1. 概述
Apache Kafka 是一个开源的分布式事件流平台。其分布式架构具备高可扩展性、高可用性和容错能力。Kafka 的核心是基于 仅追加(append-only) 日志模型,消息被顺序写入日志文件的末尾。这种顺序写入机制使得 Kafka 能够实现非常高的写入吞吐量。
然而,Kafka 的顺序写入机制使得它无法天然支持消息优先级的语义,也就是说,Kafka 没有内置机制可以区分消息的优先级。本文将介绍两种在 Kafka 中实现消息优先级的策略。
2. 什么是消息优先级
在消息系统中,消息优先级是指根据消息的重要性对消息进行分类处理。例如,在金融系统中,欺诈警报、转账通知和促销消息可能具有不同的优先级。我们希望欺诈警报和支付确认消息能够优先于促销消息被处理。
目标是在存在队列或资源竞争的情况下,确保高优先级消息优先于低优先级消息被处理。
在一些消息队列系统中(如 RabbitMQ),支持优先级队列,可以保证优先级队列中的消息先于普通队列的消息被消费。
3. Kafka 中实现消息优先级的挑战
Kafka 并没有原生支持消息优先级机制。它无法对某条消息标记为“更高优先级”,并期望 broker 以不同方式处理。这在同一个 topic 中包含多种优先级消息时,就会带来问题。
举个例子:一个金融系统中有三种消息类型:欺诈警报、转账通知和促销消息。它们的优先级依次降低。
如果我们把这些消息都发布到同一个 topic 中,那么高优先级消息的处理延迟就会受到低优先级消息流量的影响。比如促销消息数量远高于欺诈警报,就会拖慢欺诈警报的处理速度。
如下图所示,所有消息都按顺序写入分区,消费者必须先处理前面的低优先级消息,才能处理后面的高优先级消息。
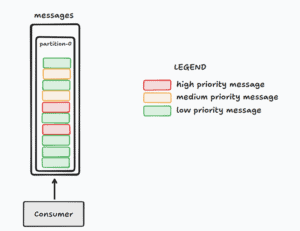
为了解决这个问题,我们可以采用以下两种策略:
4. 按优先级划分 Topic
第一种策略是为不同优先级的消息创建不同的 topic。生产者根据消息的优先级将消息发送到对应的 topic,消费者也根据 topic 订阅并处理消息。
继续以我们之前的金融系统为例,我们可以创建三个 topic:message-high、message-medium 和 message-low。
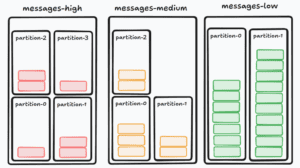
✅ 优点:
- 高优先级消息不会被低优先级消息阻塞
- 可以针对不同 topic 分配不同的资源(如分区数、副本数等)
- 更容易设置 SLA 和监控机制
❌ 缺点:
- 增加了 topic 的数量,带来一定的运维复杂度
5. Bucket Priority 模式(分区级优先级)
Bucket Priority 模式是一种在分区级别实现消息优先级的策略。与第一种方式不同,它使用一个 topic 的多个分区来模拟“优先级桶”。
5.1 工作原理
- 将 topic 的分区划分为多个组,每个组对应一个优先级
- 高优先级组分配更多的分区,从而实现更高的并行度
- 生产者通过消息的 key 决定其归属哪个“桶”
- 消费者可以选择性地消费某个优先级的桶
这种方式允许我们使用一个 topic 来承载不同优先级的消息,同时实现优先级调度。
5.2 生产者配置
我们需要配置 KafkaProducer 使用 BucketPriorityPartitioner 作为分区策略:
Properties configs = new Properties();
configs.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG,
BucketPriorityPartitioner.class.getName());
KafkaProducer<K, V> producer = new KafkaProducer<>(configs);
指定 topic:
configs.setProperty(BucketPriorityConfig.TOPIC_CONFIG, "messages");
定义优先级桶和分区分配比例:
configs.setProperty(BucketPriorityConfig.BUCKETS_CONFIG, "high", "medium", "low");
configs.setProperty(BucketPriorityConfig.ALLOCATION_CONFIG, "60%", "30%", "10%");
⚠️ 注意:
ALLOCATION_CONFIG的总和必须为 100%- 每个桶的分区比例顺序必须与
BUCKETS_CONFIG一致
5.3 消费者配置
消费者需要使用 BucketPriorityAssignor 进行分区分配:
Properties configs = new Properties();
configs.setProperty(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
BucketPriorityAssignor.class.getName());
KafkaConsumer<K, V> highPriorityMessageConsumers = new KafkaConsumer<>(configs);
同样需要配置桶的划分信息:
configs.setProperty(BucketPriorityConfig.TOPIC_CONFIG, "messages");
configs.setProperty(BucketPriorityConfig.BUCKETS_CONFIG, "high", "medium", "low");
configs.setProperty(BucketPriorityConfig.ALLOCATION_CONFIG, "60%", "30%", "10%");
然后指定要消费的桶:
configs.setProperty(BucketPriorityConfig.BUCKET_CONFIG, "high");
这样消费者只会消费属于 high 桶的分区。
5.4 发送消息到指定桶
要将消息发送到指定的桶,只需将消息 key 设置为对应的桶名:
String key = "high";
String message = "{\"event\": \"FraudAlert\", \"id\": 1, \"userId\": 1}";
ProducerRecord<String, String> record = new ProducerRecord<>("messages", key, message);
producer.send(record);
⚠️ 注意:
- key 必须以桶名开头,后面可以跟
-和其他标识符,如high-001、high-123456都是合法的
6. 总结
Apache Kafka 本身不支持消息优先级机制,但我们可以采用以下两种策略来实现:
| 策略 | 优点 | 缺点 |
|---|---|---|
| 按优先级划分 Topic | 简单易实现,资源隔离性好 | 运维复杂度高,topic 数量多 |
| Bucket Priority 模式 | 使用单一 topic,分区级优先级控制 | 实现较复杂,需引入自定义 partitioner 和 assignor |
✅ 选择建议:
- 如果你希望快速实现优先级控制,且不介意多几个 topic,那么“按优先级划分 Topic”是首选
- 如果你希望统一 topic 管理,并且对性能和资源调度有更高要求,可以尝试 Bucket Priority 模式
两种方式各有优劣,选择时需结合业务场景、运维能力以及性能需求综合评估。