1. 引言
在本教程中,我们将介绍如何验证神经网络或其他机器学习模型的性能。首先,我们会简要介绍神经网络的基本概念,接着解释什么是模型验证以及常见的验证策略。最后,我们会重点讲解一种特别有效的验证方法 —— K 折交叉验证(K-Fold Cross-Validation),并介绍其一些变种。
模型验证是构建机器学习系统中不可或缺的一环,因为模型的泛化能力直接依赖于验证过程的严谨性。
2. 神经网络简介
神经网络是一类受生物神经网络启发而设计的算法模型。其核心是由大量相互连接的“神经元”组成,这些神经元根据网络类型以不同方式连接。最初的设计目标是模拟人类大脑的学习与推理能力。
常见的神经网络类型主要包括:
- 前馈神经网络(Feedforward Neural Networks)
- 卷积神经网络(Convolutional Neural Networks)
- 循环神经网络(Recurrent Neural Networks)
它们之间的主要区别在于神经元的结构和信息在网络中的传播方式。为了评估神经网络的预测效果,我们需要使用合适的验证方法,这正是我们接下来要讨论的内容。
3. 模型验证
在训练神经网络并使用测试集生成预测结果后,我们需要评估这些结果的准确性。
3.1 机器学习评估指标
通常,我们使用特定的评估指标来衡量模型性能。这些指标分为“误差类”和“准确率类”:
误差类:适用于回归问题,如:
- 均方误差(MSE)
- 均方根误差(RMSE)
- 平均绝对误差(MAE)
准确率类:适用于分类问题,如:
- 准确率(Accuracy)
- 精确率(Precision)
- 召回率(Recall)
- F1 分数(F1 Score)
如果分类模型输出的是类别概率(而非硬分类),我们还可以使用:
- AUC(曲线下面积)
- 交叉熵(Cross-Entropy)
这些指标是使用最广泛的,当然也有其他更专业的评估方法可供选择。
3.2 欠拟合与过拟合
选择评估指标后,我们需要设计验证策略。一个经典的做法是将数据集划分为训练集和测试集。但需要注意的是:模型在训练集上表现好,并不代表它在新数据上也能表现良好。
验证的核心目的,是尽可能准确地估计模型在未知数据上的表现。因此,我们必须注意模型是否出现 欠拟合 或 过拟合 的情况。
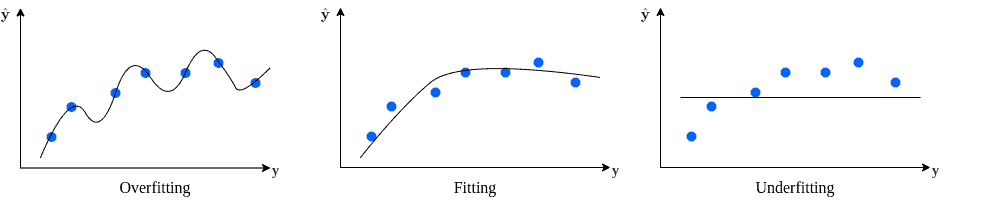
- 欠拟合(Underfitting):模型在训练集和测试集上都表现不佳。通常意味着模型没有充分学习到数据特征,属于高偏差、低方差。
- 过拟合(Overfitting):模型在训练集上表现很好,但在测试集上表现差。说明模型“记住了”训练数据,属于低偏差、高方差。
