1. 引言
马尔可夫链蒙特卡洛方法(Markov Chain Monte Carlo,简称 MCMC)是一种通过随机抽样来近似复杂概率分布的技术。其核心思想是构建一个马尔可夫链(Markov Chain),使得该链的平稳分布(stationary distribution)与我们想要估计的目标分布一致。然后通过模拟该链的状态转移,生成一系列样本,从而逼近目标分布。
MCMC 方法广泛应用于贝叶斯推断、统计建模、机器学习等领域,尤其适用于高维空间中难以直接抽样的情况。其中,Metropolis-Hastings 算法是最具代表性的 MCMC 实现之一。
2. 马尔可夫链基础
马尔可夫链是一种描述状态转移概率的数学模型。它的核心特性是“无记忆性”:下一状态的概率分布仅依赖于当前状态,而与历史状态无关。
2.1 示例:餐厅菜单的马尔可夫链
假设一家餐厅每天只提供鱼(Fish)或意大利面(Pasta)两种菜品,其菜单选择遵循以下转移概率:
| 当前菜品 | 昨天是 Fish | 昨天是 Pasta |
|---|---|---|
| Fish | 0.2 | 0.7 |
| Pasta | 0.8 | 0.3 |
用矩阵形式表示为:
$$ T = \begin{bmatrix} 0.2 & 0.8 \ 0.7 & 0.3 \end{bmatrix} $$
矩阵中行表示当前菜品,列表示昨天的菜品。例如,T[0][0] 表示昨天是 Fish 时,今天还是 Fish 的概率为 0.2。
2.2 平稳状态(Equilibrium State)
如果我们不断乘以这个转移矩阵 T,最终会收敛到一个稳定的概率分布,称为平稳状态。例如,经过足够多的天数后,Fish 和 Pasta 出现的概率将趋于稳定:
$$ E = \begin{bmatrix} 0.466 & 0.533 \ 0.466 & 0.533 \end{bmatrix} $$
无论初始状态是 Fish 还是 Pasta,最终都会收敛到相同的平稳分布。这正是 MCMC 方法的基础:通过构造一个合适的马尔可夫链,使其平稳分布为我们想要的分布。
3. 马尔可夫链蒙特卡洛(MCMC)
MCMC 的核心思想是:构造一个马尔可夫链,使其平稳分布等于我们想要估计的目标分布。然后通过模拟链的状态转移,生成一系列样本,从而逼近目标分布。
3.1 Metropolis-Hastings 算法
Metropolis-Hastings 是最经典的 MCMC 实现之一。它通过一个建议分布(proposal distribution)生成候选样本,并根据接受概率决定是否接受该样本。
以下是 Metropolis-Hastings 算法的伪代码实现:
algorithm MetropolisHasting(N, f):
// 输入
// N = 迭代次数
// f = 目标分布的未归一化密度函数
// 输出
// samples = 样本数组
// acceptanceRate = 接受率
A <- 0
samples <- empty array
x <- uniformRandom() // 初始状态
for i <- 0 to N-1:
x' <- prior(x) // 从建议分布中采样
