1. 概述
在本教程中,我们将学习如何将均匀分布转换为正态分布。
首先,我们会简要回顾一下两种分布的区别。
然后,我们会学习一种算法——Box-Muller 变换,该算法可以通过从均匀分布中采样来生成正态分布的伪随机数。
本教程结束时,你将掌握如何构建一个输出正态分布值的伪随机数生成器。
2. 均匀分布与正态分布
讨论的第一步是理解均匀分布和正态分布在形态和特性上的差异。这有助于我们了解为何需要进行转换,以及如何实现转换。
2.1 均匀分布
均匀分布(Uniform Distribution)也被称为矩形分布,其概率密度函数(PDF)形状如矩形所示:

在任意连续区间 [a, b] 上(包括或不包括端点),我们可以定义一个均匀分布 U(a, b)。该分布的特性是:在区间内任意长度相等的子区间上,出现的概率都相同,即:
$$ P(\epsilon) = \frac{1}{b - a} $$
我们可以通过计算曲线下的面积来验证这是一个合法的概率密度函数:
$$ Pr[a \leq x \leq b] = \int_a^b \text{PDF}(x) dx = (b - a) \times \frac{1}{b - a} = 1 $$
2.2 正态分布
正态分布(Normal Distribution)的概率密度函数如下所示:
$$ \text{PDF}(x|\sigma, \mu) = \frac{1}{\sigma \sqrt{2\pi}} \times e^{-\frac{1}{2} \left( \frac{x - \mu}{\sigma} \right)^2} $$
其中,$\sigma$ 表示标准差,$\mu$ 表示均值。以下是一个标准正态分布($\sigma=1, \mu=0$)的图形:

可以观察到,正态分布中的值并不是等概率出现的。这与均匀分布有显著区别。
造成这种差异的原因有两个:
✅ 第一:均匀分布中具有非零概率的值只出现在一个有限区间内,而正态分布的值则覆盖整个实数域 $(-\infty, \infty)$。
✅ 第二:在离散均匀分布中,所有值的出现概率相同;而在正态分布中,任意两个不同值的出现概率几乎总是不同的,除非它们关于均值对称。
3. Box-Muller 变换
3.1 算法定义
我们可以使用一种算法将均匀分布的值转换为正态分布的值。其中最简单且常用的算法是 Box-Muller 变换。
该算法适用于伪随机数生成,实现简单且效果良好。
算法步骤如下:
- 从标准均匀分布 $U(0,1)$ 中抽取两个独立样本 $u_1$ 和 $u_2$
- 使用以下公式生成两个独立的标准正态分布随机变量 $z_1$ 和 $z_2$:
$$ z_1 = \sqrt{-2 \ln(u_1)} \cos(2 \pi u_2) $$ $$ z_2 = \sqrt{-2 \ln(u_1)} \sin(2 \pi u_2) $$
这两个变量 $z_1$ 和 $z_2$ 都服从标准正态分布 $N(0,1)$。
3.2 实验验证
我们可以对这个过程进行实证验证。
具体做法是:绘制从均匀分布 $u_1, u_2$ 中采样的二维分布直方图,并将其与经过 Box-Muller 转换后的分布进行对比。
以下是两个大小为 10,000 的样本转换后的结果:
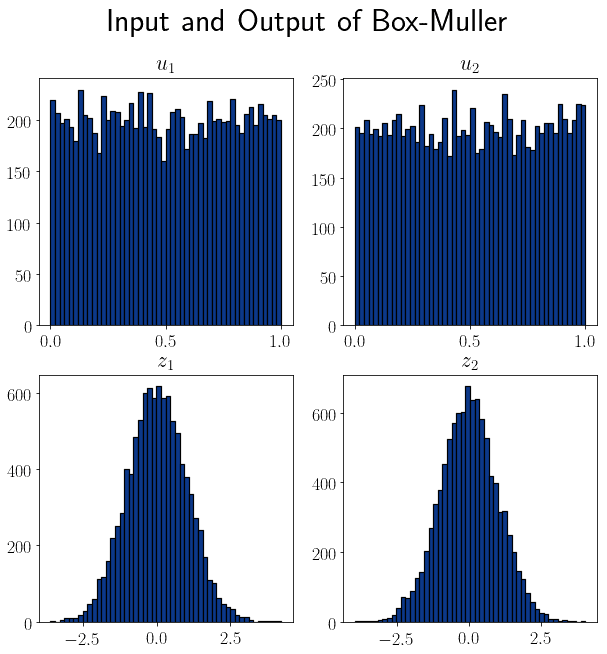
可以看到,转换后的分布呈现出高斯分布的钟形曲线,说明算法有效。
3.3 推导过程
理解这个变换的原理可以从几何角度入手。
设想将 $u_1$ 和 $u_2$ 视为笛卡尔坐标系中的两个坐标点:

我们可以将该点转换为极坐标表示,得到一个角度 $\theta$ 和一个距离原点的距离 $r$。
在二维正态分布中,该点的模长 $r$ 对应:
$$ r = \sqrt{-2 \ln u_1} $$
而角度 $\theta$ 则对应:
$$ \theta = 2 \pi u_2 $$
因此,我们可以将原来的笛卡尔坐标点转换为正态分布的变量:
$$ z_1 = r \cos(\theta) $$ $$ z_2 = r \sin(\theta) $$
这两个表达式与我们前面给出的 Box-Muller 公式是等价的。
3.4 Box-Muller 的局限性
尽管 Box-Muller 变换实现简单,但在某些场景下存在局限性:
❌ 精度限制:计算机在表示浮点数时存在精度限制。例如,在 32 位精度下,生成的正态分布值最多只能达到约 6.5 个标准差;在 64 位精度下,约为 9.5 个标准差。
❌ 尾部截断:由于均匀分布中不能取到非常接近于 0 的值,Box-Muller 无法生成极端尾部的值。这可能导致生成的正态分布“尾巴”被截断。
✅ 适用场景:适用于生成中等长度的正态分布序列,若需生成大量极端值,应考虑其他算法。
3.5 替代方案
如果需要克服 Box-Muller 的限制,可以考虑以下替代算法:
- Ziggurat 算法:使用拒绝采样原理,通过查找表和随机种子生成正态分布值,效率较高。
- Ratio-of-Uniforms 算法:需要存储一些双精度浮点数,但计算速度快且实现简单。
- 分位函数法(Inverse Transform Sampling):通过计算正态分布的累积分布函数(CDF)的反函数来生成正态分布值,这在标准正态分布中即为 probit 函数。
这些方法在某些特定场景下优于 Box-Muller,但实现复杂度也更高。
4. 总结
在本教程中,我们学习了如何将均匀分布转换为正态分布。
我们首先回顾了两种分布的定义和区别,然后介绍了 Box-Muller 变换算法,通过该算法可以从两个均匀分布的样本生成两个独立的正态分布变量。
我们还讨论了该算法的局限性,并列举了其他替代方案。
最终,你现在已经掌握了生成正态分布伪随机数的基本方法,可以在实际项目中加以应用。