1. 引言
在本文中,我们将学习协程(Coroutines)这一概念。
协程是一种支持协作式并发编程的结构,几乎所有的现代编程语言都提供了对协程的支持。它们提供了一种轻量级的并发方式,比传统的线程和进程更高效。
2. 多任务处理
在软件层面,我们可以通过进程(Process)、线程(Thread) 和 协程(Coroutine) 来实现并发,从而比顺序执行更快地解决多个任务。
进程的缺点:
- 进程是重量级的结构。操作系统为每个进程分配独立的地址空间,以确保安全隔离。
- 进程切换开销大,因为每个进程都需要完整的一套资源(如堆栈、堆内存、数据段、指令等)。
- 创建新进程代价高昂,无论是时间还是系统资源上。
- 进程间通信(IPC)相比线程间通信更复杂、更慢。
线程 vs 协程:
- 线程相比进程更轻量,但依然需要操作系统调度。
- 协程则完全在用户空间运行,资源消耗更少,上下文切换速度更快。
- 协程不依赖操作系统调度,无需锁、互斥量等同步机制。
3. 协程概述
协程是一种协作式执行的函数或方法。它通过主动让出控制权来与其他协程配合工作,而不是像线程那样被抢占式调度。
协程运行在用户空间,因此不需要同步原语(如 mutex、semaphore、lock 等)。
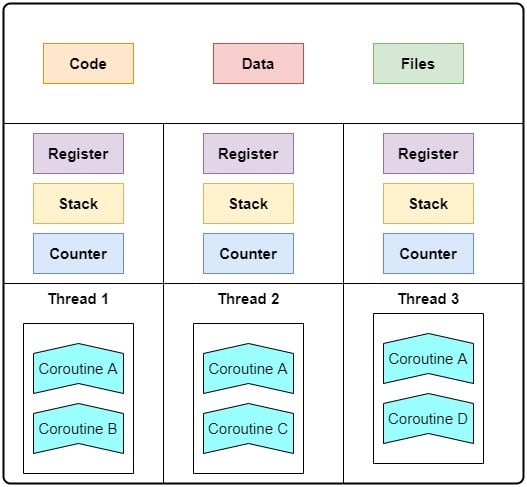
3.1 协程与线程的区别
- 协程没有独立的栈结构,因此比线程更轻量。
- 协程由用户调度,不依赖操作系统调度器,也不绑定内核线程。
- 一个线程可以运行多个协程,协程之间通过主动挂起来切换。
如下图所示,协程可以在多个线程之间被调用:
4. 协程如何协作
协程通过主动释放 CPU 实现协作式多任务处理。
每个协程可以在适当的时候暂停自己,把控制权交给其他协程。这种协作方式避免了资源竞争,也简化了并发逻辑。
4.1 示例
假设我们有一个微服务,接收用户输入、处理数据、查询数据库、最终返回结果。
数据库的读写是阻塞操作。此时,处理数据库的协程可以主动将控制权交还给主线程,而不是等待响应。主线程可以借此处理其他用户的请求,或调用另一个协程完成其他任务。
✅ 这种协作机制使得多个任务能够高效协同,加速整个流程。
4.2 协程内部机制
协程由一个协作式调度器启动。它们不会像线程一样被强制切换,而是主动让出控制权。开发者可以在代码中设置切换点,使协程在适当的位置释放控制权。
✅ 这种机制提升了并发性,避免了回调地狱(callback hell)。
5. 协程示例
我们通过一个实际例子来加深理解。
假设我们有一个应用,其任务如下:
- 从文本文件中读取 N 个 URL。
- 对每个 URL 发起 HTTP GET 请求,下载视频并保存到本地。
