1. 概述
本文将深入探讨 Milvus,一个高度可扩展的开源向量数据库。它专为存储和索引来自深度神经网络及其他机器学习模型的向量嵌入而设计。Milvus 能高效处理文本、图像、语音和视频等多样化数据的相似性搜索。我们将重点解析 Milvus Java 客户端 SDK,通过第三方应用集成和管理 Milvus 数据库。为便于理解,我们将以存储书籍向量化内容实现相似性搜索的应用场景为例。
2. 核心概念
在探索 Milvus Java SDK 的能力前,先理解 Milvus 的数据逻辑组织方式:
- Collection:存储向量的逻辑容器,类似于传统数据库中的表
- Field:集合内标量和向量实体的属性,定义数据类型等特性
- Schema:定义集合内数据的结构和属性
- Index:通过组织向量优化检索效率的索引机制
- Partition:集合内的逻辑分区,用于更高效的数据管理
3. 前置准备
在探索 Java API 前,需完成运行示例代码的准备工作。
3.1 Milvus 数据库实例
首先需要一个 Milvus DB 实例。最简单快捷的方式是获取 Zilliz Cloud 提供的免费托管实例:
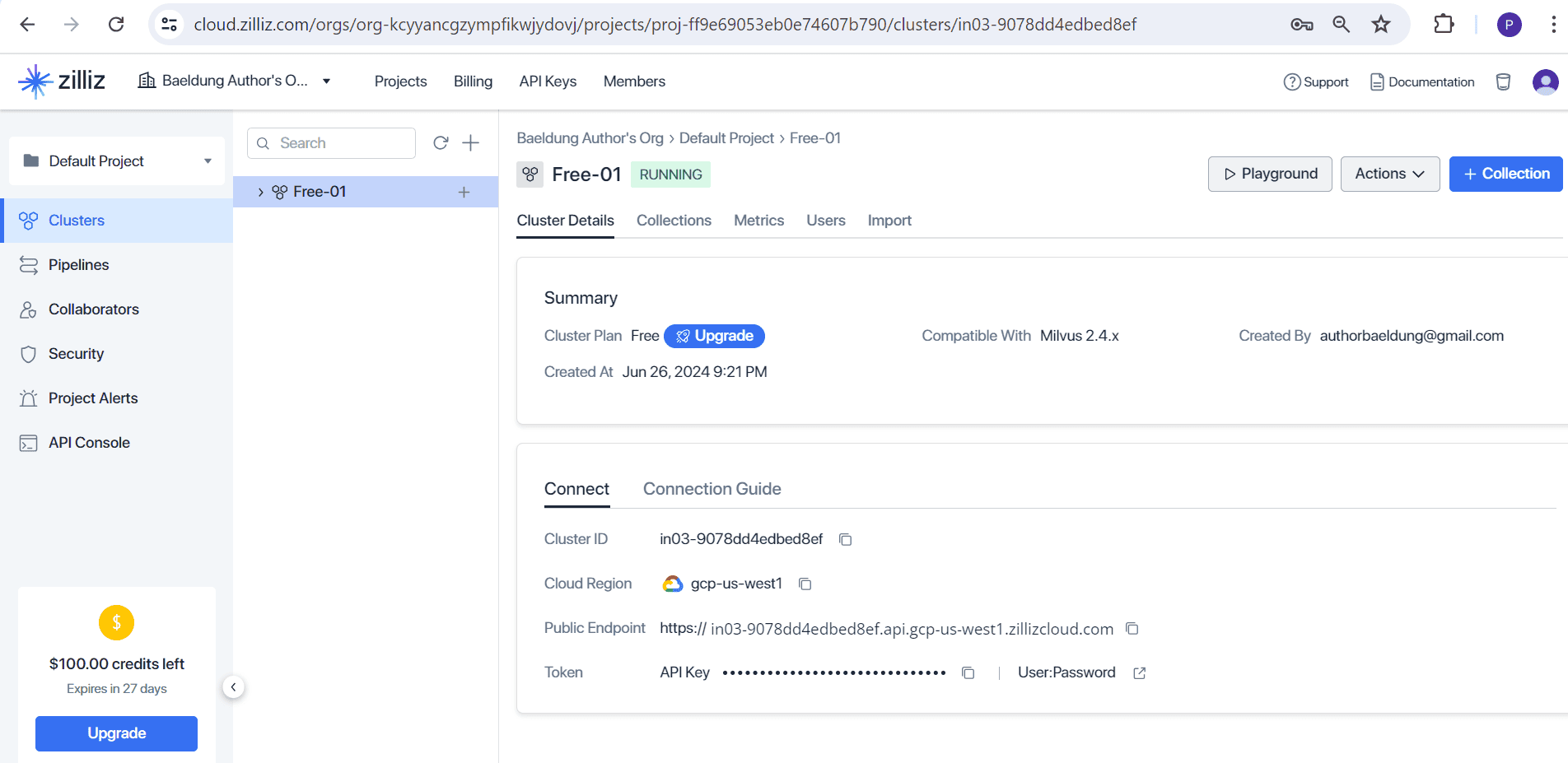
操作步骤:
3.2 Maven 依赖
探索 Milvus Java API 前,需添加必要的 Maven 依赖:
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.3.6</version>
</dependency>
4. Milvus Java 客户端 SDK
Milvus DB 服务接口基于 gRPC 框架构建,因此其 Python、Go、Java 等多语言客户端 SDK 均在此框架上提供 API。Milvus Java 客户端 SDK 支持完整的 CRUD(创建、读取、更新、删除)操作,同时支持创建集合、索引和分区等管理操作。执行数据库操作时,API 提供对应的请求和请求构建器类。开发者可通过构建器设置请求参数,最终通过客户端类将请求发送至后端服务。后续章节将详细说明此流程。
5. 创建 Milvus 数据库客户端
Java 客户端 SDK 提供 MilvusClientV2 类用于 Milvus DB 的管理和数据操作。ConnectConfigBuilder 类用于构建父类 ConnectConfig,该类包含创建 MilvusClientV2 实例所需的连接信息:

创建 MilvusClientV2 实例的示例代码:
MilvusClientV2 createConnection() {
ConnectConfig connectConfig = ConnectConfig.builder()
.uri(CONNECTION_URI)
.token(API_KEY)
.build();
milvusClientV2 = new MilvusClientV2(connectConfig);
return milvusClientV2;
}
ConnectConfig 类支持用户名密码认证,但推荐使用 API token 方式。ConnectConfigBuilder 通过 URI 和 API token 创建 ConnectConfig 对象,进而用于初始化 MilvusClientV2。