R <- min(1, f(x') / f(x) * g(x | x') / g(x' | x)) // 接受概率
if R >= uniformRandom():
x <- x'
A <- A + 1
samples.append(x)
acceptanceRate <- A / N
return samples, acceptanceRate
3.2 接受概率(Acceptance Probability)
Metropolis-Hastings 的关键在于接受概率 R 的计算:
$$ R = \min\left(1, \frac{f(x')}{f(x)} \cdot \frac{g(x | x')}{g(x' | x)}\right) $$
其中:
f(x)是目标分布的未归一化密度;g(x' | x)是建议分布,表示从 x 转移到 x' 的概率;g(x | x')是反向建议概率。
该公式确保了马尔可夫链满足详细平衡条件(Detailed Balance),即:
$$ P(x'|x)P(x) = P(x|x')P(x') $$
这保证了链最终会收敛到目标分布。
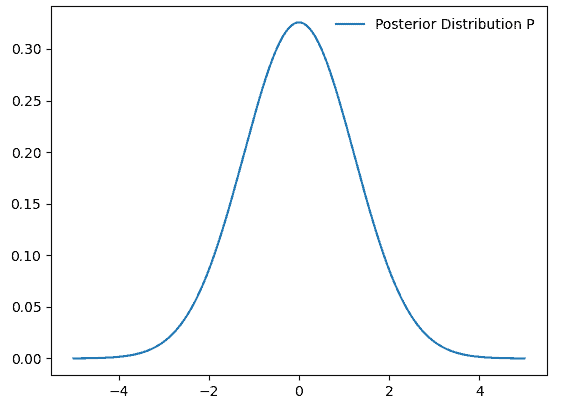
3.3 示例:正态分布采样
假设我们不知道一个正态分布的具体形式,只知道它与某个函数 f 成正比。我们可以使用 Metropolis-Hastings 算法从 f 中采样,并构造一个马尔可夫链来逼近该分布。
下图展示了在 5000 次迭代后,样本开始向目标分布收敛:
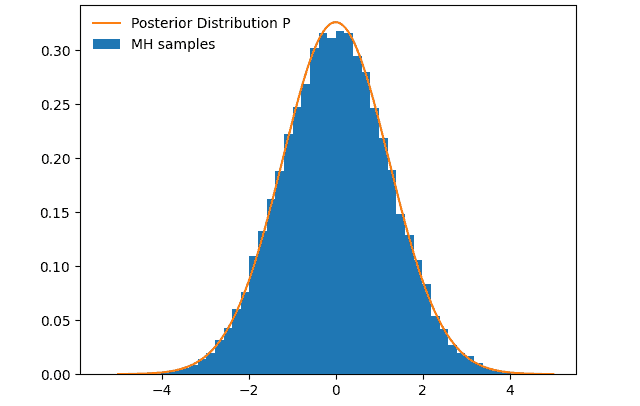
随着迭代次数增加到 100,000,样本分布与目标分布几乎完全一致:
4. 与其他采样方法的对比
MCMC 方法特别适合高维问题,但在低维场景下也有一些局限性:
✅ 优点:
- 适用于高维、复杂分布;
- 不需要归一化目标分布;
- 可以用于贝叶斯推断、参数估计等场景。
❌ 缺点:
- 样本之间存在相关性,影响估计精度;
- 收敛速度可能较慢;
- 对初始值敏感,需“burn-in”阶段去除初始偏差。
⚠️ 踩坑提醒:使用 MCMC 时要注意链的收敛性评估(如通过 trace plot、autocorrelation 图等),否则容易得出错误结论。
其他采样方法对比:
| 方法 | 优点 | 缺点 |
|---|---|---|
| 自适应拒绝采样(ARS) | 适用于单峰分布,效率高 | 仅适用于一维问题 |
| 哈密尔顿蒙特卡洛(HMC) | 步长更大,样本相关性低 | 实现复杂,需梯度信息 |
| Gibbs 采样 | 适用于共轭分布 | 需要条件分布可采样 |
5. 总结
本文介绍了马尔可夫链蒙特卡洛方法的基本原理,重点讲解了 Metropolis-Hastings 算法的实现和数学基础。我们通过一个餐厅菜单的例子说明了马尔可夫链如何收敛到平稳分布,并通过正态分布采样展示了 MCMC 的实际应用。
MCMC 是一种强大的工具,尤其在贝叶斯统计和机器学习中具有广泛应用。尽管它在低维场景下存在样本相关性等缺点,但在高维复杂分布建模中仍具有不可替代的优势。
建议:实际使用中应结合诊断工具评估收敛性,并根据问题特点选择合适的 MCMC 变体(如 HMC、Gibbs 等)以提高效率。