1. 简介
本文将使用 deeplearning4j(简称 dl4j)库构建一个简单的神经网络——这是一个现代化且强大的机器学习工具。
在开始之前,请注意本指南不要求你具备线性代数、统计学、机器学习理论等深度知识(这些是专业 ML 工程师必备的)。
2. 什么是深度学习?
神经网络是由互连节点层组成的计算模型。节点是类似神经元的数值数据处理器,它们从输入端接收数据,应用权重和函数处理,然后将结果输出到输出端。这类网络可以通过源数据样本进行训练。
训练本质上是将数值状态(权重)保存到节点中,这些权重后续会影响计算过程。训练样本可能包含带有特征的数据项及其已知类别(例如:“这组 16×16 像素包含手写字母 'a'”)。
训练完成后,神经网络能从新数据中提取信息,即使它从未见过这些特定数据项。一个建模良好且训练有素的网络可以识别图像、手写字母、语音,处理统计数据以生成商业智能结果等。
随着高性能和并行计算的发展,深度神经网络近年来成为可能。这类网络与简单神经网络的区别在于:它们包含多个中间层(或隐藏层)。这种结构使网络能以更复杂的方式(递归、循环、卷积等)处理数据,并从中提取更多信息。
3. 项目搭建
使用该库至少需要 Java 7。此外,由于包含一些原生组件,它仅支持 64 位 JVM。
开始前,先检查环境是否满足要求:
$ java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
首先,在 Maven 的 pom.xml 中添加所需依赖。我们将库版本提取到属性中(最新版本可查阅 Maven Central):
<properties>
<dl4j.version>0.9.1</dl4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native-platform</artifactId>
<version>${dl4j.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>${dl4j.version}</version>
</dependency>
</dependencies>
注意:nd4j-native-platform 是多个可用实现之一。它依赖适用于多平台(macOS、Windows、Linux、Android 等)的原生库。如果想在支持 CUDA 的显卡上执行计算,也可切换到 nd4j-cuda-8.0-platform 后端。
4. 数据准备
4.1. 准备数据集文件
我们将编写机器学习的“Hello World”——鸢尾花数据集分类。该数据集收集自不同品种的鸢尾花(Iris setosa、Iris versicolor 和 Iris virginica)。
这些品种的花瓣和萼片长度/宽度不同。编写精确算法来分类输入数据项(即判断特定花朵所属品种)很困难,但训练有素的神经网络可以快速且低错误率地完成分类。
我们将使用该数据的 CSV 版本,其中 0-3 列包含品种特征,第 4 列包含记录类别(品种),用 0、1 或 2 编码:
5.1,3.5,1.4,0.2,0
4.9,3.0,1.4,0.2,0
4.7,3.2,1.3,0.2,0
…
7.0,3.2,4.7,1.4,1
6.4,3.2,4.5,1.5,1
6.9,3.1,4.9,1.5,1
…
4.2. 数据向量化与读取
我们用数字编码类别,因为神经网络处理数值数据。将真实世界数据项转换为数值序列(向量)的过程称为向量化——deeplearning4j 使用 datavec 库实现。
首先,用该库读取向量化数据文件。创建 CSVRecordReader 时,可指定跳过的行数(如文件有标题行)和分隔符(本例为逗号):
try (RecordReader recordReader = new CSVRecordReader(0, ',')) {
recordReader.initialize(new FileSplit(
new ClassPathResource("iris.txt").getFile()));
// …
}
遍历记录时,可使用 DataSetIterator 接口的多种实现。数据集可能很大,分页或缓存功能会很有用。
但我们的数据集仅 150 条记录,因此用 iterator.next() 一次性读入内存。
我们还需指定类别列索引(本例等于特征数 4)和总类别数(3)。
⚠️ 注意:必须打乱数据集以消除原始文件中的类别顺序。
我们使用固定随机种子(42)而非默认的 *System.currentTimeMillis()*,确保每次运行程序打乱结果一致,从而获得稳定结果:
DataSetIterator iterator = new RecordReaderDataSetIterator(
recordReader, 150, FEATURES_COUNT, CLASSES_COUNT);
DataSet allData = iterator.next();
allData.shuffle(42);
4.3. 归一化与数据分割
训练前还需对数据归一化。归一化是两阶段过程:
- 收集数据统计信息(拟合)
- 以某种方式转换数据使其统一(变换)
不同类型数据的归一化方式可能不同。
例如处理不同尺寸的图像时,需先收集尺寸统计信息,再将图像缩放到统一尺寸。
但对数值数据,归一化通常指转换为正态分布。NormalizerStandardize 类可帮我们实现:
DataNormalization normalizer = new NormalizerStandardize();
normalizer.fit(allData);
normalizer.transform(allData);
数据准备就绪后,需将其分为两部分:
- 第一部分用于训练
- 第二部分(网络完全未见过的数据)用于测试训练后的网络
这能验证分类是否正确。我们取 65% 数据(0.65)训练,剩余 35% 测试:
SplitTestAndTrain testAndTrain = allData.splitTestAndTrain(0.65);
