1. 概述
在本教程中,我们将深入探讨相关系数在相关性分析中的实际含义。
我们会先了解变量之间相关性的基本概念,帮助我们理解为什么需要发展相关性分析。接着,我们将学习两种最常用的相关性分析方法:皮尔逊(Pearson)相关系数 和 斯皮尔曼(Spearman)等级相关系数,并了解它们的数学定义及其实际应用场景。
最后,我们将总结如何根据相关系数的取值来推断双变量分布的特性。
学完本教程后,你将能够直观理解相关系数的意义,并根据具体任务选择使用 Pearson 还是 Spearman 相关性分析。
2. 相关性的基本概念
2.1. 什么是相关性?
相关性分析是一种统计方法,用于研究两个随机变量之间的关系。有时也被称为依赖性,因为一个变量的取值可能“依赖”于另一个变量。
举个例子:我们知道一个人的身高和体重通常呈正相关关系,也就是说,身高越高,体重往往也越重:
这启发我们去验证这种依赖关系是否存在。为了验证这一点,我们需要一个衡量两个变量之间相关程度的指标,这就是我们所说的相关系数。
我们可以想象,变量之间的相关性可能是强、弱,甚至是完全没有的:
理想的相关系数应该能让我们一眼看出这些情况之间的区别。
2.2. 相关 ≠ 因果
相关性是探索性数据分析中的重要工具,因为它可以帮助我们初步识别那些可能不是线性独立的特征。
但它并不意味着因果关系。统计学家常说:“相关不代表因果(Correlation does not imply causation)”。意思是:两个变量相关,并不意味着其中一个变量是另一个变量的因果原因。
这个命题在逻辑上可以形式化为:
如果 r 表示相关性,c 表示因果性,那么
$$
\neg (r \to c)
$$
根据逻辑等价变换,我们可以将其转化为: $$ r \wedge \neg c $$
也就是说,存在相关性但没有因果性是完全可能的。
2.3. 什么情况下相关不代表因果?
我们常常会因为一些逻辑错误(fallacy)误以为两个变量之间存在因果关系。常见的两种情况如下:
✅ 因果方向错误
两个变量 p 和 q 之间可能存在因果关系 p → q,但如果我们错误地认为是 q → p,就会得出错误结论。
比如你发现只要往碗里放食物,猫就会出现、叫唤并吃掉食物:

你可能会误以为“放食物”导致“猫出现”。但其实,猫的存在才是你放食物的原因:

✅ 存在第三个变量(中介变量)
两个变量 p 和 q 都可能是由一个隐藏变量 s 导致的,即:
$$
(s \to p) \wedge (s \to q)
$$
例如,我们观察到火车进站和乘客到达之间存在高度相关性:
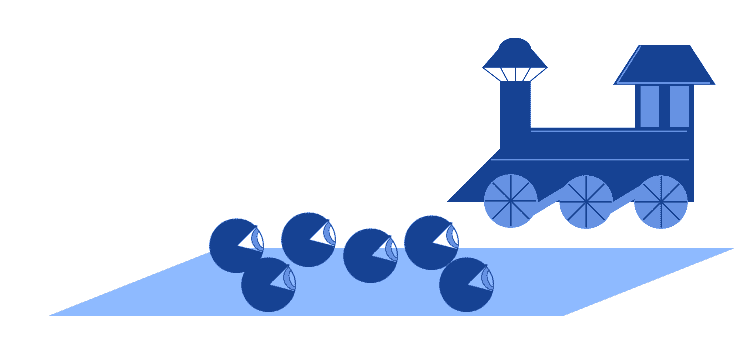
但这其实是因为两者都受到列车时刻表这个第三方因素的影响。
2.4. 因果 ≠ 相关
虽然我们常说“相关不代表因果”,但你可能也会问:因果关系是否一定意味着相关?