6. 创建集合
在 Milvus 向量数据库存储数据前,必须先创建集合。流程包括:创建字段模式、集合模式,构建创建集合请求对象,最后由客户端将请求发送至数据库服务接口。
6.1 创建字段模式和集合模式
先了解 Milvus Java SDK 中的关键类:
*FieldSchema 类用于定义集合字段,*CollectionSchema 则通过 FieldSchema 定义集合结构*。IndexParamBuilder* 类(属于 IndexParam)用于创建集合索引。通过示例代码探索其他类。创建 FieldSchema 对象的方法 *createFieldSchema()*:
CreateCollectionReq.FieldSchema createFieldSchema(String name, String desc, DataType dataType,
boolean isPrimary, Integer dimension) {
CreateCollectionReq.FieldSchema fieldSchema = CreateCollectionReq.FieldSchema.builder()
.name(name)
.description(desc)
.autoID(false)
.isPrimaryKey(isPrimary)
.dataType(dataType)
.build();
if (null != dimension) {
fieldSchema.setDimension(dimension);
}
return fieldSchema;
}
FieldSchema 的 builder() 方法返回其子类 FieldSchemaBuilder 实例,用于设置集合字段的名称、描述和数据类型等关键属性。构建器的 isPrimaryKey() 方法标记主键字段,FieldSchema 的 setDimension() 方法设置向量字段的必需维度。例如,在 createFieldSchemas() 方法中为 Books 集合设置字段:
private static List<CreateCollectionReq.FieldSchema> createFieldSchemas() {
List<CreateCollectionReq.FieldSchema> fieldSchemas = List.of(
createFieldSchema("book_id", "Primary key", DataType.Int64, true, null),
createFieldSchema("book_name", "Book Name", DataType.VarChar, false, null),
createFieldSchema("book_vector", "vector field", DataType.FloatVector, false, 5)
);
return fieldSchemas;
}
