1. 概述
在微服务架构盛行的现代软件开发中,追踪和分析跨服务请求的流向至关重要。分布式追踪因此成为关键工具,能帮我们洞察系统性能和行为。
本教程将介绍 Brave —— Java 生态中主流的分布式追踪埋点库。
2. 理解分布式追踪
分布式追踪 是一种监控和排查由互联服务构成的复杂分布式系统的方法。在这种系统中,请求可能穿越多个服务,每个服务负责特定任务。若没有专用工具,追踪请求的完整路径会变得异常困难。
深入分布式追踪前,需先明确两个核心概念:追踪(trace) 和 跨度(span)。追踪代表一个外部请求,由一组跨度构成。跨度代表一个操作,其关键属性包含操作名称、开始时间和结束时间。一个跨度可包含一个或多个子跨度,表示嵌套操作。
接下来看分布式追踪的核心组件:埋点库和追踪服务器。每个服务使用的埋点库主要负责生成和传播追踪数据,包括捕获服务内的操作细节(如处理入站请求、调用其他服务/数据库、数据处理等)。
而追踪服务器则是追踪数据管理的中央枢纽,它提供 API 接收埋点库的数据,聚合存储后支持分析、监控和故障排查。
下图展示了分布式追踪的工作原理及组件交互: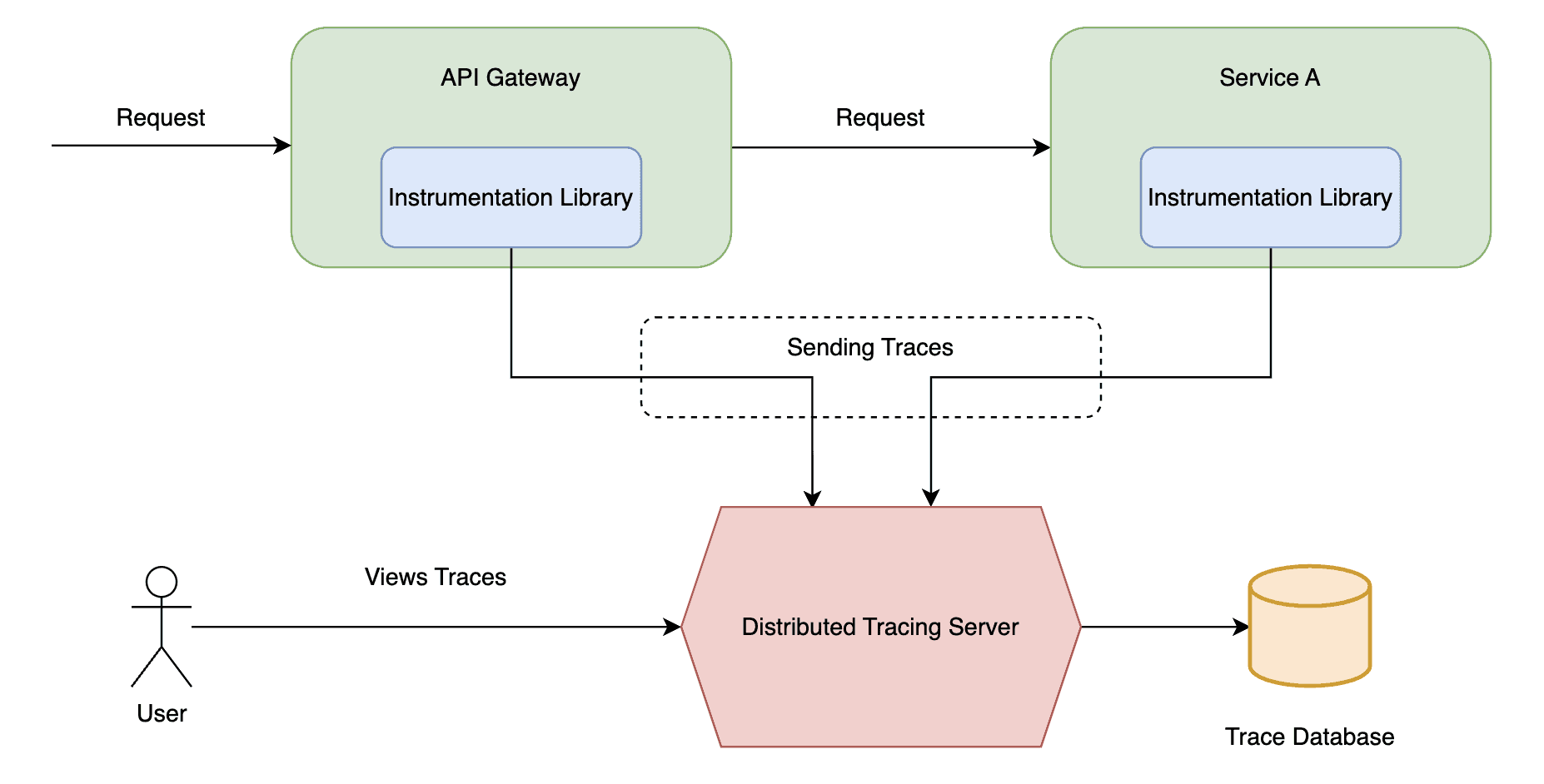
3. Zipkin
Zipkin 是 Twitter 开源的领先分布式追踪系统,专为解决微服务架构中的延迟问题而设计。它从埋点服务收集数据,并提供直观的可视化界面。
Zipkin 由四大核心组件构成,下文将逐一说明:
3.1. 收集器(Collector)
埋点服务生成追踪数据后需被收集处理。收集器负责接收和验证 Zipkin 收到的追踪数据,验证后存储以供后续分析。它支持 HTTP 和 AMQP 协议接收数据,灵活适配各类系统架构。
3.2. 存储(Storage)
Zipkin 最初采用 Cassandra 作为存储方案(因其高可扩展性、灵活性且在 Twitter 内部广泛使用)。现已支持更多存储选项,如 ElasticSearch、MySQL 甚至内存存储。
3.3. API
数据存储后,Zipkin 通过 RESTful 接口提供数据提取能力。该接口可轻松定位和检索追踪数据,同时也是 Zipkin Web 界面的主要数据源。
3.4. Web 界面(Web UI)
Zipkin 提供的图形界面支持按服务、时间和注解筛选追踪数据。它还支持深入分析具体追踪,对排查涉及分布式事务的复杂问题尤其有价值。
4. Brave
Brave 是分布式追踪的埋点库,能拦截生产请求、收集时序数据并传播追踪上下文。其核心目标是在分布式系统中关联时序数据,高效定位延迟问题。
