1. 引言
在图像生成领域,Variational Autoencoder (VAE) 和 Generative Adversarial Network (GAN) 是两种主流的深度学习模型。本文将从原理、训练方式、优缺点及实际应用场景出发,对比分析这两种模型的异同,帮助你根据具体需求选择合适的生成模型。
2. 什么是变分自编码器(VAE)
VAE(Variational Autoencoder) 是一种基于概率建模的生成模型,由 Diederik P. Kingma 和 Max Welling 于 2013 年提出。它通过学习输入数据的潜在表示(latent representation),实现数据重建和生成。
VAE 的核心结构由两部分组成:
- Encoder(编码器)
- Decoder(解码器)
其整体架构如下图所示:
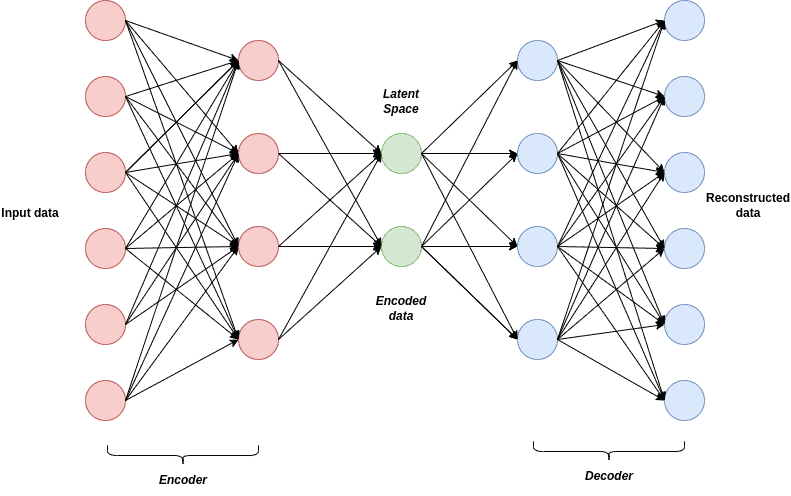
2.1 编码器(Encoder)
编码器的作用是将输入数据(如图像)映射到一个潜在空间(latent space),这个空间通常假设为高斯分布的组合。通过学习输入数据的概率分布,编码器能够提取出数据的关键特征。
2.2 解码器(Decoder)
解码器负责从潜在空间中重建输入数据。它试图最大化生成图像与原始输入之间的相似度,从而实现高质量的图像生成。
3. 什么是生成对抗网络(GAN)
GAN(Generative Adversarial Network) 是由 Ian J. Goodfellow 等人于 2014 年提出的一种生成模型,其核心思想是两个网络之间进行博弈:
- Generator(生成器):负责生成逼真的图像
- Discriminator(判别器):负责判断图像是真实数据还是生成器生成的假数据
它们的训练过程就像是一个零和博弈,最终目标是生成器能够生成出与真实数据几乎无法区分的样本。
GAN 的架构如下图所示:
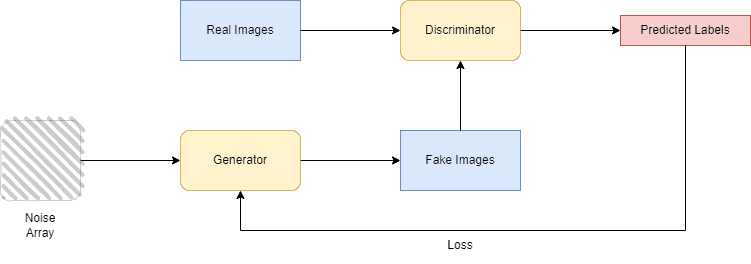
4. VAE 与 GAN 的主要区别
| 特性 | VAE | GAN |
|---|---|---|
| 训练方式 | 无监督学习 | 有监督博弈训练 |
| 损失函数 | KL 散度 + 重建损失 | 生成器和判别器分别有损失函数 |
| 训练难度 | 相对稳定,容易训练 | 难以收敛,训练不稳定 |
| 生成质量 | 通常较模糊,但稳定 | 高质量、高分辨率图像 |
| 潜在空间 | 可解释性强,连续性好 | 潜在空间可能不连续 |
| 适用场景 | 图像去噪、异常检测 | 图像生成、图像修复、风格迁移 |
✅ VAE 的优势
- 潜在空间结构良好,适合做插值、语义操作
- 损失函数设计明确,训练过程更稳定
❌ VAE 的劣势
- 生成图像往往不够清晰,细节表现力不足
✅ GAN 的优势
- 能生成非常逼真、高质量的图像
- 适合视觉要求高的任务,如图像合成、风格迁移
❌ GAN 的劣势
- 训练过程不稳定,容易出现模式崩溃(mode collapse)
- 潜在空间结构不明确,插值效果差
5. 实际应用场景对比
VAE 的常见用途
- ✅ 图像去噪
- ✅ 数据压缩
- ✅ 异常检测(如金融欺诈、医学图像识别)
- ✅ NLP 中的文本表示学习
GAN 的常见用途
- ✅ 图像生成(如人脸、风景等)
- ✅ 图像修复与超分辨率
- ✅ 图像风格迁移(如 DeepArt)
- ✅ 数据增强
- ✅ 音频与文本生成(如语音合成)
6. 总结
VAE 和 GAN 各有千秋,适用于不同类型的图像生成任务:
- VAE 更适合需要潜在空间可解释性、训练稳定性高的任务,如异常检测、图像重建。
- GAN 更适合追求图像质量、逼真度的场景,但需要面对训练难度大、易崩溃等问题。
在实际项目中,可以根据以下因素进行选择:
- ✅ 是否需要高质量图像输出?
- ✅ 是否需要可解释的潜在空间?
- ✅ 是否具备调参经验与训练资源?
选择合适的模型,才能真正发挥生成模型的价值。