方法返回 Books 集合的 book_id、book_name 和 book_vector 字段模式列表。book_vector 字段存储维度为 5 的向量,book_id 为主键。实际场景中,book_vector 字段将存储书籍文本的向量化结果。每个 FieldSchema 对象通过前述 createFieldSchema() 方法创建。创建字段模式后,在 createCollectionSchema() 方法中构建 Books 的 CollectionSchema 对象:
private static CreateCollectionReq.CollectionSchema createCollectionSchema(
List<CreateCollectionReq.FieldSchema> fieldSchemas) {
return CreateCollectionReq.CollectionSchema.builder()
.fieldSchemaList(fieldSchemas)
.build();
}
子类 CollectionSchemaBuilder 设置字段模式后构建父类 CollectionSchema 对象。
6.2 创建集合请求与集合
创建集合的步骤如下:
void whenCommandCreateCollectionInVectorDB_thenSuccess() {
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName("Books")
.indexParams(List.of(createIndexParam("book_vector", "book_vector_indx")))
.description("Collection for storing the details of books")
.collectionSchema(createCollectionSchema(createFieldSchemas()))
.build();
milvusClientV2.createCollection(createCollectionReq);
assertTrue(milvusClientV2.hasCollection(HasCollectionReq.builder()
.collectionName("Books")
.build()));
}
}
使用 CreateCollectionReqBuilder 构建 CreateCollectionReq 对象,设置 CollectionSchema 等参数。将此对象传递给 MilvusClientV2 的 createCollection() 方法创建集合。最后调用 hasCollection(HasCollectionReq) 验证。CreateCollectionReqBuilder 还通过 indexParams() 为 book_vector 字段定义索引。查看创建 IndexParam 对象的 createIndexParam() 方法:
IndexParam createIndexParam(String fieldName, String indexName) {
