1. 引言
我们在日常生活中不断与环境互动,每一次决策都会以某种未知的方式影响接下来的选择。这种行为正是强化学习(Reinforcement Learning, RL)的核心。不同的是,在 RL 中,这种互动规则不是未知的,而是预定义好的。
强化学习算法可以分为两大类:无模型(Model-free, MF) 和 基于模型(Model-based, MB)。如果一个智能体(agent)能够通过预测动作的后果来学习,那么它就是 MB 的;如果只能通过经验来学习,那么它就是 MF 的。
在本文中,我们会通过具体的例子来解释这两种方法的异同,帮助你更清晰地理解它们的适用场景和优劣势。
2. 强化学习基础
在强化学习中,智能体可以在环境中执行动作(action),而环境状态(state)之间的转换具有一定的概率性,这些转换可以是确定性的,也可以是随机的。
强化学习的目标是让智能体学会如何在环境中行动,以最大化累计奖励(cumulative reward)。
我们把智能体用来最大化奖励的策略(policy)定义为算法本身。关键点在于:策略可以是 MF 的,也可以是 MB 的。
接下来我们先来看什么是无模型策略。
3. 无模型强化学习
简单来说,无模型算法是通过动作带来的结果来不断优化策略的。我们通过一个例子来说明。
考虑一个 5×5 的网格环境:
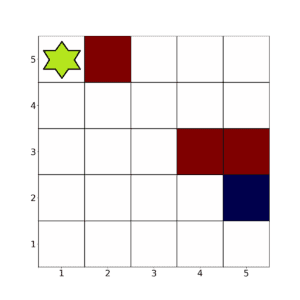
在这个例子中,绿色格子代表智能体,红色格子代表障碍物,蓝色格子是目标。我们的目标是让智能体尽可能快地避开红色格子,到达蓝色格子。
为此,我们定义如下的奖励函数:
- 落在空白格子:-1 分
- 落在红色格子:-100 分
- 落在蓝色格子:+100 分
智能体有四个动作:左、右、上、下。在边界上时,动作选择受限。
我们来看看 Q-learning 是如何优化智能体行为的。
3.1 Q-learning
我们运行 15 个 episode,每个 episode 1000 次迭代。
下图展示了每个 episode 的平均奖励变化趋势:
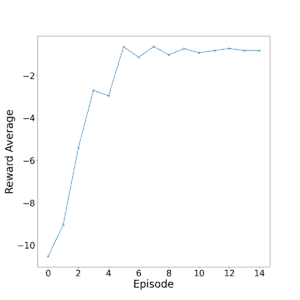
从图中可以看出,大约在第 8 个 episode(8000 次迭代)时,智能体已经基本学会了任务。
然而,Q-learning 在处理长期奖励时显得“短视”。这个问题可以通过使用 深度 Q-learning(Deep Q-learning) 来缓解,它使用神经网络代替 Q-table 来处理更复杂的状态空间。
✅ 优点:Q-learning 计算效率高,适合状态空间较小的问题。
❌ 缺点:缺乏对未来奖励的预测能力,容易陷入局部最优。
4. 基于模型的强化学习
你可能会问:Q-learning 不是也维护了一个 Q-table 吗?这不也是一种“模型”吗?
确实,Q-table 可以看作是环境的一种表示,但在 RL 领域,模型(model)通常指的是对环境动态的建模,即:
- 给定当前状态和动作,预测下一个状态
- 预测该动作带来的即时奖励
只有具备这些能力的策略,才被称为基于模型的(MB)方法。
MB 方法的最大优势在于:智能体可以通过少量的环境交互,构建一个模型来模拟后续的轨迹,从而减少对真实环境的依赖。
这类似于在训练前先“思考”一下哪些路径可能更好,而不是盲目试错。
4.1 模型预测控制(MPC)
一种常见的 MB 方法是 模型预测控制(Model Predictive Control, MPC)。
它的核心思想是:
- 每次只执行一个最优动作
- 然后重新计算下一步的最优动作
这样可以减少轨迹优化的计算量,同时保持较高的策略质量。
4.2 模型预测学习示例
回到前面的 5×5 网格环境,假设现在动作是随机的,即每次动作有一定概率落在相邻格子中。
比如,智能体当前处于某个状态:
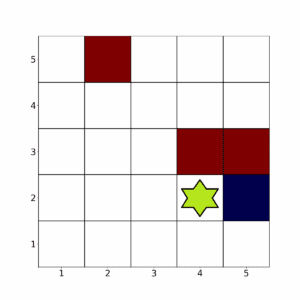
在确定性动作下,向右移动是最佳选择。但在随机动作下,向右可能失败,导致智能体无法快速到达目标。
MB 方法可以估计这些转移概率,并模拟不同路径,最终告诉智能体:
“先向下,再向右,然后向上,这个路径更可能获得高奖励。”
一个典型的例子是 蒙特卡洛学习(Monte Carlo Learning),它通过收集每个 episode 的轨迹数据,来调整智能体的行为。
⚠️ 注意:与 MPC 不同,蒙特卡洛方法不建模轨迹,因此没有模型偏差,但策略更新只能在每个 episode 结束后进行,效率较低。
5. 总结
通过本文,我们建立了对无模型和基于模型强化学习的基本理解:
| 类型 | 是否建模环境 | 是否预测奖励 | 优点 | 缺点 |
|---|---|---|---|---|
| 无模型(MF) | ❌ | ❌ | 简单高效 | 难以处理长期奖励 |
| 基于模型(MB) | ✅ | ✅ | 可预测未来,减少真实交互 | 模型可能不准确 |
✅ 使用建议:
- 状态空间小 → 用 Q-learning 或 Deep Q-learning
- 状态空间大或需要长期规划 → 用 MB 方法(如 MPC、蒙特卡洛等)
希望这篇文章能帮你理清这两类强化学习的核心区别,为后续深入学习打下坚实基础。