
- 回归任务(如预测房价)
- 决策分析(如选择最优策略)
示例
给定一组属性(如年龄、收入、信用评分),决策树通过判断这些属性值,最终输出一个决策(如是否批准贷款):
6. 总结
本文通过几个实际案例展示了树结构在现实世界中的重要性:
✅ 游戏开发中使用空间划分树优化碰撞检测
✅ 数据库使用 B+ 树实现高效的索引机制
✅ 决策树是机器学习中的核心模型之一
这些应用只是树结构众多用途中的一小部分。树结构不仅理论基础扎实,而且在工程实践中也极具价值。希望本文能激发你对树结构的兴趣,进一步探索其更多应用场景。