return IndexParam.builder()
.fieldName(fieldName)
.indexName(indexName)
.metricType(IndexParam.MetricType.COSINE)
.indexType(IndexParam.IndexType.AUTOINDEX)
.build();
}
方法使用 IndexParamBuilder 设置 Milvus DB 中索引的各种支持属性。注意 IndexParam 对象的 COSINE 度量类型属性对计算向量间相似度分数至关重要。与传统数据库类似,索引可提升 Milvus 向量数据库中高频访问字段的查询性能。在 Zilliz 云控制台验证创建的 Books 集合详情: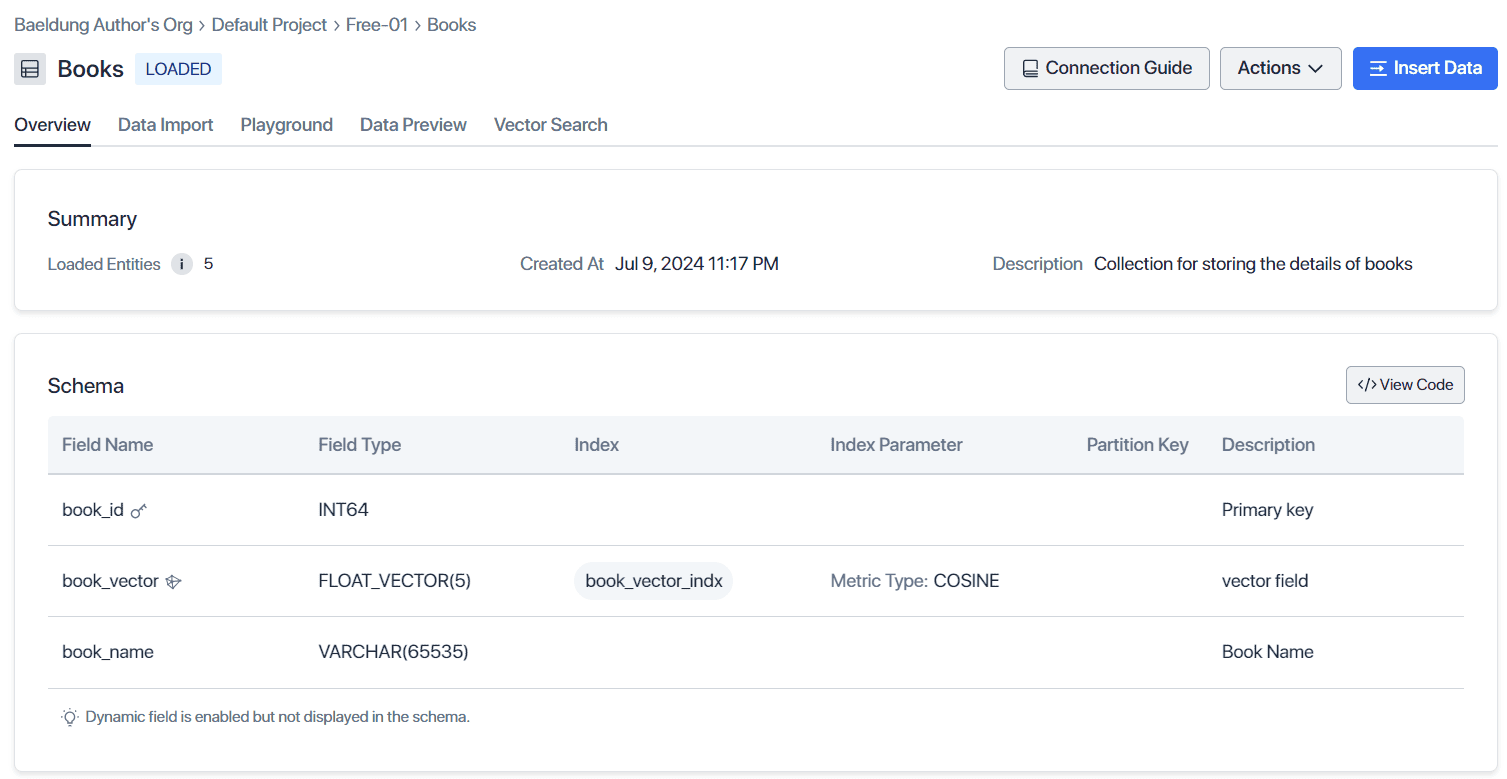
7. 创建分区
创建 Books 集合后,可使用分区类高效组织数据。
子类 CreatePartitionReqBuilder 通过设置分区和目标集合名称构建父类 CreatePartitionReq 对象。请求对象随后传递给 MilvusClientV2 的 createPartition() 方法。使用前述类在 Books 集合中创建 Health 分区:
void whenCommandCreatePartitionInCollection_thenSuccess() {
CreatePartitionReq createPartitionReq = CreatePartitionReq.builder()
.collectionName("Books")
.partitionName("Health")
.build();
milvusClientV2.createPartition(createPartitionReq);
assertTrue(milvusClientV2.hasPartition(HasPartitionReq.builder()
.collectionName("Books")
.partitionName("Health")
.build()));
}
方法中,createPartitionReqBuilder 为 Books 集合创建 CreatePartitionReq 对象。MilvusClientV2 对象调用 createPartition() 方法执行分区创建。最后通过 hasPartition() 方法验证分区存在。
8. 向集合插入数据
在 Milvus DB 创建 Books 集合后,可插入数据。先了解关键类:
子类 InsertReqBuilder 通过设置 collectionName 和 data 构建父类 InsertReq 对象。InsertReqBuilder 的 data() 方法接收 List
[
{
"book_id": 1,
"book_vector": [
0.6428583619771759,
0.18717933359890893,
0.045491267667689295,
0.8578131397291819,
0.6431108625406422
],
"book_name": "Yoga"
},
更多对象...
...