虽然 Brave 通常将数据发送到 Zipkin 服务器,但通过第三方插件也可集成 Amazon X-Ray 等服务。
**Brave 提供无依赖的追踪器库,兼容 JRE6+**。核心 API 支持记录操作耗时并添加描述性标签,还内置解析 X-B3-TraceId 头部的功能。
多数场景无需直接实现追踪代码,可直接使用 Brave 和 Zipkin 提供的现成埋点方案。JDBC、Servlet、Spring 等常见场景的库已完备测试和基准验证。
针对遗留应用,Spring XML 配置 可实现无侵入式追踪。
若需将追踪 ID 集成到日志文件或修改线程本地行为,Brave 的上下文库能无缝对接 SLF4J 等工具。
5. Brave 使用指南
下面我们构建一个简单的 Java/Spring Boot 应用,集成 Brave 和 Zipkin。
5.1. Zipkin Slim 搭建
首先需运行 Zipkin 服务器。这里使用 Zipkin Slim(轻量版),它体积小、启动快,支持内存和 Elasticsearch 存储,但不支持 Kafka/RabbitMQ 消息队列。
多种部署方式详见 Zipkin 官方仓库,更多方案可参考我们关于 Zipkin 服务追踪 的文章。
假设本地已安装 Docker,执行以下命令启动:
docker run -d -p 9411:9411 openzipkin/zipkin-slim
访问 http://localhost:9411/zipkin/ 即可看到 Zipkin Web 界面。
5.2. 项目配置
从空 Spring Boot 项目开始,添加以下依赖:
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave</artifactId>
<version>6.0.2</version>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-sender-okhttp3</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter-brave</artifactId>
<version>3.3.0</version>
</dependency>
创建配置类实例化 Tracer Bean:
@Configuration
public class TracingConfiguration {
