1. Overview
In the modern digital landscape, web applications often require users to log in to access personalized or restricted content. As developers and administrators, it’s essential to interact with these pages programmatically to retrieve data or automate tasks.
One powerful tool for achieving this is curl, a command-line tool, and library for transferring data with URLs. In this tutorial, we’ll explore how to use curl to access a page that requires login from another page.
curl, short for “Client URL,” is a versatile tool that allows us to send and receive data using various protocols, including HTTP, HTTPS, FTP, and more. It operates on the command line and supports a wide range of options and features. By utilizing curl, we can simulate user interactions with websites, authenticate to access secured content, and retrieve data for further processing.
2. Inspecting the Login Process
Imagine we’re tasked with accessing a specific logged-in page on a website. Let’s see how the login process works, starting with the structure of the requests involved. T****he login process involves sending a POST request with the right credentials and handling the subsequent authentication cookies.
Armed with the authentication cookies, we’re now equipped to interact with the logged-in page just as if we had manually logged in:
For example, we can look for network requests when logging in. To realize the same, we can use a web browser’s developer tools (usually accessible by pressing F12) to monitor network activity:
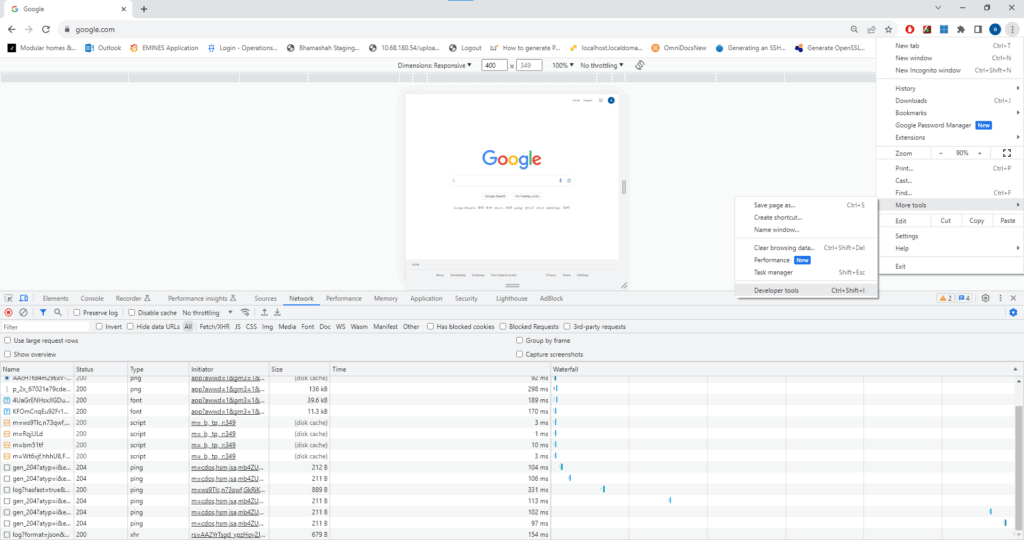
This involves identifying requests by paying attention to the POST request made when submitting the login form. While observing a POST request, we must take note of the URL, headers, form data, and cookies involved as most websites use cookies or session tokens to maintain user authentication.
3. Using curl to Authenticate
Now that we understand the login process, it’s time to leverage curl to do just that.
We’ll use the curl command to replicate the POST request we observe during the login process. The command to log in will include the necessary headers, form data, and cookies:
$ curl -X POST -d "username=your_username&password=your_password" \
-H "Content-Type: application/x-www-form-urlencoded" \
-b "cookie_name=cookie_value" \
https://example.com/login
After a successful login, the website responds with cookies or session tokens that indicate our authenticated status.
We then capture these cookies using the -c option in curl and save them to a file:
$ curl -X POST -d "..." -H "..." \
-c cookies.txt \
https://example.com/login
4. Accessing the Logged-in Page
Now that we have the necessary authentication cookies, we’ll use them to access the logged-in page.
We’ll make a GET request to the desired logged-in page, including the authentication cookies:
$ curl -b cookies.txt https://example.com/logged-in-page
The output of this curl command contains the HTML content of the logged-in page:
<!DOCTYPE html>
<html>
<head>
<title>Logged In Page</title>
<!-- Other meta tags, styles, and scripts -->
</head>
<body>
<h1>Welcome to the Logged-In Page!</h1>
<p>This is the content that only authenticated users can access.</p>
<!-- More content specific to the logged-in page -->
</body>
</html>
We can process this content using various methods, such as parsing with tools like grep, awk, or even more advanced scripting languages.
5. Important Considerations
Storing and transmitting authentication credentials and cookies requires caution. Therefore, we must ensure to keep sensitive information secure and avoid exposing it in our commands or scripts.
We must always respect the terms of use of the website we’re interacting with. Accessing the websites using an automated approach must not violate any policies or terms that the website enforces.
Websites may use dynamic tokens or anti-CSRF measures that make replicating the login process more complex. We should be prepared to adapt our approach accordingly.
6. Conclusion
In this article, we discussed a powerful technique for automating tasks and retrieving data programmatically by using curl to access a page that requires login from another page. At the same time, we learned that by understanding the login process, crafting proper requests, and using authentication cookies, we can replicate user interactions and access restricted content.
In the end, we took a look at essential considerations that involve handling sensitive information securely and adhering to the website’s terms of use. We must make sure to observe these practices while using the capabilities of curl to enhance our web automation efforts.