]
**实际应用中通常使用 BERT、Word2Vec 等嵌入模型生成文本、图像、语音样本的向量维度**。前述类的实际应用示例:
void whenCommandInsertDataIntoVectorDB_thenSuccess() throws IOException {
List<JSONObject> bookJsons = readJsonObjectsFromFile("book_vectors.json");
InsertReq insertReq = InsertReq.builder()
.collectionName("Books")
.partitionName("Health")
.data(bookJsons)
.build();
InsertResp insertResp = milvusClientV2.insert(insertReq);
assertEquals(bookJsons.size(), insertResp.getInsertCnt());
}
readJsonObjectsFromFile() 方法读取 JSON 数据存入 bookJsons 对象。如前所述,用数据构建 InsertReq 对象后传递给 MilvusClientV2 的 insert() 方法。InsertResp 对象的 getInsertCnt() 方法返回插入记录总数。可在 Zilliz 云控制台验证插入记录: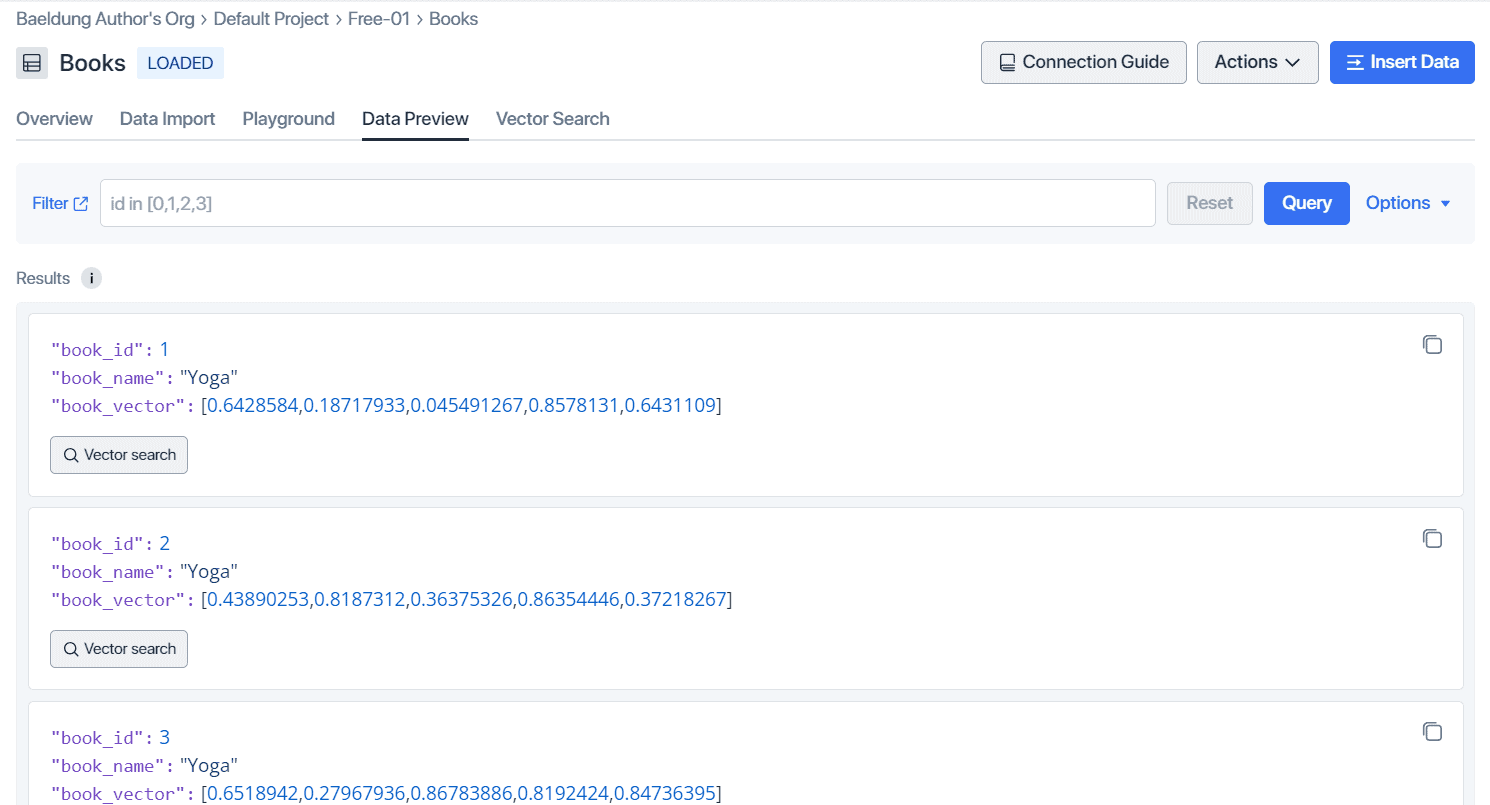
9. 执行向量相似性搜索
Milvus 通过关键类支持集合的向量相似性搜索:
SearchRequestBuilder 设置父类 SearchReq 的 topK 最近邻、查询向量和集合名称等属性。还可在 filter() 方法中设置标量表达式获取匹配实体。最后 MilvusClientV2 类调用 search() 方法通过 SearchReq 对象获取记录。通过示例代码深入理解:
void givenSearchVector_whenCommandSearchDataFromCollection_thenSuccess() {
List<Float> queryEmbedding = getQueryEmbedding("What are the benefits of Yoga?");
SearchReq searchReq = SearchReq.builder()
.collectionName("Books")
.data(Collections.singletonList(queryEmbedding))
.outputFields(List.of("book_id", "book_name"))
.topK(2)
.build();
SearchResp searchResp = milvusClientV2.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
searchResults.forEach(e -> e.forEach(el -> logger.info("book_id: {}, book_name: {}, distance: {}",
el.getEntity().get("book_id"), el.getEntity().get("book_name"), el.getDistance()))