答案是否定的。相关性,尤其是皮尔逊相关系数,只衡量变量之间的线性关系。而因果关系可能表现为非线性或非单调关系,这时相关系数可能为 0。
例如下面这个非线性和非单调的关系:
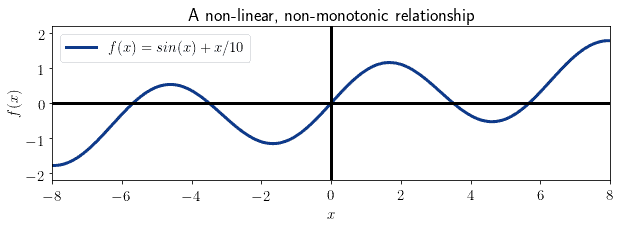
尽管存在明确的因果关系,但 Pearson 和 Spearman 相关系数都可能接近 0。
📌 总结:只有在线性或单调关系中,我们才能从因果性推导出相关性。
3. 皮尔逊相关系数(Pearson Correlation Coefficient)
3.1. 简介
皮尔逊相关系数是最早用于衡量两个变量之间相关性的方法之一,诞生于 19 世纪末。
它基于这样一个思想:如果两个变量之间存在线性关系,那么它们的联合分布可以用线性回归模型来拟合。
皮尔逊相关系数对变量的缩放和平移是不变的,因此特别适合用于研究分层系统或分形系统的相关性。
3.2. 数学定义
两个随机变量 x 和 y 的皮尔逊相关系数 r_xy 定义如下:
$$ r_{xy} = \frac{ \sum_{i=1}^{k} (x_i - \overline{x}) (y_i - \overline{y}) } { \sqrt { \sum_{i=1}^{k} (x_i - \overline{x})^2 } \sqrt { \sum_{i=1}^{k} (y_i - \overline{y})^2 } } $$
其中:
x̄和ȳ分别是x和y的均值- 相关系数的取值范围为
[-1, 1]r_xy = 1:完全正相关r_xy = 0:无相关性r_xy = -1:完全负相关
3.3. 不同取值的分布形态
| 相关系数 | 分布形态 | 含义 |
|---|---|---|
r_xy ≈ 0 |
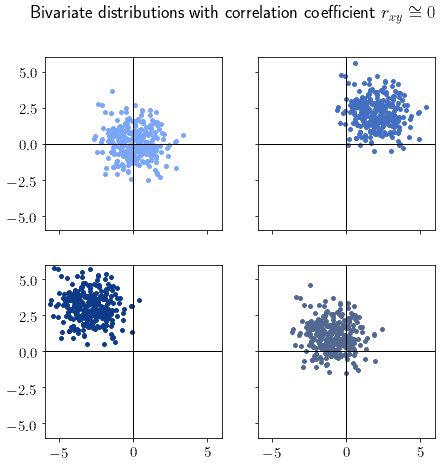 |
无相关性,分布呈“云状” |
r_xy = 1 |
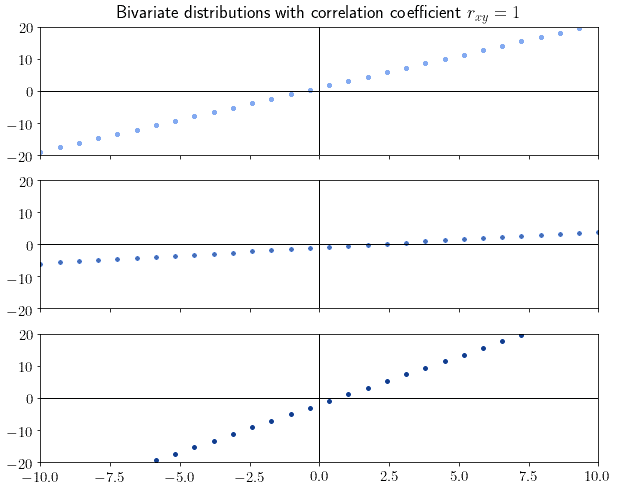 |
完全正相关,分布呈正斜率直线 |
r_xy = -1 |
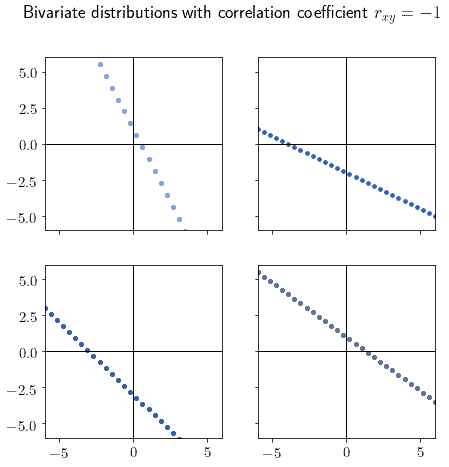 |
完全负相关,分布呈负斜率直线 |
大多数实际数据的相关系数不会正好是 0 或 ±1,但会随着分布形状接近这些值而趋近于它们。
例如:
