1. 概述
在本教程中,我们将了解 LRU缓存并了解 Java 中的实现。
2.LRU缓存
最近最少使用 (LRU) 缓存是一种缓存逐出算法,它按使用顺序组织元素。在LRU中,顾名思义,最长时间未使用的元素将从缓存中逐出。
例如,如果我们有一个容量为三个项目的缓存:
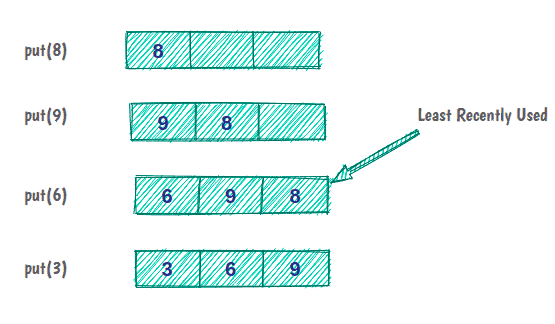
最初,缓存是空的,我们将元素 8 放入缓存中。元素 9 和 6 像以前一样被缓存。但现在,缓存容量已满,为了放置下一个元素,我们必须逐出缓存中最近最少使用的元素。
在我们用Java实现LRU缓存之前,有必要先了解一下缓存的一些方面:
- 所有操作应按 O(1) 的顺序运行
- 缓存的大小是有限的
- 所有缓存操作都必须支持并发
- 如果缓存已满,添加新项必须调用 LRU 策略
2.1. LRU 缓存的结构
现在,让我们思考一个有助于我们设计缓存的问题。
我们如何设计一个可以在恒定时间内执行读取、排序(时间排序)和删除元素等操作的数据结构?
看来,要找到这个问题的答案,我们需要深入思考一下关于LRU缓存及其特性的说法:
- 实际上,LRU 缓存是一种 队列—— 如果重新访问某个元素,它将到达驱逐顺序的末尾
- 由于缓存的大小有限,因此该队列将具有特定的容量。每当引入新元素时,它就会被添加到队列的头部。当驱逐发生时,它从队列的尾部发生。
- 命中缓存中的数据必须在恒定时间内完成,这在 Queue 中是不可能的!但是,使用 Java 的 HashMap 数据结构是可能的
- 删除最近最少使用的元素必须在恒定时间内完成,这意味着对于 Queue 的实现,我们将使用 DoublyLinkedList 而不是 SingleLinkedList 或数组
所以,LRU缓存只不过是 DoublyLinkedList 和 HashMap 的组合,如下所示:
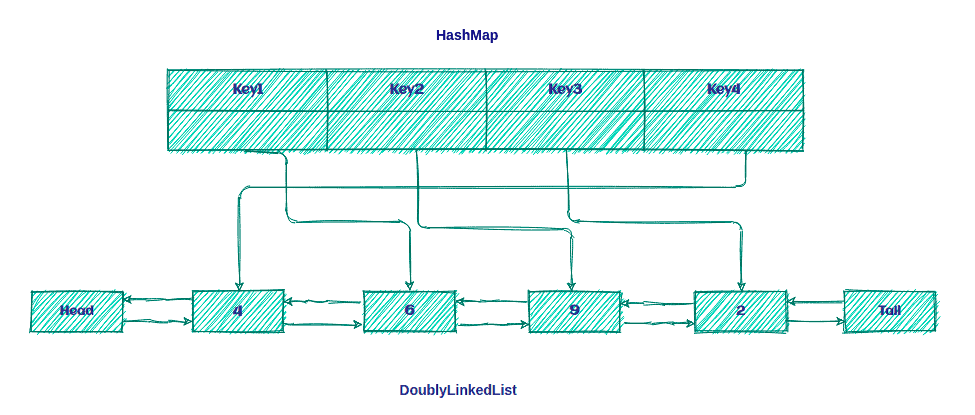
这个想法是将键保留在 Map 上,以便快速访问 Queue 中的数据。
2.2. LRU算法
LRU 算法非常简单!如果该键存在于 HashMap 中, 则它是缓存命中;否则,这是缓存未命中。
发生缓存未命中后,我们将执行两个步骤:
- 在列表前面添加一个新元素。
- 在 HashMap 中添加一个新条目并引用链表的头部。
并且,我们将在缓存命中后执行两个步骤:
- 删除hit元素并将其添加到列表前面。
- 使用对列表前面的新引用更新 HashMap 。
现在,是时候看看我们如何在 Java 中实现 LRU 缓存了!
