1. 优化问题概述
优化问题在实际中非常常见,其核心在于 在一定约束条件下,找到一组输入,使得输出达到最优值。
比如经典的旅行商问题(TSP),目标是给定一系列城市和距离,找出最短路径。这类问题广泛存在于物流、路径规划、机器学习等领域。
我们可以用一个简单的数学模型来理解优化过程,比如:
$$ P(x, y) = 4x + 3y \hspace{5 mm} | \hspace{5 mm} 2x + 4y \leq 220, 3x + 2y \leq 150, x \geq 0, y \geq 0 $$
这个函数叫做目标函数,我们希望在满足约束条件的前提下,最大化或最小化它。这类问题通常属于线性规划(Linear Programming)或二次规划(Quadratic Programming)范畴。
其中,凸函数(Convex Function) 是优化中非常重要的概念:
- 如果函数图像上任意两点连线在函数图像之上,则该函数为凸函数。
- 凸函数只有一个全局最优解,这使得优化变得简单。
- 非凸函数可能有多个局部最优解,难以找到全局最优。
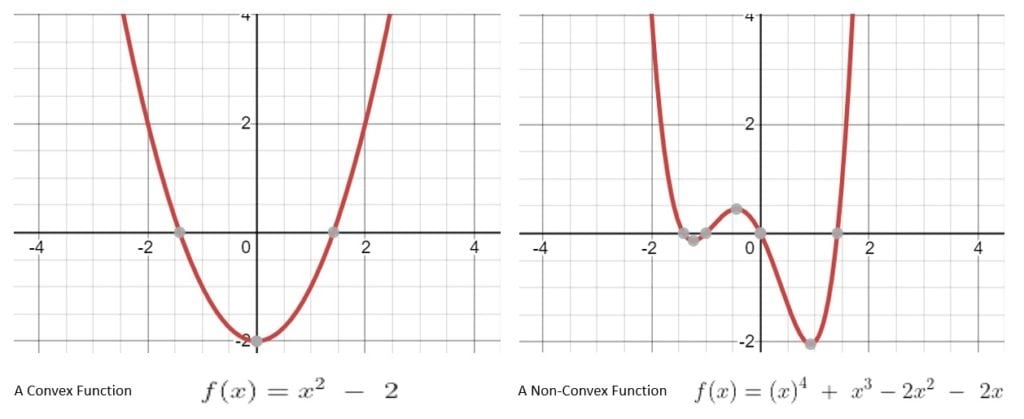
✅ 小结:
- 凸函数 = 单一最优解,易求解
- 非凸函数 = 多个局部解,难求解
2. 线性回归简介
线性回归是一种统计方法,用于建立 一个因变量(响应变量)与一个或多个自变量(解释变量)之间的线性关系。
例如,我们可以用线性回归来建模降雨量与温度、湿度、海拔之间的关系。
其数学形式非常简洁:
$$ Y = a + bX $$
其中:
- $ Y $:因变量(预测目标)
- $ X $:自变量(输入特征)
- $ a $:截距
- $ b $:斜率
我们的目标是通过训练数据学习出最优的 $ a $ 和 $ b $,使得模型预测值尽可能接近真实值。
2.1 最小二乘法(Least Squares Method)
这是线性回归中最常用的优化策略。我们定义一个损失函数(Cost Function)来衡量预测值与真实值之间的误差:
$$ J(a, b) = \frac{1}{2m} \sum_{i=1}^{m}(f_{(a,b)}(x^{i})-y^{i})^{2} $$
目标是找到使 $ J(a, b) $ 最小的 $ a $ 和 $ b $。
3. 损失函数的求解
最小二乘法的损失函数是一个 二次函数,因此求解它本质上是一个 二次规划问题。
对于简单的二次函数,我们可以使用解析法(如求导后解方程)求解最优解:
$$ \text{Max. } f(x) = \left(\frac{x}{5}\right)^2 + 5 \quad \text{subject to } f(x) < x + 10 $$