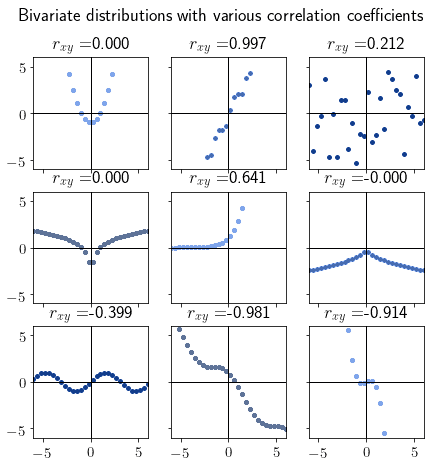
3.4. 如何解读皮尔逊相关系数
一个常见的误区是将皮尔逊相关系数理解为线性回归模型的斜率。
❌ 错误理解:
- 相关系数 = 回归线斜率
✅ 正确认识: - 相关系数衡量的是线性关系的强度和方向,而不是斜率大小
例如,只要分布完美地落在一条直线上,无论斜率是多少,相关系数都将是 ±1。
📌 皮尔逊相关系数可以很好地预测线性回归模型的拟合效果。
r_xy = ±1:线性模型拟合完美,误差为 0r_xy = 0:线性模型无法拟合该分布
4. 斯皮尔曼等级相关系数(Spearman’s Rank Correlation)
4.1. 简介
斯皮尔曼相关系数 ρ_xy 是一种更精细的相关性衡量方法,适用于非线性但单调的关系。
它和皮尔逊一样,取值范围为 [-1, 1],但它解决了一个关键问题:当变量之间是单调但非线性关系时,皮尔逊相关系数可能不等于 ±1。
例如:
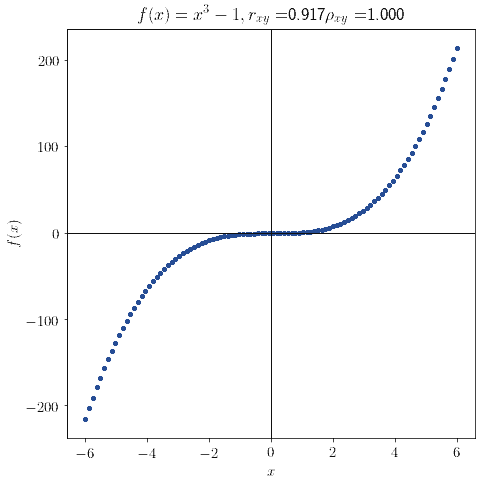
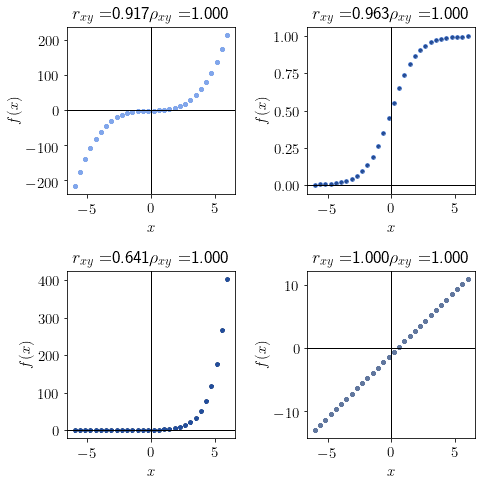
这种情况下,皮尔逊相关系数可能远小于 1,而斯皮尔曼则能正确识别出单调性。
4.2. 数学定义
斯皮尔曼相关系数是基于变量的秩次(rank)计算的,而不是原始值本身。
举个例子,如果 x = [5.3, 2.8, 4.2, 3, 1.4],排序后为 [1.4, 2.8, 3, 4.2, 5.3],对应的秩次为 [5, 2, 4, 3, 1]。
斯皮尔曼相关系数公式如下:
$$ \rho_{xy} = \frac {\text{cov}(rg_x, rg_y)} {\sigma(rg_x) \sigma(rg_y)} $$
其中:
rg_x和rg_y是x和y的秩次cov是协方差σ是标准差
4.3. 不同取值的分布形态
| 相关系数 | 分布形态 | 含义 |
|---|---|---|
ρ_xy = 1 |
 |
单调递增 |
ρ_xy = -1 |
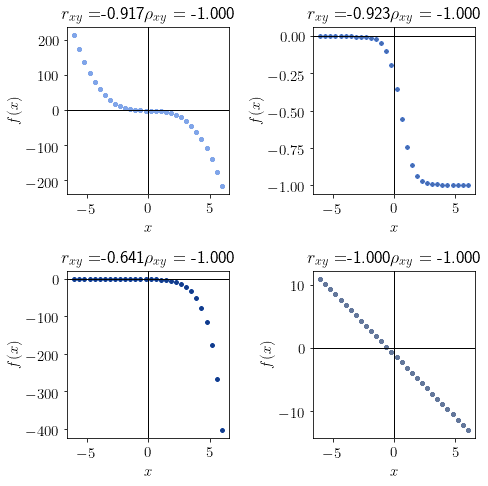 |
单调递减 |
ρ_xy ≈ 0 |
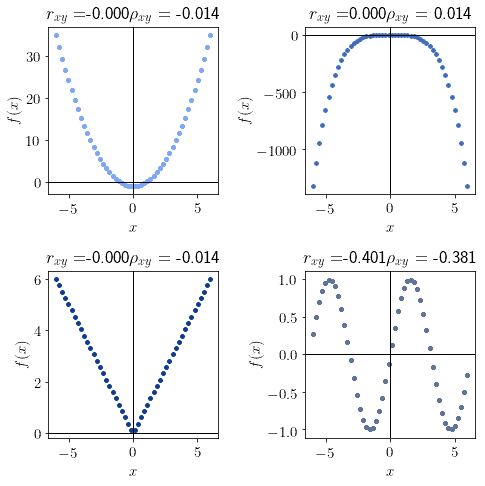 |
非单调 |
📌 斯皮尔曼相关系数特别适合用于检测非线性但单调的关系。
