1. 概述
在本篇教程中,我们将回顾 Viola-Jones 算法,这是用于物体检测的一种经典机器学习方法。我们会从原理出发,简明扼要地解释其核心思想,帮助你快速掌握这一算法的关键点。
该算法由 Paul Viola 和 Michael Jones 于 2001 年提出,论文名为 “Rapid object detection using a boosted cascade of simple features”。虽然它在精度上不如现代基于 CNN 的方法,但在资源受限的设备上依然具有很高的实用价值。
2. Viola-Jones 算法简介
✅ Viola-Jones 算法是一种用于物体检测的机器学习方法,最初主要用于人脸检测。其核心思想是通过分析图像中多个不同位置和大小的窗口,提取特定特征来判断窗口中是否包含目标物体。
该算法基于以下四个关键技术:
- Haar-like 特征:用于描述图像局部区域的纹理信息
- 积分图(Integral Image):加速特征计算
- AdaBoost 学习算法:从大量特征中选出最优特征组合
- 级联分类器(Cascade of Classifiers):快速过滤非目标区域,提高检测效率
接下来我们将逐一解析这些关键技术。
3. Haar-Like 特征
✅ Viola-Jones 使用的特征类似于 Haar 小波(Haar wavelets),但更简单,是一组矩形形状的特征模板。主要使用以下三种基本特征:
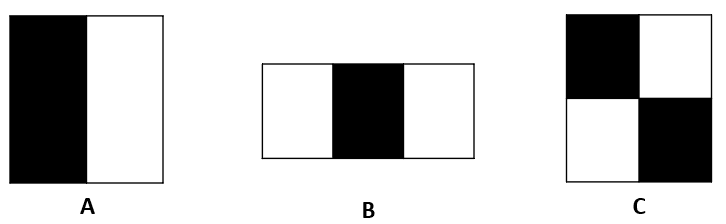
每个特征由一个或多个矩形区域组成,通常分为“白”和“黑”两个部分。特征值为白色区域像素值总和减去黑色区域像素值总和。
- 如果区域是“平坦”的(所有像素值相近),特征值接近于 0
- 如果黑白区域差异大,特征值也会很大
这些特征在人脸检测中非常有效,比如:
- 眼睛区域比脸颊暗
- 眼睛比鼻子区域暗
因此,特征 A 和 B 能很好地帮助识别面部关键部位。
4. 积分图(Integral Image)
✅ 积分图是一种用于快速计算图像区域内像素和的数据结构。它使得 Haar-like 特征的计算变得高效。
设原图是灰度图像 $ I $,积分图像中任意一点 $ ii(x, y) $ 表示以原图左上角 (0,0) 到当前点 (x,y) 所围成矩形区域的像素和:
$$ ii(x, y) = \sum_{\substack{x' \leq x \ y' \leq y}} I(x', y') $$
积分图可以通过一次遍历快速构建,计算公式如下:
$$ ii(x, y) = I(x, y) + ii(x, y-1) + ii(x-1, y) - ii(x-1, y-1) $$
✅ **对于一张包含 n 个像素的图像,积分图的构建时间复杂度为 O(n)**。
一旦有了积分图,任意矩形区域的像素和都可以通过四个点的积分图值快速得到:
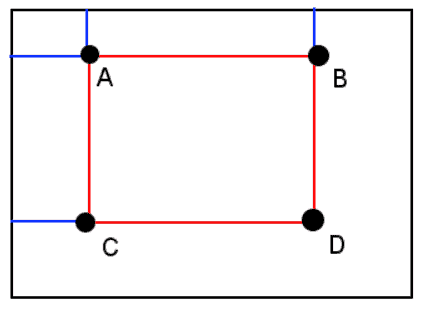
如图所示,矩形 ABCD 的像素和为:
$$ \sum_{\substack{x_0 < x \leq x_1 \ y_0 < y \leq y_1}} I(x, y) = ii(D) + ii(A) - ii(B) - ii(C) $$
✅ 因此,Haar-like 特征的计算时间复杂度可达到 O(1),与窗口大小无关。
5. AdaBoost 学习算法
✅ Viola-Jones 使用 AdaBoost 算法进行特征选择和分类器训练。
在 24×24 的图像窗口中,Haar-like 特征数量可达约 160,000 个,但其中真正有用的特征只占少数。AdaBoost 的作用就是从中挑选出最优特征,并将它们组合成一个强分类器。
- 每个 Haar-like 特征被视为一个弱分类器
- AdaBoost 为每个弱分类器分配一个权重,权重越大表示该分类器越可靠
- 最终分类器是这些弱分类器的加权线性组合
这种方式使得分类器在保持高精度的同时,还能兼顾效率。
6. 注意力级联(Attentional Cascade)
✅ 注意力级联是 Viola-Jones 算法中用于加速检测过程的核心机制之一。
其思想是:
- 先使用最有效的分类器(由 AdaBoost 选出)对窗口进行判断
- 若判断为负样本(非人脸),立即丢弃该窗口
- 若判断为正样本,继续使用更复杂的分类器进一步判断
这样可以在早期阶段就过滤掉大量非目标窗口,只有极少数窗口需要通过全部分类器,从而大幅提高检测速度。
结构如下图所示:
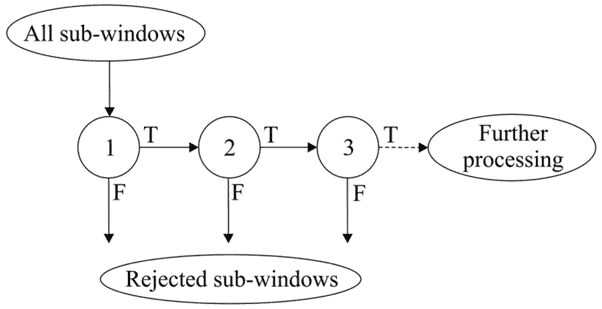
⚠️ 注意:这种级联结构的关键在于“早期拒绝”机制。设计时要确保每一级都能快速过滤大量负样本,同时保留几乎所有正样本。
7. 总结
本篇我们系统讲解了 Viola-Jones 算法的四个核心思想:
| 核心技术 | 作用 |
|---|---|
| Haar-like 特征 | 提取图像局部特征 |
| 积分图 | 加速特征计算 |
| AdaBoost | 选择最优特征并组合成强分类器 |
| 级联分类器 | 快速过滤非目标区域,提高效率 |
虽然 Viola-Jones 算法在精度上已被现代 CNN 模型超越,但由于其实现简单、计算效率高,在嵌入式设备或对实时性要求较高的场景中仍有应用价值。
如果你在实际项目中遇到性能瓶颈,或者想快速实现一个轻量级人脸检测器,Viola-Jones 仍然是一个值得考虑的方案。