1. 缓存简介
缓存(Cache)是一个泛用性术语,在不同上下文中含义不同。它可以指 CPU 缓存、磁盘缓存、数据库缓存,甚至是浏览器缓存。
缓存本质上是一种临时存储机制,其访问速度远高于原始数据源。 例如,当应用从远程服务器下载文件时,本地磁盘可以作为远程文件的缓存;而对于频繁读取本地文件的应用来说,最常访问的数据会被缓存在 CPU 缓存或内存中。
在性能敏感的场景中,我们应尽量写出能充分利用缓存的代码。这种代码我们称之为“缓存友好型代码”。
2. 代码分类
在实际开发中,很多时候代码或数据量太大,无法完全装入缓存。此时数据必须频繁在系统内存和缓存之间传输,导致性能下降。
根据是否能充分利用缓存,代码可分为两类:
- ✅ 缓存友好型(Cache-Friendly)
- ❌ 缓存不友好型(Cache-Unfriendly)
3. 缓存友好型代码
缓存友好型代码是指能高效利用缓存、提升命中率的代码。
缓存命中率越高,程序执行效率越高。如下图所示:
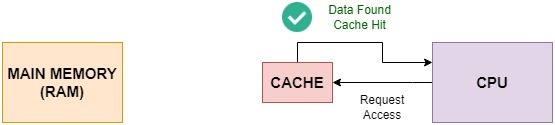
3.1 使用连续内存结构
为了提升缓存利用率,我们应尽量将数据存储在连续内存中。 这样一来,当程序访问第一个数据时,后续可能用到的数据也会被一并加载进缓存。
举个例子:在读取数组第一个元素时,整个数组就可能被一次性加载进缓存。
这与我们选择的数据结构密切相关。例如:
- ❌ 链表中的节点可能分散在内存各处,不利于缓存;
- ✅ 数组中的元素是连续存储的,更利于缓存命中。
3.2 避免复杂循环结构
尽量避免大循环体,将其拆分为多个小循环。
原因在于:如果循环体中访问的数据量太大,那么在一次迭代结束时,早期加载的数据可能已经被替换出缓存。当下次迭代再次访问这些数据时,就会发生缓存未命中(Cache Miss)。
3.3 减少函数调用栈
保持函数调用栈尽可能小,避免不必要的递归调用。
如果递归调用参数占用大量内存,系统将难以将它们全部装入缓存,导致频繁的内存数据交换,影响性能。
3.4 缓存友好的设计模式
在设计应用时,应优先选择适合缓存块大小的数据结构。此外,应设计算法以连续块的方式读取和处理数据,且块大小应与缓存行(Cache Line)匹配。
例如:
- ✅ 使用二维数组(矩阵)作为数据结构;
- 将矩阵的行数设置为一个缓存行的大小,从而提升缓存利用率。
以下代码展示了如何按行访问图像像素以提升缓存效率:
algorithm AlignDataWithCache(image, m, n):
// INPUT
// image = 待处理的图像位图
// m = 行数(等于缓存行大小)
// n = 列数
// OUTPUT
// 经过缓存优化处理后的图像
for j <- 1 to n:
for i <- 1 to m:
pixel <- image[j, i]
Process pixel
⚠️ 如果按列访问,则会频繁发生缓存未命中,因为同一列的元素在内存中并不连续。
3.5 使用缓存友好的语言结构
使用语言中自带的缓存友好结构,如数组,而非链表或哈希表。
数组在内存中是连续存储的,因此更利于缓存命中。
3.6 避免无序跳转
避免过多的 if-else 分支或条件跳转。 它不仅使代码难以理解,也增加了编译器优化的难度,还可能因分支预测失败导致性能下降。
示例:
algorithm BranchesAndCache(words, language):
// INPUT
// words = 待检查的单词列表
// language = 目标语言(英语或法语)
// OUTPUT
// 检查单词是否存在于指定语言词典中
for word in words:
if language = English:
dictionary <- load the English dictionary
else:
dictionary <- load the French dictionary
Check if word is in dictionary
✅ 优化建议:提前加载常用语言的词典,减少缓存缺失。
3.7 使用编译器优化选项
通过设置合适的编译器选项,可以让生成的二进制代码更缓存友好。
例如 GCC 编译器支持 -mtune 选项,可以优化内存管理部分以适配目标 CPU 架构,从而减少缓存未命中。
4. 缓存不友好型代码
如果代码没有充分利用缓存资源,我们就称其为缓存不友好型代码。
常见特征包括:
- ✅ 大量无序跳转(如过多的 if-else)
- ✅ 函数调用频繁,参数占用内存大
- ✅ 高度递归
- ✅ 不及时释放内存
- ✅ 随机内存访问(如链表)
4.1 缓存未命中
缓存未命中(Cache Miss)是缓存不友好代码的直接表现。程序访问的数据不在缓存中,需从内存甚至磁盘中加载,导致延迟增加。
如下图所示:
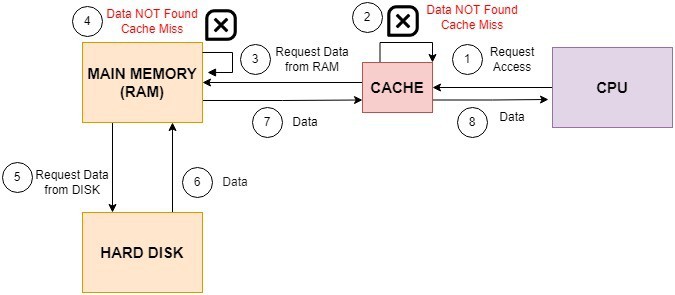
流程简述:
- CPU 请求数据;
- 缓存中未找到,触发缓存未命中;
- 从内存中加载数据;
- 若内存中也找不到,需从磁盘加载;
- 数据加载完成后,依次写入缓存并返回给 CPU。
5. 缓存友好型代码的特征
5.1 局部性引用(Reference Locality)
局部性引用是缓存友好代码的核心特征,包括:
- 空间局部性(Spatial Locality):程序倾向于访问地址相邻的数据;
- 时间局部性(Temporal Locality):程序倾向于在短时间内重复访问同一数据。
✅ 示例:空间局部性
线性查找比二分查找在小数组中更快,正是因为缓存可以一次性加载整个数组。
✅ 示例:时间局部性
以下代码展示了良好的时间局部性:
algorithm TemporalLocality(a, b, c, d):
// INPUT
// a, b, c, d = 待处理的向量
// OUTPUT
// 向量加法结果,展示时间局部性
result1 <- a + b
result2 <- c + d
result <- pair(result1, result2)
return result
但如果在两次加法之间插入其他操作,可能导致中间结果被缓存淘汰:
algorithm NoTemporalLocality(a, b, c, d):
// INPUT
// a, b, c, d = 待处理的向量
// OUTPUT
// 向量加法结果,但破坏了时间局部性
result1 <- a + b
// 中间插入其他操作,可能导致 a, b 被移出缓存
result2 <- c + d
// 同样,可能导致 c, d 被移出缓存
result <- pair(result1, result2)
return result
5.2 预取机制(Prefetching)
现代处理器支持预取指令,可以提前将即将使用的数据加载进缓存。
例如:
- Intel 处理器有 L2 硬件预取器,可自动分析内存访问模式并发起预取请求。
6. 总结
缓存是影响程序性能的关键因素之一。编写缓存友好型代码可以显著提升程序执行效率。
主要实践建议包括:
- ✅ 使用连续内存结构(如数组);
- ✅ 避免大循环体,拆分逻辑;
- ✅ 减少递归和栈调用;
- ✅ 设计缓存友好的数据结构;
- ✅ 避免无序跳转;
- ✅ 利用编译器优化;
- ✅ 利用预取机制。
掌握这些技巧,有助于你在性能敏感场景下写出更高效的代码。