DataSet trainingData = testAndTrain.getTrain();
DataSet testData = testAndTrain.getTest();
5. 网络配置准备
5.1. 流式配置构建器
现在用酷炫的流式构建器构建网络配置:
MultiLayerConfiguration configuration
= new NeuralNetConfiguration.Builder()
.iterations(1000)
.activation(Activation.TANH)
.weightInit(WeightInit.XAVIER)
.learningRate(0.1)
.regularization(true).l2(0.0001)
.list()
.layer(0, new DenseLayer.Builder().nIn(FEATURES_COUNT).nOut(3).build())
.layer(1, new DenseLayer.Builder().nIn(3).nOut(3).build())
.layer(2, new OutputLayer.Builder(
LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.activation(Activation.SOFTMAX)
.nIn(3).nOut(CLASSES_COUNT).build())
.backprop(true).pretrain(false)
.build();
即使这种简化的流式构建方式,仍有很多参数需要理解与调整。我们来拆解这个模型。
5.2. 设置网络参数
iterations() 方法指定优化迭代次数。
迭代优化指在训练集上执行多次传递,直到网络收敛到良好结果。
通常在真实大数据集上训练时,我们会使用多个周期(完整数据传递)和每周期一次迭代。但初始数据集极小,因此我们使用单周期和多迭代。
activation() 是节点内运行的函数,用于确定输出。
最简单的激活函数是线性函数 f(x) = x,但实践证明只有非线性函数才能让网络用少量节点解决复杂任务。
org.nd4j.linalg.activations.Activation 枚举提供了多种激活函数,必要时也可自定义。这里我们使用双曲正切(tanh)函数。
weightInit() 指定网络初始权重的设置方式。正确的初始权重会显著影响训练结果。不深入数学细节,我们选择高斯分布形式(WeightInit.XAVIER),这通常是不错的起点。
其他权重初始化方法可在 org.deeplearning4j.nn.weights.WeightInit 枚举中查找。
学习率是影响网络学习能力的关键参数。
在复杂场景中,我们可能需要大量时间调整此参数。但本任务中,我们直接使用较大的值 0.1,通过 learningRate() 方法设置。
训练神经网络的一个常见问题是过拟合——即网络“死记硬背”训练数据。
当网络为训练数据设置过高权重,导致在其他数据上表现糟糕时,就会发生这种情况。
为解决此问题,我们设置 l2 正则化:*.regularization(true).l2(0.0001)*。正则化通过“惩罚”过大权重防止过拟合。
5.3. 构建网络层
接下来,我们构建密集层(也称全连接层)网络:
- 第一层节点数应与训练数据列数相同(4)
- 第二密集层包含 3 个节点(可调整,但需与前层输出数匹配)
- 最终输出层节点数需匹配类别数(3)
网络结构如下图所示:
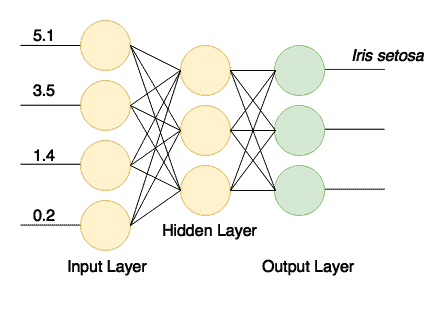
训练成功后,我们将得到一个接收 4 个输入值、向 3 个输出之一发送信号的分类器。
最后,通过 *.backprop(true).pretrain(false)* 设置反向传播(最有效的训练方法之一)并禁用预训练。
6. 创建与训练网络
现在根据配置创建神经网络,初始化并运行:
MultiLayerNetwork model = new MultiLayerNetwork(configuration);
model.init();
model.fit(trainingData);
用剩余数据测试训练好的模型,并通过三类评估指标验证结果:
INDArray output = model.output(testData.getFeatureMatrix());
Evaluation eval = new Evaluation(3);
eval.eval(testData.getLabels(), output);
打印 eval.stats() 会发现,网络在鸢尾花分类上表现良好,仅将 3 个类别 1 误判为类别 2:
Examples labeled as 0 classified by model as 0: 19 times
Examples labeled as 1 classified by model as 1: 16 times
Examples labeled as 1 classified by model as 2: 3 times
Examples labeled as 2 classified by model as 2: 15 times
==========================Scores========================================
# of classes: 3
Accuracy: 0.9434
Precision: 0.9444
Recall: 0.9474
F1 Score: 0.9411
Precision, recall & F1: macro-averaged (equally weighted avg. of 3 classes)
========================================================================
流式配置构建器让我们能快速添加/修改网络层或调整参数,尝试优化模型。
7. 总结
本文使用 deeplearning4j 库构建了一个简单但强大的神经网络。
本文源码可在 GitHub 获取。