);
}
首先,getQueryEmbedding() 方法将查询转换为向量维度或嵌入。然后 SearchReqBuilder 对象通过所有搜索相关参数构建 SearchReq 对象。有趣的是,可通过构建器的 outputFields() 方法控制结果实体中的字段名。最后调用 MilvusClientV2 的 search() 方法获取查询结果:
book_id: 6, book_name: Yoga, distance: 0.8046049
book_id: 3, book_name: Tai Chi, distance: 0.5370003
搜索结果的 distance 属性表示相似度分数。本例中,我们采用余弦相似度(COSINE)衡量相似度。余弦值越大,向量间夹角越小,表明向量越相似。此外,Milvus 还支持浮点型嵌入的更多度量类型,如欧氏距离(L2)和内积(IP)。
10. 删除集合中的数据
先通过类图了解删除集合数据的关键类:
MilvusClientV2 的 delete() 方法删除 Milvus DB 中的记录,它接收 DeleteReq 对象,该对象通过 ids 和 filter 字段指定记录。子类 DeleteRequestBuilder 用于构建父类 DeleteReq 对象。通过示例代码深入理解。从 Books 集合中删除 book_id 为 1 和 2 的记录:
void givenListOfIds_whenCommandDeleteDataFromCollection_thenSuccess() {
DeleteReq deleteReq = DeleteReq.builder()
.collectionName("Books")
.ids(List.of(1, 2))
.build();
DeleteResp deleteResp = milvusClientV2.delete(deleteReq);
assertEquals(2, deleteResp.getDeleteCnt());
}
调用 MilvusClientV2 的 delete() 方法后,通过 DeleteResp 的 getDeleteCnt() 方法验证删除记录数。还可在 DeleteReqBuilder 对象的 filter() 方法中使用标量表达式规则指定待删除的匹配记录:
void givenFilterCondition_whenCommandDeleteDataFromCollection_thenSuccess() {
DeleteReq deleteReq = DeleteReq.builder()
.collectionName("Books")
.filter("book_id > 4")
.build();
DeleteResp deleteResp = milvusClientV2.delete(deleteReq);
assertTrue(deleteResp.getDeleteCnt() >= 1 );
}
根据 filter() 方法定义的标量条件,book_id 大于 4 的记录将从集合中删除。
11. 总结
本文全面解析了 Milvus Java SDK,涵盖向量数据库管理的几乎所有核心操作。API 设计直观易用,便于快速构建 AI 驱动应用。但需注意,高效使用 API 需具备向量基础知识。本文代码已发布在 GitHub 上。