1. 概述
在图论中,判断一个图中哪些节点可以从起始节点到达,是一个非常基础且重要的问题。本文我们将围绕一个具体问题展开:如何判断图中两个节点是否连通?
我们会分别讨论在有向图和无向图中的处理方式,并给出两种解决方案:
- 基于 DFS 的朴素方法
- 预处理连通分量的方法(仅适用于无向图)
最后我们还会做一个总结对比,说明每种方法的适用场景和性能差异。
2. 问题定义
我们给定一个包含 n 个节点和 m 条边的图,需要处理多个查询。每个查询给出两个节点 u 和 v,要求我们判断是否可以从 u 出发到达 v。
由于有向图和无向图在边的方向性上存在差异,因此需要分别讨论。
2.1 有向图
看下面这个有向图的例子:
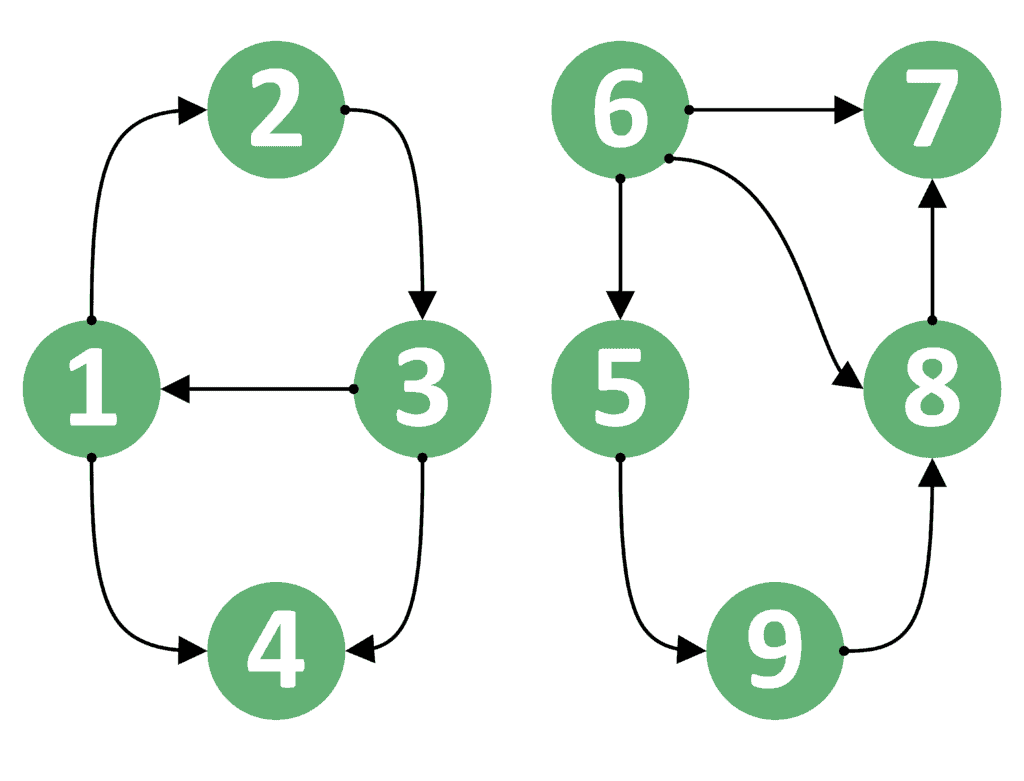
- 若
u=1、v=3:可以走路径1 → 2 → 3,返回true - 若
u=3、v=1:存在直接边3 → 1,返回true - 若
u=1、v=4:可以走路径1 → 2 → 3 → 4,返回true - 若
u=4、v=1:无法到达,返回false
这说明在有向图中,起点和终点的顺序非常重要,不能随意交换。
2.2 无向图
将上面的例子中所有边改为无向边,得到如下图:
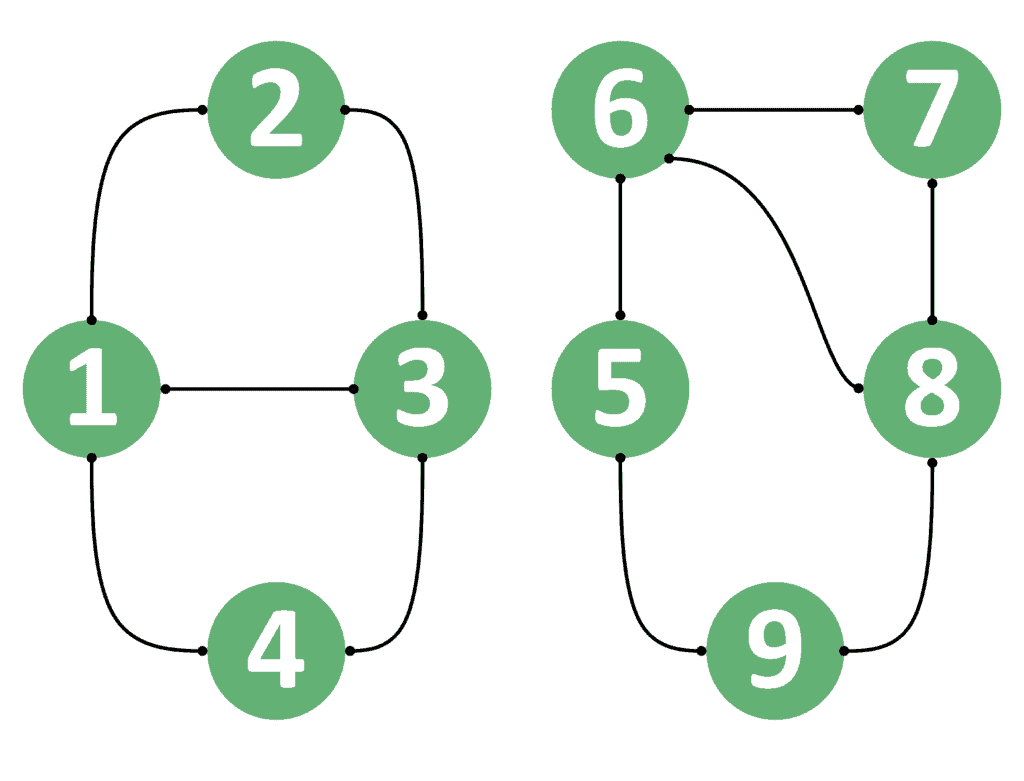
- 若
u=1、v=3:可以走路径1 - 2 - 3,返回true - 若
u=3、v=1:路径相同,返回true - 若
u=1、v=8:无法到达,返回false - 若
u=8、v=1:同样无法到达,返回false
结论是:无向图中若两个节点连通,则双向都可到达。
3. 朴素方法(DFS)
对于每个查询 (u, v),我们可以使用深度优先搜索(DFS)从 u 出发,尝试是否能到达 v。
✅ 优点:适用于有向图和无向图
❌ 缺点:每次查询都要重新 DFS,效率较低
示例代码(Java)
boolean naiveApproach(List<Integer>[] graph, int u, int v) {
boolean[] visited = new boolean[graph.length];
return dfs(graph, u, v, visited);
}
boolean dfs(List<Integer>[] graph, int u, int v, boolean[] visited) {
if (u == v) return true;
if (visited[u]) return false;
visited[u] = true;
for (int next : graph[u]) {
if (dfs(graph, next, v, visited)) {
return true;
}
}
return false;
}
时间复杂度
- 每次查询:
O(n + m) - 若有
q次查询,总复杂度为:O(q * (n + m))
⚠️ 当查询次数较多时,这种做法会变得很慢。
