1. 简介
在本文中,我们将探讨 Web Crawling(网络爬行)与 Web Scraping(网络抓取)这两个常被混淆但又密切相关的概念。它们都是数据挖掘中的重要技术,广泛应用于互联网数据的获取与分析。
我们将从定义入手,逐步介绍它们的工作流程、核心区别,以及各自的优缺点和实际应用场景。对于有经验的开发者来说,理解这些概念不仅有助于技术选型,也能在实际项目中避免踩坑。
2. Web Crawling 与 Web Scraping 的定义
Web Crawling(网络爬行)
Web Crawling 是指通过程序自动访问并索引网页内容的过程。搜索引擎如 Google、Bing 使用爬虫来扫描整个互联网,建立网页索引,以便在用户搜索时快速返回结果。
✅ 目标:理解网页内容、构建索引
✅ 典型工具:Googlebot、Bingbot
Web Scraping(网络抓取)
Web Scraping 是指从网页中提取特定结构化数据的过程。它可以是手动的,但更多时候是通过自动化工具完成的,比如 Python 的 BeautifulSoup、Scrapy 或 Java 的 Jsoup。
✅ 目标:提取结构化数据(如 JSON、CSV、数据库)
✅ 典型用途:价格监控、舆情分析、数据聚合
3. Web Crawling 与 Web Scraping 的流程对比
3.1 Web Crawling 流程
Web Crawler 会从初始 URL 开始,不断发现新链接并进行访问、分析和索引。其流程可概括为以下四个步骤:
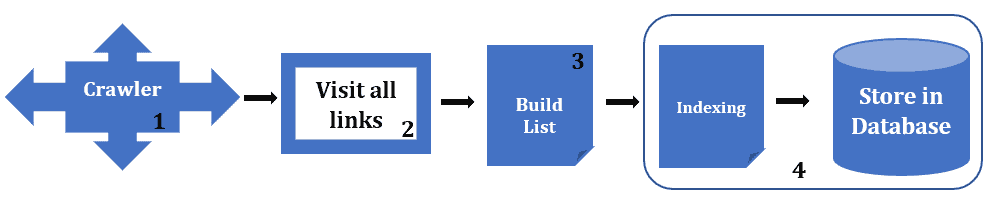
- 从爬行队列中取出 URL
- 访问该 URL 对应的页面
- 分析页面内容并分类
- 将页面内容索引后存入数据库
⚠️ 注意:爬虫在访问页面时会发现新链接,并将其加入队列,形成递归爬取机制。
3.2 Web Scraping 流程
Web Scraper 的目标更明确,通常只针对特定页面提取所需数据。流程如下:
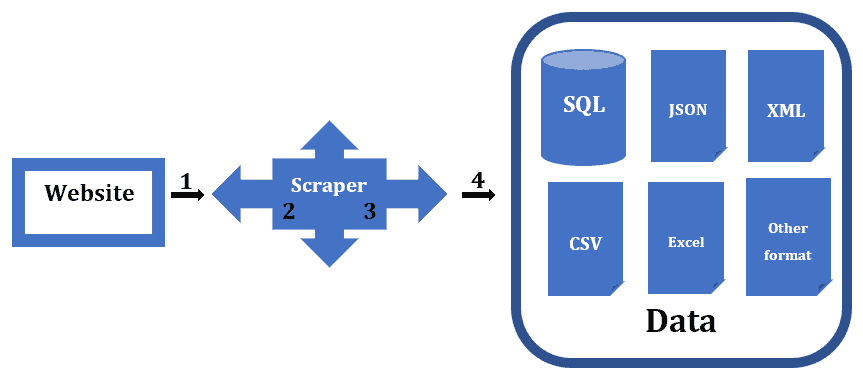
- 向目标网站发送请求
- 获取 HTML 页面内容
- 解析 HTML 并提取目标数据
- 将提取的数据保存为结构化格式(如 JSON、CSV、Excel)
✅ 示例代码(使用 Java Jsoup):
Document doc = Jsoup.connect("https://example.com").get();
Elements prices = doc.select(".price-class");
for (Element price : prices) {
System.out.println(price.text());
}
4. Web Crawling 与 Web Scraping 的主要区别
| 特性 | Web Scraping | Web Crawling |
|---|---|---|
| 目标 | 提取特定数据 | 索引整个网站 |
| 涉及内容 | 编写提取逻辑 | 遍历链接结构 |
| 使用场景 | 数据分析、监控 | 搜索引擎、内容聚合 |
⚠️ 常见误区:很多人把两者混为一谈,其实它们是目的不同但技术上可以结合使用的技术。
5. 优缺点对比
Web Scraping 的优缺点
✅ 优点:
- 支持大规模数据提取
- 成本低、自动化程度高
- 支持多种输出格式(JSON、CSV、数据库)
❌ 缺点:
- 需要持续维护(页面结构变化)
- 易被反爬机制识别
- 初学者有一定学习门槛
Web Crawling 的优缺点
✅ 优点:
- 可自动收集网站内容
- 提高搜索引擎收录效率
- 可用于用户行为分析
❌ 缺点:
- 数据结构不统一
- 占用带宽资源
- 需要处理反爬策略
6. 实际应用场景
Web Crawling 的典型用途
- ✅ 搜索引擎索引网页内容(如 Googlebot)
- ✅ 网站 SEO 优化分析
- ✅ 用户行为追踪与日志分析
Web Scraping 的典型用途
- ✅ 零售行业价格监控与比价系统
- ✅ 股票市场数据采集与分析
- ✅ 自动化生成潜在客户名单(Lead Generation)
✅ 案例说明:
某电商平台使用 Web Scraping 技术,自动抓取竞争对手商品价格和库存信息,实现动态定价策略,从而提升市场竞争力。
7. 总结
| 项目 | Web Crawling | Web Scraping |
|---|---|---|
| 核心目标 | 理解网页结构、建立索引 | 提取结构化数据 |
| 技术重点 | 链接遍历、索引构建 | 数据解析、格式化 |
| 常用工具 | Apache Nutch、Heritrix | Scrapy、Jsoup、BeautifulSoup |
✅ 一句话总结:
Web Crawling 是“理解网页”,Web Scraping 是“提取数据”,二者在实际开发中经常结合使用,但目标和方法截然不同。
对于高级 Java 开发者来说,掌握这两种技术不仅能提升数据处理能力,还能在构建自动化系统时提供强大支持。