@Bean
BytesMessageSender sender() {
return OkHttpSender.create("http://127.0.0.1:9411/api/v2/spans");
}
@Bean
AsyncZipkinSpanHandler zipkinSpanHandler(BytesMessageSender sender) {
return AsyncZipkinSpanHandler.create(sender);
}
@Bean
public Tracing tracing(AsyncZipkinSpanHandler zipkinSpanHandler) {
return Tracing.newBuilder()
.localServiceName("Dummy Service")
.addSpanHandler(zipkinSpanHandler)
.build();
}
@Bean
public Tracer tracer(Tracing tracing) {
return tracing.tracer();
}
}
现在可直接注入 Tracer。下面创建一个示例服务,在初始化时发送追踪数据到 Zipkin:
@Service
public class TracingService {
private final Tracer tracer;
public TracingService(Tracer tracer) {
this.tracer = tracer;
}
@PostConstruct
private void postConstruct() {
Span span = tracer.nextSpan().name("Hello from Service").start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
span.finish();
}
}
}
启动应用后查看 Zipkin 界面,会看到一个耗时约 2 秒的单跨度追踪: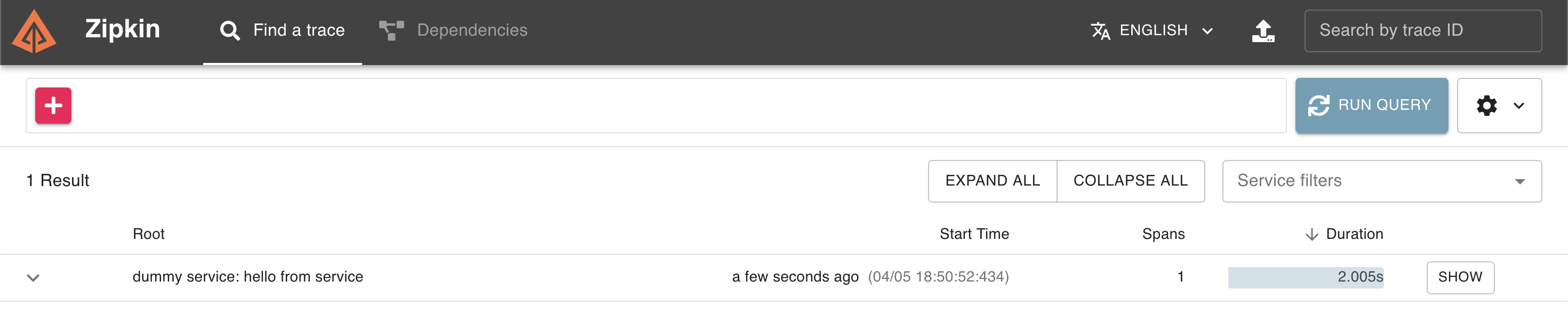
⚠️ 注意:此示例仅演示基础配置。复杂场景推荐使用 Spring Cloud Sleuth。
更多 Web 应用追踪方案可参考 brave-example 仓库。
6. 总结
通过本文我们了解到,Brave 能高效监控应用性能。它简化了埋点过程,与 Zipkin 的无缝集成使其成为分布式系统中的利器。
本文源码见 GitHub 仓库。