1. 概述
在本教程中,我们将讨论强化学习中的一个经典问题:信用分配问题(Credit Assignment Problem, CAP)。我们会通过一个实际例子来说明这个问题,并介绍几种常见的解决方案。
2. 强化学习基础
强化学习(Reinforcement Learning, RL)是机器学习的一个分支,关注智能体(Agent)如何在环境中通过与环境交互来学习做出独立决策,以最大化其获得的奖励。
它的灵感来源于动物通过试错学习的方式。强化学习的目标是构建能够通过最大化累积奖励来达成目标的智能体。
在强化学习中,智能体对环境执行某些动作(Actions),环境根据这些动作给予奖励(Reward),然后智能体进入新的状态(State),并重复这一过程。奖励可以是正的(鼓励)也可以是负的(惩罚):
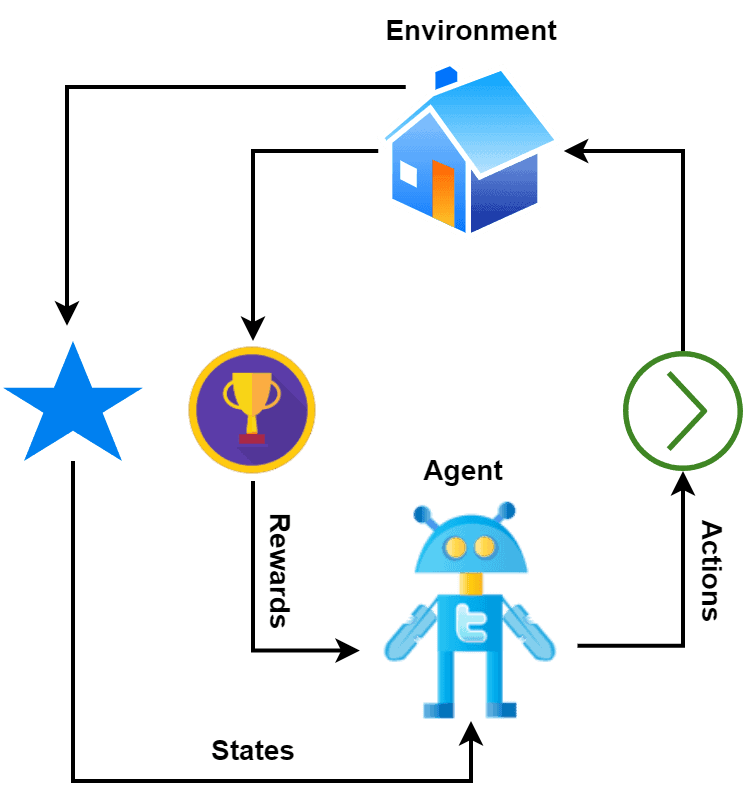
智能体的目标是构建一个最优策略(Optimal Policy),使长期累积的奖励最大化。这通常是通过迭代过程完成的:智能体通过与环境交互积累经验,并据此不断更新策略以提升决策能力。
3. 信用分配问题
信用分配问题是指在强化学习中,当智能体获得某个奖励时,它需要判断哪些先前的动作促成了这个奖励的产生。
强化学习的核心机制是:智能体执行一系列动作以最大化总体奖励,并根据环境反馈更新策略。这种反馈通常是一个标量奖励值,表示动作的质量。
信用分配问题的核心在于:评估某个动作对未来奖励的影响。 这对智能体优化策略、做出更优决策至关重要。
然而,现实中常常面临以下挑战:
- 环境给出的奖励信号并未明确指出哪些动作应被鼓励或避免;
- 智能体可能执行了一系列动作后才收到最终奖励,此时需要判断哪些动作对结果有积极贡献;
- 奖励可能是多个动作长期作用的结果,单个动作的贡献难以明确区分。
4. 示例说明
我们来看一个实际例子来更直观地理解信用分配问题。
假设智能体在一个迷宫中移动,目标是从左上角出发,到达右下角的目标点。智能体可以向上、下、左、右或对角方向移动,但不能穿过有障碍物(如石头)的格子:
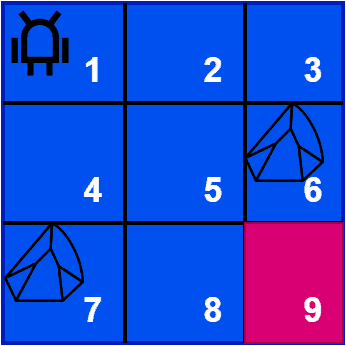
在探索过程中,智能体:
- 到达目标时获得 +10 奖励;
- 撞上石头时被惩罚 -10 奖励。
智能体的目标是通过学习奖励信号,构建一个能最大化总体奖励的最优策略。
