1. 概述
本文将介绍生成模型的若干应用场景。我们先对生成模型做一个简要介绍,然后依次讲解其在数据增强、超分辨率、图像修复、去噪以及图像翻译等五个方面的应用,并结合实际案例和图片说明。
2. 什么是生成模型
生成模型的核心目标是学习输入数据的潜在分布 p(X),从而可以:
- 判断某个样本出现的可能性(概率建模)
- 生成与训练数据相似的新样本(样本生成)
其中,GAN(生成对抗网络) 是目前最知名的生成模型之一。它通过两个网络(生成器和判别器)在零和博弈中相互对抗来学习数据分布。
✅ GAN 的基本原理可参考我们之前的文章:GAN 原理详解
3. 数据增强(Data Augmentation)
在训练数据不足或标注成本较高的场景下,使用生成模型可以有效生成高质量的合成数据,从而提升模型泛化能力。
一个典型的例子是 StyleGAN,由 NVIDIA 提出,可以生成逼真的人脸图像:

这些图像中的人现实中并不存在,但视觉效果几乎与真实人脸无异。StyleGAN 还支持风格控制,比如将 A 的面部风格应用到 B 的面部结构上:

⚠️ 踩坑提醒:使用生成数据时要注意数据偏移问题,避免引入偏差。
4. 超分辨率(Super Resolution)
超分辨率任务的目标是从低分辨率图像中重建出高分辨率图像,在医学成像、卫星图像、视频增强等领域有广泛应用。
SRGAN 是一个成功的生成模型,它结合了深度网络和对抗训练机制,能从低分辨率图像中恢复出高质量的高清图像:
| 输入低分辨率 | SRGAN 生成 | 真实高分辨率 |
|---|---|---|
 |
 |
 |
可以看到,SRGAN 生成的图像在视觉质量上与真实高清图像非常接近。
5. 图像修复(Inpainting)
图像修复的任务是填充图像中缺失或被遮挡的区域,同时保持图像整体的语义一致性和视觉自然性。
DeepFill 是一个基于生成模型的开源图像修复框架,其核心创新在于引入了上下文注意力机制(Contextual Attention),使得模型可以从图像的其他区域获取信息来填充缺失部分。
以下是一些修复效果示例:

无论是自然场景、人脸还是纹理图像,DeepFill 都能实现高质量的修复。
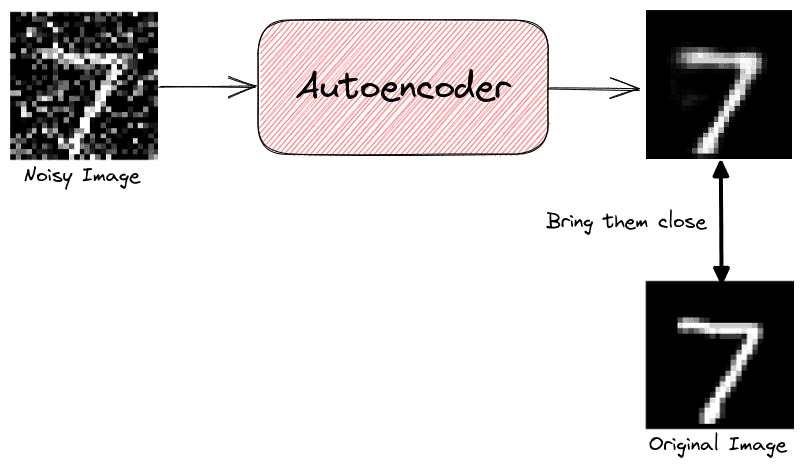
6. 图像去噪(Denoising)
尽管现代相机可以拍摄高质量图像,但在弱光或高 ISO 情况下仍可能出现噪点。图像去噪的目标是在保留图像细节的前提下去除噪声。
一种常用方法是使用 Autoencoder(自编码器),其训练流程如下:
- 输入:原始图像 + 带噪图像
- 输出:去噪后的图像
- 目标:输出尽可能接近原始图像
训练完成后,模型可以自动去除图像中的噪声:
7. 图像翻译(Image Translation)
图像翻译的目标是在两个图像域之间建立映射关系,从而实现图像风格或内容的转换。例如:
- 冬天 → 夏天
- 马 → 斑马
- 灰度图 → 彩色图
7.1 风格迁移(Style Transfer)
使用 CycleGAN 可以将风景图转换为著名画家的风格,如莫奈、梵高、塞尚等:

7.2 对象转换(Object Transfiguration)
CycleGAN 还可以实现对象级别的转换,比如:
- 马 ↔ 斑马
- 苹果 ↔ 橙子
- 冬季景观 ↔ 夏季景观

7.3 图像上色(Colorization)
CycleGAN 也可用于自动为黑白图像上色,这对老照片修复非常有用:

8. 总结
本文介绍了生成模型在多个领域的应用,包括:
| 应用场景 | 代表模型 | 应用价值 |
|---|---|---|
| 数据增强 | StyleGAN | 扩充数据集,提升模型表现 |
| 超分辨率 | SRGAN | 提升图像清晰度 |
| 图像修复 | DeepFill | 修复缺失区域,保持一致性 |
| 图像去噪 | Autoencoder | 去除噪声,保留图像细节 |
| 图像翻译 | CycleGAN | 实现风格迁移、对象转换、上色 |
生成模型正逐步成为图像处理和计算机视觉领域不可或缺的工具。随着模型结构和训练方法的不断演进,未来还有更多令人期待的应用场景等待我们去探索。