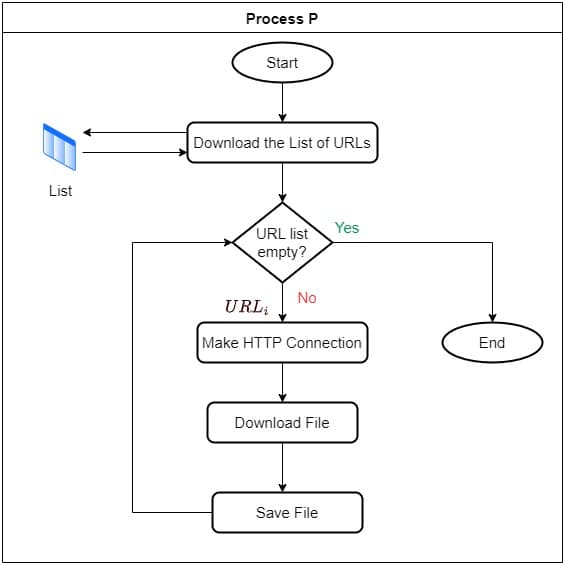
5.1 使用进程实现
如果不使用线程或协程,只能顺序执行:
- 读取所有 URL。
- 依次发起请求并下载文件。
- 每次请求都会阻塞程序直到完成。
⚠️ 这种方式效率极低,因为每个请求都会阻塞后续任务。
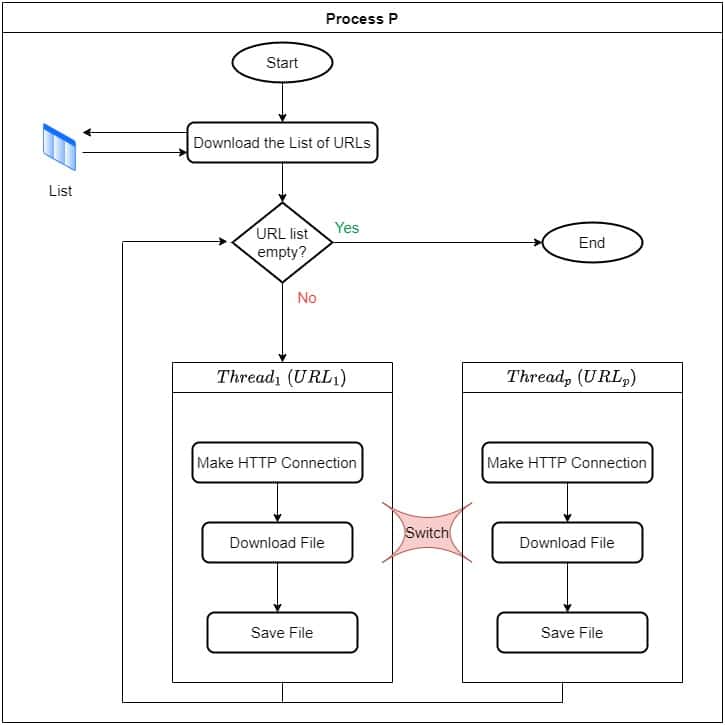
5.2 使用线程实现
我们可以创建多个线程,每个线程处理一部分 URL:
- 主线程读取所有 URL。
- 启动多个线程并行处理。
- 每个线程独立发起请求、下载文件。
这种方式是非阻塞且并发的,但存在以下问题:
- 线程切换开销大。
- 需要系统调用。
- 线程间需要同步机制。
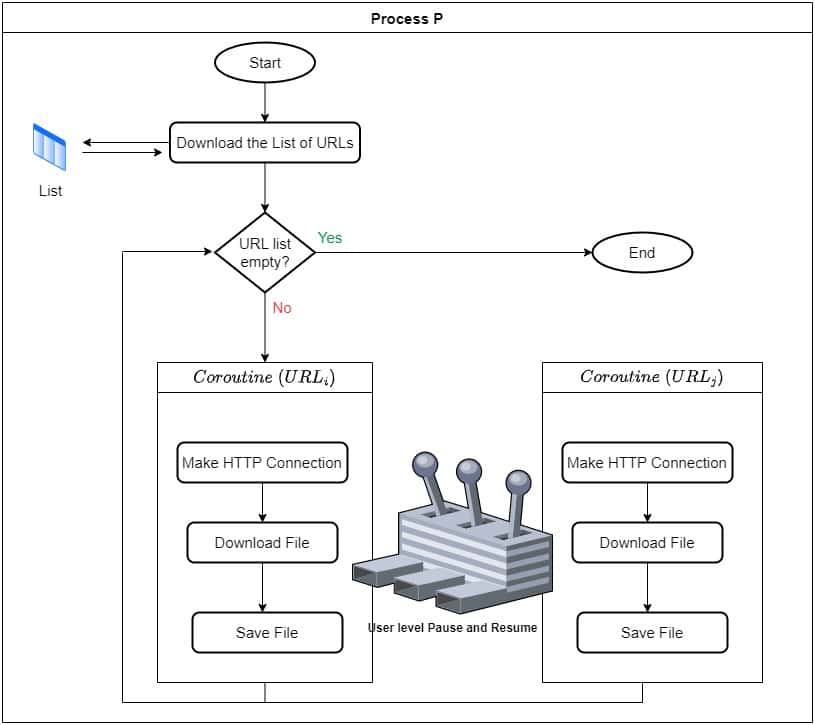
5.3 使用协程实现
主进程读取 URL 后,启动多个协程分别处理每个 URL:
- 每个协程负责一个 URL 的请求与下载。
- 当协程发起网络请求时,主动让出控制权。
- 主线程可以继续执行其他协程,而不是等待。
✅ 所有协程合作完成任务,效率高、无阻塞、资源消耗低。
6. 协程的优势
下面列出协程的几大优势,适用于各种并发场景。
6.1 异步编程
- 协程可将阻塞调用分解为异步调用。
- 主流程启动协程后可继续处理其他任务。
- 协程运行在非抢占模式下,主动释放 CPU。
✅ 无需阻塞等待,提升响应速度。
6.2 提升并发能力
- 协程是轻量级的函数,使用系统栈保存上下文。
- 不需要创建和销毁开销。
- 无需操作系统调度,资源消耗低。
✅ 协程是多线程之外更高效的并发选择。
6.3 互斥性保障
- 协程之间不会互相干扰。
- 一个协程等待资源时,会主动让出控制权给其他协程。
✅ 无需锁机制,避免死锁问题。
6.4 更快的执行速度
- 协程通过主动让出 CPU,实现非阻塞执行。
- 无需上下文切换开销。
- 不依赖系统调用。
✅ 降低整体执行时间。
6.5 更少内存泄漏
- 协程使用结构化并发(Structured Concurrency)。
- 子任务在父任务生命周期内完成。
- 协程库可传播取消操作,确保任务正确终止。
✅ 更容易控制生命周期,减少内存泄漏风险。
6.6 替代回调机制
- 回调函数虽然也能实现并发,但存在以下问题:
- 逻辑分散,难以调试。
- 异常处理困难。
- 不易维护。
✅ 协程通过异步、协作的方式执行代码,逻辑清晰,结构更优。
7. 总结
本文介绍了协程的基本概念、工作机制及其优势。
协程是一种协作式并发模型,具有低开销、高并发、非阻塞等特性。相比进程和线程,协程更轻量,适合资源受限但对性能要求高的系统。
✅ 协程适用于异步 I/O、事件驱动、Web 服务等场景,是现代高并发编程的重要工具。