将其转化为方程:
$$ x^2 - 25x - 125 = 0 $$
然后求解即可。
但现实问题中,我们通常面对的是 多个变量的复杂模型,这时解析法变得不可行,必须使用数值方法或迭代算法。
4. 梯度下降算法(Gradient Descent)
梯度下降是一种 迭代优化算法,用于寻找函数的最小值。它广泛应用于机器学习中,尤其是在线性回归中求解最小二乘损失函数。
4.1 基本思想
我们从一组随机的参数开始,不断调整它们,使损失函数值下降。调整的方向由损失函数对参数的偏导数决定。
更新公式如下:
$$ \theta_j = \theta_j - \alpha \frac{\partial}{\partial \theta_j} J(\theta) $$
其中:
- $ \theta_j $:第 $ j $ 个参数
- $ \alpha $:学习率(Learning Rate)
- $ \frac{\partial}{\partial \theta_j} J(\theta) $:损失函数对参数 $ \theta_j $ 的偏导数
偏导数告诉我们,在当前参数值下,损失函数的变化率。我们沿着“下降”方向更新参数,逐步逼近最小值。
4.2 图解说明
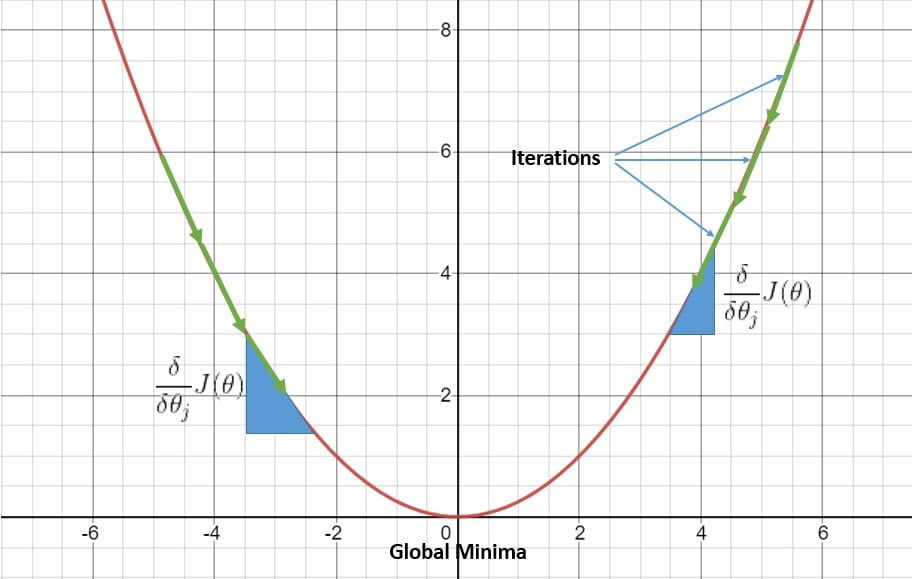
梯度下降的过程就像在山间下坡,每一步都朝着最陡峭的方向走,最终到达谷底(最小值)。
5. 为什么梯度下降有效?
5.1 损失函数是凸函数
在最小二乘法中,损失函数是一个 凸函数,这意味着:
- 它只有一个最小值(全局最优)
- 梯度下降一定能找到这个最小值
✅ 优点:
- 适用于多变量模型
- 实现简单,扩展性强
❌ 缺点:
- 学习率选择不当会导致收敛慢或不收敛
- 对非凸函数容易陷入局部最优
5.2 学习率(Learning Rate)的选择
学习率是梯度下降中最重要的超参数之一:
- 太大:步子迈得太大,可能跳过最小值
- 太小:收敛慢,效率低
⚠️ 踩坑提醒:
学习率不能随意设置,建议使用学习率衰减(Learning Rate Decay)或者自适应方法(如 Adam)来提升效果。
6. 总结
本文我们从优化问题出发,介绍了线性回归的基本概念和最小二乘法的目标函数。
接着我们讨论了如何使用梯度下降算法来求解线性回归中的参数,并分析了其有效的原因:
- 损失函数是凸函数 → 保证全局最优
- 梯度下降是迭代方法 → 适合高维问题
- 学习率选择至关重要 → 影响收敛速度和稳定性
✅ 梯度下降是机器学习中最基础、最核心的优化算法之一,理解其背后的数学原理和直觉,有助于我们在实际项目中更好地调参和优化模型。