1. 简介
决策树是一种用于监督学习的贪心算法,广泛应用于分类和回归任务。它通过递归选择最优特征划分数据集,从而构建一棵从根节点到叶子节点的树结构。
在构建过程中,节点的划分质量直接影响最终模型的性能。为此,我们需要一种衡量节点“纯度”的方法 —— 节点不纯度(Node Impurity)。
2. 决策树的节点划分
在训练阶段,决策树会根据所有特征对节点进行划分,最终选择使划分后节点纯度最高(即不纯度最低)的方式。
通俗地讲,节点不纯度衡量了当前节点中标签的同质性。纯度越高,说明该节点中样本越可能属于同一类别。
以下图为例,从左到右分别是“高度不纯”、“中等不纯”和“纯节点”:
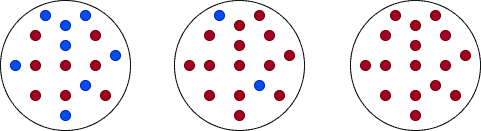
在分类任务中,常用的不纯度指标包括:
- Gini 不纯度(Gini Impurity)
- 信息熵(Entropy)
3. Gini 不纯度
Gini 不纯度是衡量一个节点中样本被错误分类的概率。
设数据集 $ T $ 包含 $ n $ 个类别的样本,其 Gini 不纯度定义为:
(1)
$$
gini(T) = 1 - \sum_{j=1}^{n} p_j^2
$$
其中 $ p_j $ 是类别 $ j $ 在数据集 $ T $ 中的频率。
✅ Gini 不纯度的取值范围
- 最小值为 0:节点中所有样本属于同一类别(纯节点)
- 最大值为 0.5:节点中样本类别分布最不均衡(最不纯)
3.1 示例:计算 Gini 不纯度
我们以一个包含红蓝两种球的集合为例,计算不同情况下的 Gini 不纯度:
| 红球数 | 蓝球数 | 计算公式 | Gini 值 |
|---|---|---|---|
| 4 | 0 | $ 1 - (1^2 + 0^2) $ | 0 |
| 2 | 2 | $ 1 - ((0.5)^2 + (0.5)^2) $ | 0.5 |
| 3 | 1 | $ 1 - ((0.75)^2 + (0.25)^2) $ | 0.375 |
4. 信息熵(Entropy)
信息熵是另一种衡量节点不纯度的方式,常用于信息论中。
设数据集 $ T $ 包含 $ n $ 个类别的样本,则其信息熵定义为:
(2)
$$
entropy(T) = - \sum_{j=1}^{n} p_j \cdot \log p_j
$$
✅ 信息熵的取值范围
- 最小值为 0:纯节点
- 最大值为 1:样本分布最不均衡
4.1 示例:计算信息熵
同样以红蓝球为例:
| 红球数 | 蓝球数 | 计算公式 | Entropy 值 |
|---|---|---|---|
| 4 | 0 | $ -1 \cdot \log 1 = 0 $ | 0 |
| 2 | 2 | $ -0.5 \cdot \log 0.5 - 0.5 \cdot \log 0.5 $ | 1.0 |
| 3 | 1 | $ -0.75 \cdot \log 0.75 - 0.25 \cdot \log 0.25 $ | 0.811 |
5. 数据划分策略
在训练决策树时,我们希望找到一个划分方式,使得划分后的子节点尽可能“纯”。
5.1 信息增益(Information Gain)
信息增益是指父节点的熵与子节点熵的加权平均之差。
设父节点 $ T $ 被划分为 $ m $ 个子节点 $ T_1, T_2, ..., T_m $,则信息增益定义为:
(3)
$$
Gain_{split}(T) = entropy(T) - \sum_{i=1}^{m} \frac{N_i}{N} \cdot entropy(T_i)
$$
其中 $ N_i $ 是子节点 $ T_i $ 的样本数,$ N $ 是总样本数。
5.2 示例:基于信息增益划分
我们以一个“是否打网球”的数据集为例:
| Day | Outlook | Temperature | Humidity | Wind | Play Tennis |
|---|---|---|---|---|---|
| D1 | Sunny | Hot | High | Weak | No |
| D2 | Sunny | Hot | High | Strong | No |
| D3 | Overcast | Hot | High | Weak | Yes |
| D4 | Rain | Mild | High | Weak | Yes |
| D5 | Rain | Cool | Normal | Weak | Yes |
| D6 | Rain | Cool | Normal | Strong | No |
| D7 | Overcast | Cool | Normal | Weak | Yes |
| D8 | Sunny | Mild | High | Weak | No |
| D9 | Sunny | Cool | Normal | Weak | Yes |
| D10 | Rain | Mild | Normal | Strong | Yes |
| D11 | Sunny | Mild | Normal | Strong | Yes |
| D12 | Overcast | Mild | High | Strong | Yes |
| D13 | Overcast | Hot | Normal | Weak | Yes |
| D14 | Rain | Mild | High | Strong | No |
该数据集包含 9 个“是”和 5 个“否”,初始熵为 0.94。
我们尝试按“Outlook”划分:
- Sunny: 2 Yes, 3 No → 熵为 0.971
- Overcast: 4 Yes, 0 No → 熵为 0
- Rain: 3 Yes, 2 No → 熵为 0.971
计算信息增益:
(5)
$$
Gain(S, Outlook) = 0.940 - \frac{5}{14} \cdot 0.971 - \frac{4}{14} \cdot 0 - \frac{5}{14} \cdot 0.971 = 0.247
$$
类似地,我们还可以计算其他属性的信息增益:
- Wind: 0.048
- Humidity: 0.151
- Temperature: 0.029
结论:Outlook 是信息增益最高的特征,应作为根节点划分属性
5.3 示例:基于 Gini 不纯度划分
我们同样可以使用 Gini 不纯度来评估划分质量。
计算 Outlook 的 Gini 不纯度:
- Sunny: Gini = 0.48
- Overcast: Gini = 0
- Rain: Gini = 0.48
加权平均:
(10)
$$
gini(Outlook) = \frac{5}{14} \cdot 0.48 + \frac{4}{14} \cdot 0 + \frac{5}{14} \cdot 0.48 = 0.343
$$
其他属性的 Gini 不纯度:
- Temperature: 0.423
- Humidity: 0.368
- Wind: 0.5
结论:Outlook 的 Gini 不纯度最低,仍应作为根节点
6. 总结
在构建决策树时,我们通过计算节点的不纯度来决定如何划分数据。常见的不纯度指标包括:
- Gini 不纯度
- 信息熵
通过选择划分后子节点不纯度最小的特征,我们可以构建出更精确的决策树模型。
✅ 关键点总结:
- 节点不纯度衡量样本的同质性
- Gini 不纯度和信息熵是两种常用指标
- 信息增益用于评估划分质量
- 选择划分特征时,优先选择信息增益最大或 Gini 不纯度最小的特征
通过合理使用这些指标,我们可以更高效地训练出性能良好的决策树模型。