1. Overview
Unique and sortable identifiers are crucial in modern software for various purposes. The ability to lexicographically sort unique identifiers enhances efficiency in indexing, searching, and managing data.
In this tutorial, we’ll discuss universally unique lexicographically sortable identifiers (ULIDs).
2. ULID
ULID is a specification for generating unique and lexicographically sortable 128-bit identifiers. As a result, the generated identifiers can be used in many cases where sorting is important.
For example, ULIDs can be used as database keys where guaranteed ordering allows for efficient indexing and sharding. Additionally, we can use ULIDs as identifiers in distributed systems for better tracing. Furthermore, we can also use them as transaction and event-sourcing identifiers, which, due to the timestamp component, makes them easier to track, validate, and audit.
Unlike UUIDs, which are typically generated using pseudo-random or time-based algorithms, ULIDs combine time-based components with randomness to achieve uniqueness while preserving the ability to be sorted lexicographically.
3. Understanding ULID
ULID uses 128-bit for generating the identifier. It’s a combination of two separate parts. The first 48 bits represent the timestamp, and the remaining 80 bits are for randomness. The timestamp component uses a UNIX timestamp in milliseconds, while a cryptographically secure random method generates the randomness:
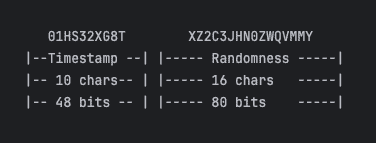
The timestamp bits are encoded into ten characters, while the randomness component is represented by 16 characters using Crockford’s base32 algorithm. This configuration results in a total length of 26 characters for the ULID.
4. Sorting ULIDs
ULIDs are designed so that their lexicographic order reflects their creation order (up to the millisecond) since the first 48 bits are based on the timestamp. ULID-induced ordering is also monotonic since each new identifier comes after the previous one, maintaining a clear progression.
This feature allows for efficient sorting without additional processing overhead.
4.1. Conflict Resolution
In some instances, multiple identifiers can be generated within the same millisecond. The random component can affect the sequential order of identifiers. To address this issue, the ULID specification outlines a method for preventing conflicts.
If an identifier shares the same timestamp as its predecessor, the random component of the previous identifier is incremented by 1 to produce a new random part. Subsequent identifier generation within the same millisecond does the same. Consequently, the identifiers generated within the same millisecond will always maintain a lexicographically higher position than its predecessor, ensuring the preservation of order:
algorithm ULID_generation(current_ulid):
// INPUT
// current_ulid = the most recently generated ULID
// OUTPUT
// Returns the ULID that will follow current_ulid
// in the lexicographic order and avoid conflicts.
// Check for a conflict
if current_ulid.timestamp = current_timestamp():
new_ulid <- increment the least significant bit of the current ULID by 1
return new_ulid
else:
// No conflict, proceed with normal ULID generation
return generate_new_ulid()
4.2. Example
Let’s take a look at two ULIDs generated one after another in the same millisecond:
01BX5ZZKBKACTAV9WEVGEMMVS0
01BX5ZZKBKACTAV9WEVGEMMVS1
The last bit of the second identifier is incremented by 1, so the new ULID preserves the sorting order.
It’s important to note that in the improbable event of generating more than 2^80 ULIDs within the same millisecond, an overflow may occur, resulting in errors during the generation process.
5. Advantages and Disadvantages
ULIDs provide several advantages as random identifiers:
- Efficient lexicographical and chronological sorting of generated identifiers without any additional processing
- Compact and readable representation using 26 characters without any special characters
- Case-insensitive and avoids similar-looking characters using Crockford encoding
However, ULIDs do come with a few disadvantages in some instances:
- The randomness component may weaken when multiple identifiers are generated within the same millisecond, as the least significant bit (LSB) increment may not provide enough variance
- Limited adoption and less support compared to more established identifiers
- Dependency on timestamps could pose challenges when obtaining accurate timestamps, which is problematic
5.1. Comparison with UUID
Despite UUID and ULID utilizing 128 bits for identification purposes, their representations have significant differences.
UUID typically has 36 characters, while ULID requires only 26 characters. Additionally, UUID lacks sorting capability, making it inefficient in scenarios where sorting is crucial for optimal performance, such as database keys.
6. Python Example
ULID is a specification for generating sortable and unique identifiers. This specification is implemented in various languages such as Java, Scala, Python, Javascript, and so on.
Let’s look at how to generate ULIDs in Python. First, we install the Python library for ULIDs:
pip install ulid-py
Now, let’s use this library to generate ULIDs:
import time
from ulid import monotonic as ulid
ulid.new() //<ULID('01HS38K796GE4K1TVJVY8NB2PS')>
We can also verify the generated ULIDs within the same millisecond to preserve their order:
import time
from ulid import monotonic as ulid
ts = time.time()
ulid.from_timestamp(ts) // <ULID('01HS38H3DVGE4K1TVJVY8NB2PV')>
ulid.from_timestamp(ts) // <ULID('01HS38H3DVGE4K1TVJVY8NB2PW')>
The only difference between the two ULIDs is in their least significant bit.
7. Conclusion
In this article, we delved into ULID and its capability to generate lexicographically sortable identifiers, showcasing its efficiency and superiority over UUIDs in various scenarios. We also demonstrated the generation of ULIDs using a Python library.
ULID is not just a standalone concept; it’s a specification implemented across different programming languages. Some implementations may offer additional features beyond the original specification. For instance, certain implementations provide microsecond-based conflict resolution for identifiers generated within the same millisecond, enhancing robustness in distributed systems.