3.Java中的实现
首先,我们将定义 Cache 接口:
public interface Cache<K, V> {
boolean set(K key, V value);
Optional<V> get(K key);
int size();
boolean isEmpty();
void clear();
}
现在,我们将定义代表缓存的 LRUCache 类:
public class LRUCache<K, V> implements Cache<K, V> {
private int size;
private Map<K, LinkedListNode<CacheElement<K,V>>> linkedListNodeMap;
private DoublyLinkedList<CacheElement<K,V>> doublyLinkedList;
public LRUCache(int size) {
this.size = size;
this.linkedListNodeMap = new HashMap<>(maxSize);
this.doublyLinkedList = new DoublyLinkedList<>();
}
// rest of the implementation
}
我们可以创建一个具有特定大小的 LRUCache 实例。在此实现中,我们使用 HashMap 集合来存储对 LinkedListNode 的 所有引用。
现在,让我们讨论 LRUCache 上的操作。
3.1.看跌操作
第一个是 put 方法:
public boolean put(K key, V value) {
CacheElement<K, V> item = new CacheElement<K, V>(key, value);
LinkedListNode<CacheElement<K, V>> newNode;
if (this.linkedListNodeMap.containsKey(key)) {
LinkedListNode<CacheElement<K, V>> node = this.linkedListNodeMap.get(key);
newNode = doublyLinkedList.updateAndMoveToFront(node, item);
} else {
if (this.size() >= this.size) {
this.evictElement();
}
newNode = this.doublyLinkedList.add(item);
}
if(newNode.isEmpty()) {
return false;
}
this.linkedListNodeMap.put(key, newNode);
return true;
}
首先,我们在 linkedListNodeMap 中找到存储所有键/引用的键。如果该键存在,则发生缓存命中,并且准备好从 DoublyLinkedList 中检索 CacheElement 并将其移动到前面*。*
之后,我们使用新引用更新 linkedListNodeMap 并将其移动到列表的前面:
public LinkedListNode<T> updateAndMoveToFront(LinkedListNode<T> node, T newValue) {
if (node.isEmpty() || (this != (node.getListReference()))) {
return dummyNode;
}
detach(node);
add(newValue);
return head;
}
首先,我们检查节点是否不为空。此外,节点的引用必须与列表相同。之后,我们从列表中 分离 该节点并将 newValue 添加到列表中。
但如果该键不存在,则发生缓存未命中,我们必须将新键放入 linkedListNodeMap 中。在此之前,我们先检查列表大小。如果列表已满,我们必须从列表中 逐出 最近最少使用的元素。
3.2.获取操作
我们来看看我们的 get 操作:
public Optional<V> get(K key) {
LinkedListNode<CacheElement<K, V>> linkedListNode = this.linkedListNodeMap.get(key);
if(linkedListNode != null && !linkedListNode.isEmpty()) {
linkedListNodeMap.put(key, this.doublyLinkedList.moveToFront(linkedListNode));
return Optional.of(linkedListNode.getElement().getValue());
}
return Optional.empty();
}
正如我们在上面看到的,这个操作很简单。首先,我们从 linkedListNodeMap 中获取节点,然后检查它是否不为 null 或为空。
其余操作与之前相同,只有 moveToFront 方法有一点不同:
public LinkedListNode<T> moveToFront(LinkedListNode<T> node) {
return node.isEmpty() ? dummyNode : updateAndMoveToFront(node, node.getElement());
}
现在,让我们创建一些测试来验证我们的缓存是否正常工作:
@Test
public void addSomeDataToCache_WhenGetData_ThenIsEqualWithCacheElement(){
LRUCache<String,String> lruCache = new LRUCache<>(3);
lruCache.put("1","test1");
lruCache.put("2","test2");
lruCache.put("3","test3");