4. 连通分量预处理法(仅适用于无向图)
对于无向图,我们可以利用连通分量的性质:同一连通分量内的节点之间两两可达。
我们可以预先对图进行一次 DFS,把所有节点划分为若干个连通分量,并为每个节点打上分量标签。之后每次查询只需比较两个节点的标签是否一致。
✅ 优点:预处理后每次查询只需 O(1)
❌ 缺点:仅适用于无向图
4.1 预处理步骤
int[] precomputeComponentIDs(List<Integer>[] graph, int n) {
boolean[] visited = new boolean[n];
int[] componentID = new int[n];
Arrays.fill(componentID, -1);
int currentID = 0;
for (int u = 0; u < n; u++) {
if (!visited[u]) {
dfs(graph, u, visited, componentID, currentID++);
}
}
return componentID;
}
void dfs(List<Integer>[] graph, int u, boolean[] visited, int[] componentID, int currentID) {
if (visited[u]) return;
visited[u] = true;
componentID[u] = currentID;
for (int v : graph[u]) {
dfs(graph, v, visited, componentID, currentID);
}
}
4.2 查询处理
boolean isReachable(int u, int v, int[] componentID) {
return componentID[u] == componentID[v];
}
时间复杂度
- 预处理:
O(n + m) - 每次查询:
O(1)
✅ 适用于查询次数较多的场景
5. 方法对比
| 方法 | 主要思想 | 适用图类型 | 预处理复杂度 | 查询复杂度 |
|---|---|---|---|---|
| DFS 朴素方法 | 每次查询都从起点 DFS | 有向 & 无向 | 无 | O(n + m) |
| 连通分量预处理 | 预处理每个节点所属分量 | 仅无向 | O(n + m) |
O(1) |
使用建议
- 有向图:只能使用 DFS 朴素方法
- 无向图:
- 查询次数少 → 用 DFS
- 查询次数多 → 预处理连通分量
6. 总结
本文介绍了如何判断图中两个节点是否连通的问题,重点分析了:
- 有向图和无向图在路径可达性上的差异
- 使用 DFS 的朴素方法(通用)
- 使用连通分量的优化方法(仅适用于无向图)
最终得出结论:
✅ 无向图中,使用连通分量预处理可显著提升查询效率
❌ 有向图中,只能使用 DFS 逐次查询
根据实际场景选择合适的方法,才能兼顾代码性能和实现复杂度。