1. 概述
本文将深入讲解 Brewer 提出的 CAP 定理,并探讨分布式系统设计中的一系列核心问题。我们将了解 CAP 定理的含义、应用场景以及其局限性,并介绍当前一些替代方案。适合有一定分布式系统基础的开发人员参考。
2. CAP 定理解析
2.1. 起源
CAP 定理最早由 Eric Brewer 于 2000 年提出,称为 CAP 假设。该假设指出,在分布式系统中,一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)三者不可兼得。直到 2002 年,这一假设才被其他计算机科学家形式化证明。
Brewer 当初提出这个定理的目的,是希望推动业界对分布式系统设计中权衡问题的讨论。
2.2. 三个核心概念定义
CAP 是 Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容忍性)的缩写。我们来用通俗语言解释这三个特性:
- ✅ Consistency(一致性):所有读操作都能获取到最新的数据。系统中所有节点看到的数据都是一致的。
- ✅ Availability(可用性):系统在任何情况下都可用。即使部分节点宕机,系统仍然可以响应请求。
- ✅ Partition Tolerance(分区容忍性):系统在网络分区(节点间通信中断)的情况下仍能继续运行。
2.3. 定理内容
CAP 定理指出:一个分布式系统最多只能同时满足一致性、可用性和分区容忍性中的两个。
也就是说,系统只能是以下三者之一:
- CA 系统:保证一致性和可用性,但无法容忍分区
- AP 系统:保证可用性和分区容忍性,但可能牺牲一致性
- CP 系统:保证一致性和分区容忍性,但可能牺牲可用性
⚠️ 注意:不存在同时满足 C、A、P 的系统。
3. 数据库与 CAP
为了更好地理解 CAP 定理在实际系统中的体现,我们先介绍一个关键概念:数据复制(Replication)
3.1. 数据复制机制
数据复制是数据库扩展的一种常见手段。 它通过将一个数据库节点的数据复制到多个副本节点上,从而实现负载均衡和容错。
常见的复制方式有:
- 主从复制(Master-Slave):主节点负责写操作,副本节点负责读操作
- 多主复制(Master-Master):多个节点都可以进行读写操作
这种方式可以提升系统的可用性和一致性,但也增加了数据同步的复杂性。
3.2. 数据库分类对比
下图展示了一些常见数据库在 CAP 模型下的分类:
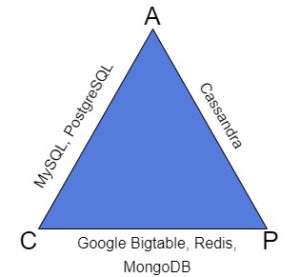
✅ CA 系统
例如 PostgreSQL。通过主从复制和两阶段提交机制实现强一致性与高可用性。但在网络分区时无法保证一致性。✅ AP 系统
例如 Cassandra。使用多主复制机制,具备高可用性和分区容忍性,但在分区期间可能容忍数据不一致。✅ CP 系统
例如 MongoDB。通过单一主节点写入保证一致性,在分区时拒绝写入请求,牺牲可用性以保证数据一致性。
4. 简单分布式系统设计示例
为了更直观地理解 CAP 定理,我们通过一个简单的日志服务场景来模拟三种系统类型。
4.1. AP 系统示例
假设我们和一个朋友分别接听客户电话并记录信息,各自使用独立的笔记本。
客户第一次打电话告诉我们他妻子的生日,我们记录在自己的笔记本中。几个月后客户再次打电话,这次朋友接听,但他的笔记本中没有这条信息,导致客户不满。
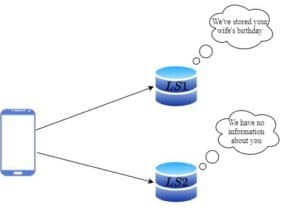
这个系统具备可用性(即使一方不在线,服务仍可用)和分区容忍性(两个笔记本独立工作),但不保证一致性,因此是 AP 系统。
4.2. CP 系统示例
为了解决一致性问题,我们决定每次记录信息后立即打电话同步给对方。如果对方无法接听,就发邮件记录,等对方回来再补同步。
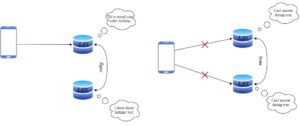
此时系统具备一致性(信息最终同步)和分区容忍性(即使断开联系也能继续工作),但在同步期间服务不可用,因此是 CP 系统。
4.3. CA 系统示例
朋友离职后,只剩我们一个人工作。只有一个笔记本和一部电话,所有信息都记录在同一个地方。

此时系统具备一致性(只有一个数据源)和可用性(随时响应请求),但不具备分区容忍性,因此是 CA 系统。
4.4. 小结
这个例子说明:没有完美的系统,必须根据业务需求在 C、A、P 之间做权衡。
5. CAP 的问题与替代方案
5.1. CAP 定理的局限性
尽管 CAP 定理广为人知,但在实际应用中也存在一些问题:
- ❌ 可用性定义模糊:CAP 中的可用性不考虑响应时间,也不支持“部分可用”概念
- ❌ 一致性粒度粗:没有区分最终一致性与强一致性
- ❌ 分区容忍性定义不明确:网络分区在现实中是常态,CAP 没有提供更细粒度的指导
5.2. PACELC 定理简介
PACELC 是 CAP 的扩展和改进版本,更贴近实际场景。
其核心规则如下:
“如果系统是分区容忍的(P),那么必须在可用性(A)和一致性(C)之间做选择;否则(非分区状态),要在一致性(C)和低延迟(L)之间做选择。”
这一定理更贴近现实,适用于大多数分布式系统的设计。
6. 总结
本文讲解了 Brewer 的 CAP 定理及其在分布式系统设计中的应用。我们了解到:
- ✅ CAP 定理揭示了分布式系统设计中的核心权衡关系
- ✅ 没有系统能同时满足一致性、可用性和分区容忍性
- ✅ 不同数据库根据其定位选择不同的 CAP 组合
- ✅ CAP 有局限性,PACELC 提供了更现实的替代方案
在设计系统时,应根据业务需求选择合适的权衡方式,而不是盲目追求“全都要”。在实际工程中,最终一致性 + 高可用性 + 分区容忍性的组合(AP)是最常见的选择,尤其是在大规模分布式系统中。