问题是:当智能体最终到达目标时,它获得了一个 +10 的奖励,但它并不清楚是哪一步或哪些动作导致了这个结果。
比如,它可能走了很多弯路才到达终点。这时,它需要判断哪些动作应该“记功”,哪些动作应该“记过”。
下图展示了三条可能的路径:
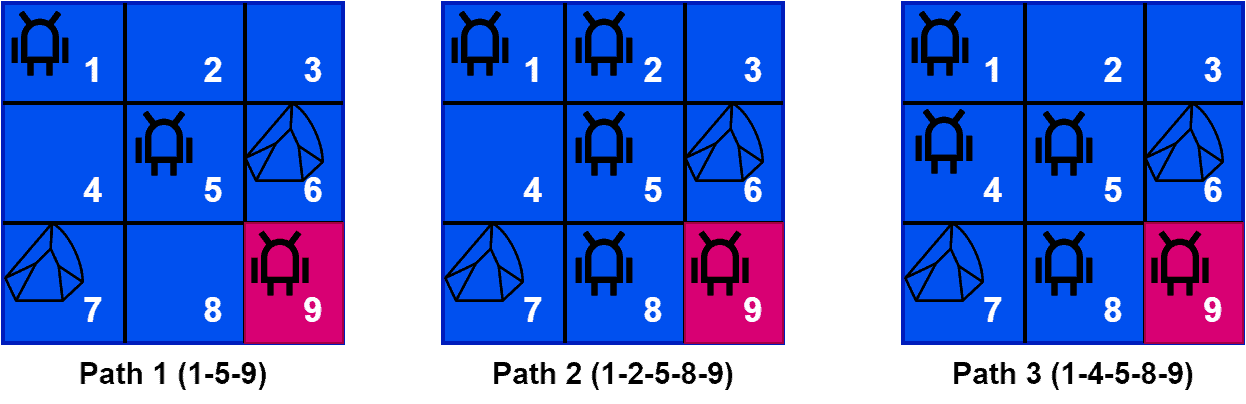
三条路径中,路径1是最优路径。我们可以看出,从状态1到状态5的对角线移动,对最终达成目标的贡献最大。
信用分配问题的关键就在于:量化每个动作对最终奖励的贡献程度,从而指导策略优化。
5. 解决方案
信用分配问题在强化学习中至关重要。以下是三种常见解决方法:
✅ 5.1 时间差分学习(Temporal Difference Learning, TD)
TD学习是一种广泛使用的强化学习算法,采用引导(Bootstrapping)方式为过去动作分配信用。
- 它通过比较当前时间步的预测奖励与实际收到的奖励之间的差异来更新策略的价值函数;
- 利用未来状态的预测奖励来引导当前状态的价值更新;
- 即使奖励延迟,也能为之前的动作分配信用。
✅ 5.2 蒙特卡洛方法(Monte Carlo Methods)
蒙特卡洛方法通过完整的回合(Episode)经验来分配信用:
- 它通过平均多个回合中某状态出现后的总奖励来估计该状态的价值;
- 不依赖未来状态的估计,而是直接使用完整回合的结果;
- 可以准确评估导致最终奖励的一系列动作,但需要等到回合结束才能更新策略。
✅ 5.3 资格迹方法(Eligibility Traces)
资格迹方法通过追踪最近的动作历史来分配信用:
- 记录最近的状态-动作对,并使用一个衰减因子来衡量它们对最终奖励的贡献;
- 较近的动作获得更高的权重,较远的动作权重逐渐衰减;
- 能够在不等待完整回合结束的情况下,合理分配信用。
6. 小结
信用分配问题是强化学习中一个核心挑战。它要求智能体能够判断哪些动作对最终获得的奖励做出了贡献。
我们通过一个迷宫导航的例子说明了这一问题的复杂性,并介绍了三种主流解决方案:
- 时间差分学习(TD)
- 蒙特卡洛方法(Monte Carlo)
- 资格迹方法(Eligibility Traces)
这些方法各有优劣,适用于不同的场景。在实际开发中,选择合适的信用分配策略对构建高效、智能的强化学习系统至关重要。