下图展示了随着训练轮数增加,偏差和方差的变化趋势:
4. K 折交叉验证
将数据集简单划分为训练集和测试集的一个显著问题是:测试集的分布可能无法代表整体数据分布,尤其是在类别不平衡或特征分布不均的情况下。
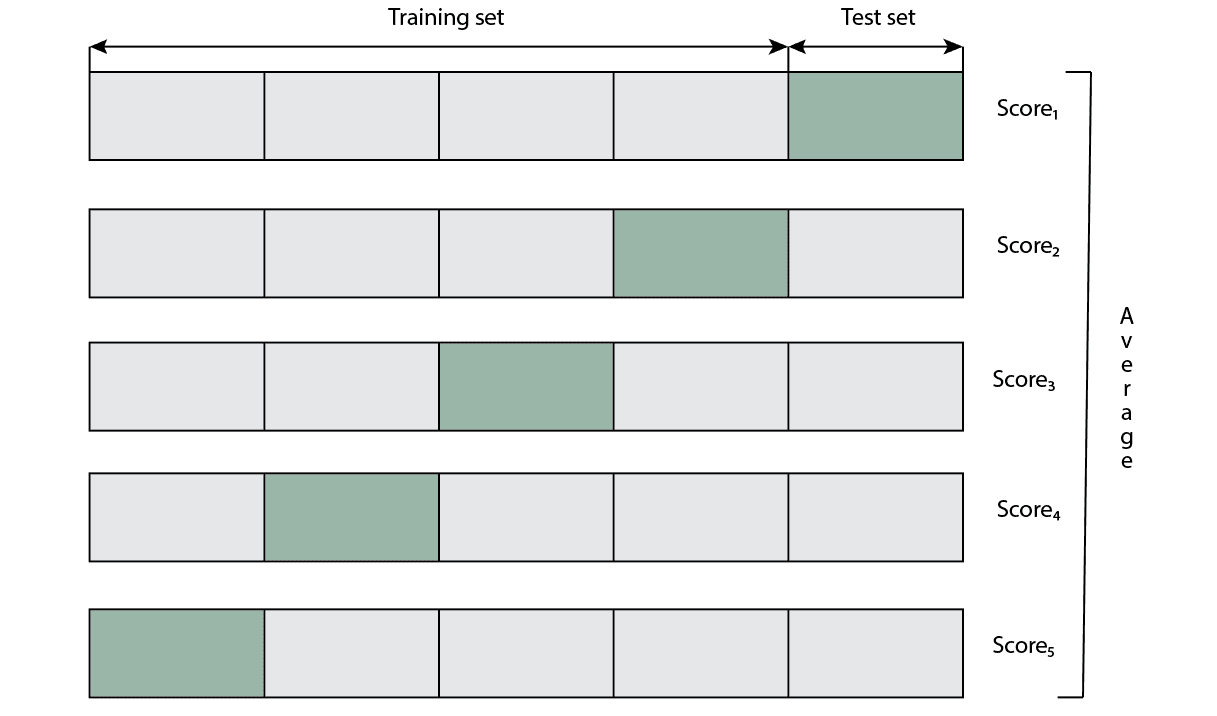
K 折交叉验证(K-Fold Cross-Validation)是一种更稳健的验证策略。它的核心思想是:将数据平均分为 K 个子集(称为“折”),每次使用其中一个子集作为测试集,其余 K-1 个子集作为训练集。这个过程重复 K 次,每个子集都有机会作为测试集。
- K 通常取 3 到 10 之间的整数。
- 每次训练后使用测试集评估模型性能。
- 最终取 K 次评估结果的平均值作为最终性能指标。
这种方法的优点是每个样本都会被用作一次测试样本,从而提高了评估的稳定性。
下图展示了 K 折交叉验证的流程:
除了标准的 K 折交叉验证,还有一些常见的变种,适用于不同场景。
4.1 留一法交叉验证(Leave-One-Out, LOO)
这是 K 折交叉验证的一种极端形式,其中 K 等于样本总数。每次测试只留一个样本作为测试集,其余全部用于训练。
✅ 优点:充分利用数据,评估结果更稳定
❌ 缺点:计算开销极大,尤其当数据量大时
4.2 分层 K 折交叉验证(Stratified K-Fold)
适用于类别不平衡的数据集。例如在垃圾邮件分类任务中,正常邮件远多于垃圾邮件。
Stratified K-Fold 在划分每个子集时,确保每个子集的类别分布与整体数据集一致。
✅ 优点:在类别不平衡时更可靠
⚠️ 适用场景:分类任务中类别分布不均时
4.3 重复 K 折交叉验证(Repeated K-Fold)
该方法重复多次 K 折交叉验证,并在每次划分时随机打乱数据顺序。这样可以减少由于划分方式不同导致的评估偏差。
✅ 优点:多次重复提升评估稳定性
⚠️ 适用场景:需要更稳健的模型评估
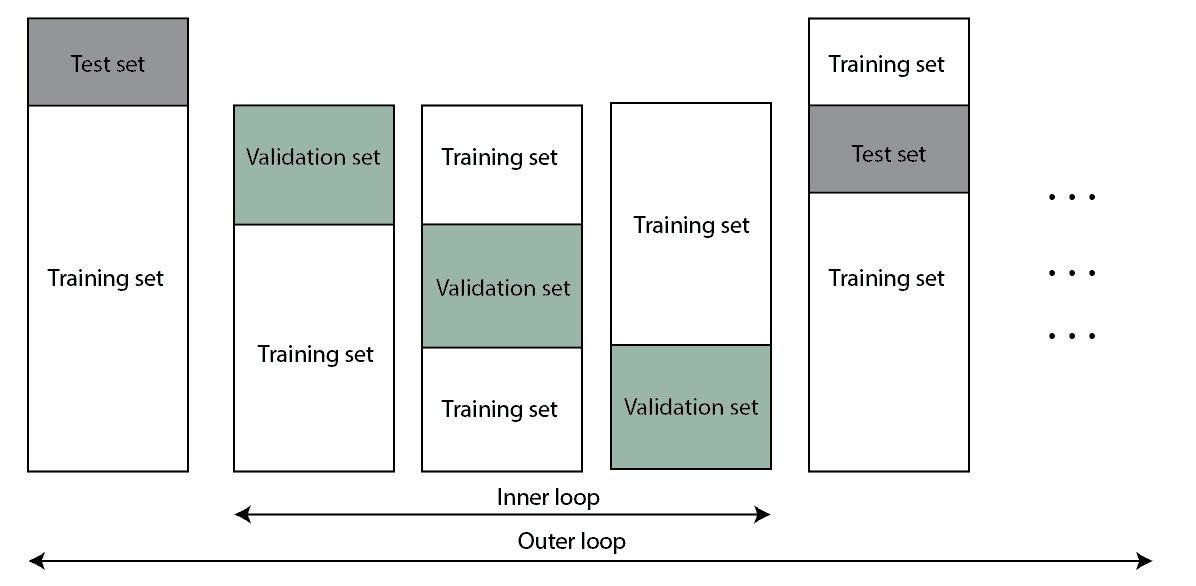
4.4 嵌套 K 折交叉验证(Nested K-Fold)
主要用于超参数调优(Hyperparameter Tuning)。它包含两个嵌套的 K 折验证过程:
- 外层用于模型评估
- 内层用于超参数选择
这样可以避免因使用相同数据集进行调参和评估而导致的偏差。
✅ 优点:减少信息泄露,提高调参准确性
❌ 缺点:计算成本高
⚠️ 适用场景:需要严谨的模型调参流程
下面是一个伪代码示例,展示嵌套 K 折交叉验证的执行流程:
algorithm NestedKFoldCrossValidation(D, P_sets, K1, K2):
// INPUT
// D = the dataset
// P_sets = all hyperparameters combinations for testing
// K1 = the number of outer folds
// K2 = the number of inner folds
// OUTPUT
// Error estimation using nested k-fold cross-validation
test_errors <- make an empty array with place for K1 numbers
for i <- 1 to K1:
Split D into D_i_train and D_i_test
for j <- 1 to K2 splits:
Split D_i_train into D_j_train and D_j_test
for p in P_sets:
Train model M on D_j_train using hyperparameters p
Compute test error E_j_test for M with D_j_test
p* <- the optimal hyperparameter set p* from P_sets with the best value of E_j_test
Train M with D_i_train using p*
Compute test error E_i_test for M with D_i_test
test_errors[i] <- E_i_test
return aggregate(test_errors)
嵌套交叉验证流程图如下:
5. 总结
模型验证是机器学习流程中至关重要的一环。一个不严谨的验证过程可能导致模型偏差,甚至误导后续决策。
本文介绍了几种常用的交叉验证方法,包括:
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 留一法(LOO) | 数据量小 | 几乎无偏差 | 计算量大 |
| 分层 K 折 | 类别不平衡 | 保持分布一致性 | 仅适用于分类 |
| 重复 K 折 | 需要更稳定评估 | 提升评估稳定性 | 增加计算时间 |
| 嵌套 K 折 | 超参数调优 | 避免信息泄露 | 计算复杂度高 |
✅ 建议:如果计算资源允许,推荐使用嵌套 K 折交叉验证。对于大多数场景,标准 K 折交叉验证已经足够有效。