assertEquals("test1",lruCache.get("1").get());
assertEquals("test2",lruCache.get("2").get());
assertEquals("test3",lruCache.get("3").get());
}
现在,让我们测试一下驱逐政策:
@Test
public void addDataToCacheToTheNumberOfSize_WhenAddOneMoreData_ThenLeastRecentlyDataWillEvict(){
LRUCache<String,String> lruCache = new LRUCache<>(3);
lruCache.put("1","test1");
lruCache.put("2","test2");
lruCache.put("3","test3");
lruCache.put("4","test4");
assertFalse(lruCache.get("1").isPresent());
}
4. 处理并发
到目前为止,我们假设我们的缓存仅在单线程环境中使用。
为了使这个容器线程安全,我们需要同步所有公共方法。让我们在之前的实现中添加一个 ReentrantReadWriteLock 和 ConcurrentHashMap :
public class LRUCache<K, V> implements Cache<K, V> {
private int size;
private final Map<K, LinkedListNode<CacheElement<K,V>>> linkedListNodeMap;
private final DoublyLinkedList<CacheElement<K,V>> doublyLinkedList;
private final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
public LRUCache(int size) {
this.size = size;
this.linkedListNodeMap = new ConcurrentHashMap<>(size);
this.doublyLinkedList = new DoublyLinkedList<>();
}
// ...
}
我们更喜欢使用可重入读/写锁,而不是将方法声明为 同步 ,因为它使我们可以更灵活地决定何时使用读和写锁。
4.1. 写锁
现在,让我们在 put 方法中添加对 writeLock 的调用:
public boolean put(K key, V value) {
this.lock.writeLock().lock();
try {
//..
} finally {
this.lock.writeLock().unlock();
}
}
当我们对资源使用 writeLock 时,只有持有锁的线程才能对该资源进行写入或读取。因此,尝试读取或写入该资源的所有其他线程都必须等待,直到当前锁持有者释放它。
这对于防止死锁非常重要。如果 try 块内的任何操作失败,我们仍然会在退出函数之前释放锁,并在方法末尾使用 finally 块。
需要 writeLock 的其他操作之一是 evictElement ,我们在 put 方法中使用了它:
private boolean evictElement() {
this.lock.writeLock().lock();
try {
//...
} finally {
this.lock.writeLock().unlock();
}
}
4.2. 读锁
现在是时候向 get 方法添加 readLock 调用了:
public Optional<V> get(K key) {
this.lock.readLock().lock();
try {
//...
} finally {
this.lock.readLock().unlock();
}
}
这看起来正是我们用 put 方法所做的。唯一的区别是我们使用 readLock 而不是 writeLock 。因此,读锁和写锁之间的这种区别允许我们在缓存未更新时并行读取缓存。
现在,让我们在并发环境中测试我们的缓存:
@Test
public void runMultiThreadTask_WhenPutDataInConcurrentToCache_ThenNoDataLost() throws Exception {
final int size = 50;
final ExecutorService executorService = Executors.newFixedThreadPool(5);
Cache<Integer, String> cache = new LRUCache<>(size);
CountDownLatch countDownLatch = new CountDownLatch(size);
try {
IntStream.range(0, size).<Runnable>mapToObj(key -> () -> {
cache.put(key, "value" + key);
countDownLatch.countDown();
}).forEach(executorService::submit);
countDownLatch.await();
} finally {
executorService.shutdown();
}
assertEquals(cache.size(), size);
IntStream.range(0, size).forEach(i -> assertEquals("value" + i,cache.get(i).get()));
}
5. 结论
在本教程中,我们了解了 LRU 缓存到底是什么,包括它的一些最常见的功能。然后,我们了解了一种在 Java 中实现 LRU 缓存的方法,并探讨了一些最常见的操作。
最后,我们介绍了使用锁机制的并发性。
与往常一样,本文中使用的所有示例都可以在 GitHub 上找到。