4.4. 如何解读斯皮尔曼相关系数
斯皮尔曼相关系数反映的是两个变量是否趋向于同方向变化:
ρ_xy = 1:两个变量总是同增同减ρ_xy = -1:两个变量总是此增彼减ρ_xy = 0:两个变量变化方向没有明显规律
📌 它并不依赖于函数的连续性,适用于所有随机变量。
5. 两种相关系数的对比与解读
5.1. 不同相关系数的含义总结
皮尔逊 r_xy |
斯皮尔曼 ρ_xy |
含义 |
|---|---|---|
≈ 0 |
≈ 0 |
无相关性 |
≈ ±1 |
≈ ±1 |
线性关系 |
≈ ±1 |
= ±1 |
单调但非线性关系 |
≈ 0 |
= ±1 |
非线性但单调关系 |
= ±1 |
≈ 0 |
线性但非单调关系(罕见) |
5.2. 根据分布形状猜测相关系数
我们可以通过观察分布形状来推测相关系数的大概值:
示例 1:线性递减分布
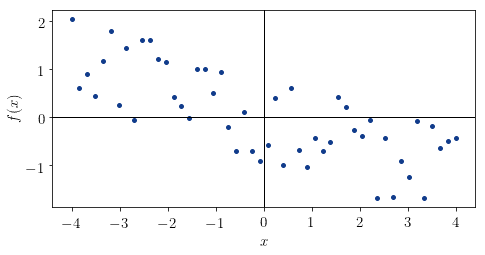
- 形状:线性递减
- 推测:
r_xy, ρ_xy ∈ (-1, 0) - 实际值:
r_xy = -0.734,ρ_xy = -0.721
✅ 推测正确
示例 2:类 Sigmoid 函数分布
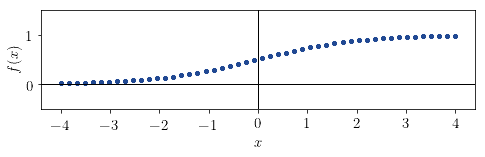
- 形状:单调递增,近似线性
- 推测:
ρ_xy = +1,r_xy ∈ (0, +1) - 实际值:
r_xy = 0.982,ρ_xy = 1
✅ 推测正确
示例 3:正弦函数分布
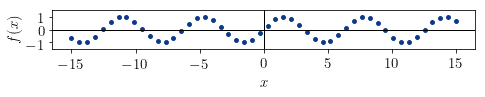
- 形状:非单调,无明显递增/递减趋势
- 推测:
r_xy ≈ 0,ρ_xy ≈ 0 - 实际值:
r_xy = 0.152,ρ_xy = 0.144
✅ 推测正确
6. 总结
在本文中,我们深入探讨了:
- 相关性与因果性的区别与联系
- 皮尔逊相关系数的数学定义与应用场景
- 斯皮尔曼相关系数的定义及其优势
- 如何根据分布形态判断相关系数的取值
📌 关键点总结:
- 相关性 ≠ 因果性
- 皮尔逊相关系数衡量线性关系强度
- 斯皮尔曼相关系数衡量单调关系强度
- 只有在线性或单调关系中,相关性才能作为因果性的间接证据
掌握这些概念,可以帮助你在数据分析、机器学习建模等实际场景中更好地理解和使用相关系数。