1. 概述
随着机器学习在我们生活中的广泛应用,了解其背后的基础算法和核心技术变得尤为重要。本文将对比两种经典的分类器:朴素贝叶斯(Naive Bayes) 和 决策树(Decision Tree)。
我们将简要回顾它们的理论基础和实现机制,分析它们在分类任务中的优劣势,并讨论其在实际应用中的适用性。
2. 基础知识
朴素贝叶斯和决策树是机器学习中最受欢迎的两种方法。它们的成功源于其坚实的理论基础、高效的计算能力、良好的可扩展性以及一定的可解释性。
不过,它们也并非完美无缺。本文将分别深入探讨每种方法的原理,并进行对比分析。
为了便于比较,我们先设定一个通用的分类场景:我们拥有一个包含 N 个样本的数据集,每个样本由 M 个特征(attributes)描述,且每个样本都属于某个类别(class)。这些数据将用于训练分类器的参数。
最终目标是让模型能泛化到训练数据之外的新样本,因此我们通常使用一个独立的测试集来评估模型的准确率。
3. 朴素贝叶斯
关于朴素贝叶斯的完整介绍可参考这篇文章,本节仅作简要回顾。
3.1. 原理
朴素贝叶斯是一种基于贝叶斯定理的概率分类模型。贝叶斯定理用于计算在已知某些先验信息 B 的前提下,事件 A 发生的概率:
$$ P(A|B) = \frac{P(A,B)}{P(B)} = \frac{P(A) P(B|A)}{P(B)} $$
将此公式应用于分类任务中,我们的目标是计算:
$$ P(C_k | \hat{x}) = \frac{P(C_k) \prod_{i=1}^M P(x_i | C_k)}{P(\hat{x})} $$
其中 $\hat{x} = (x_1, x_2, ..., x_M)$ 是输入特征,$C_k$ 是第 k 个类别。
朴素贝叶斯的核心假设是:所有特征之间相互独立。这个假设虽然在现实中往往不成立,但大大简化了计算。
示例图
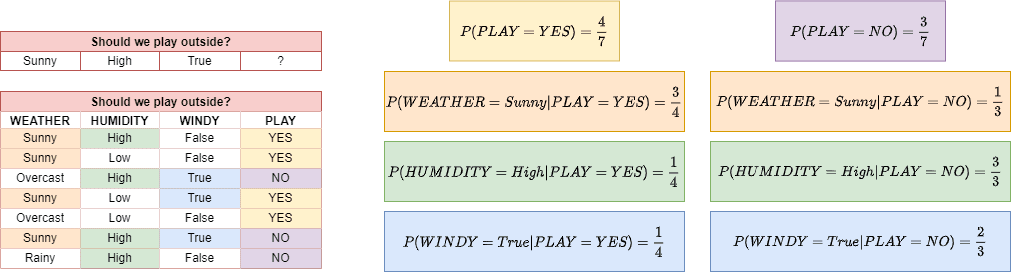
上图展示了一个简单的天气数据集。我们希望根据天气、湿度、风速等特征预测是否适合外出打球。通过统计每个特征在不同类别下的频率,可以计算出后验概率。
3.2. 说明
由于特征之间被假设为相互独立,因此可以将多维联合概率拆解为一维概率的乘积,从而大大减少计算量。
虽然独立性假设通常不成立,但只要最终预测的类别后验概率最大,结果就不会受影响。这正是朴素贝叶斯在实际中表现良好的原因。
3.3. 优势与局限
✅ 优势:
- 实现简单,计算高效
- 对小数据集表现良好
- 不容易过拟合
- 适用于高维稀疏数据(如文本分类)
❌ 局限:
- 特征间若存在强相关性,会影响分类效果
- 对噪声数据敏感(如“毒化”现象)
- 需要手动挑选特征才能达到最佳效果
⚠️ 适用场景:文本分类、垃圾邮件识别、新闻分类等。
4. 决策树
4.1. 原理
决策树是一种基于特征划分的树形结构分类器。它通过一系列特征判断(if-else)将数据逐步划分到不同的叶子节点,最终输出分类结果。
树的构建过程依赖于信息增益(Information Gain)等指标来决定哪个特征先划分。信息增益越大,说明该特征对分类的贡献越大。
信息熵(Entropy)的计算公式如下:
$$ I(p_1, ..., p_k) = -\sum_{i=1}^k p_i \log_2 p_i $$
信息熵越高,数据越混乱;划分后熵越低,说明划分效果越好。
示例图
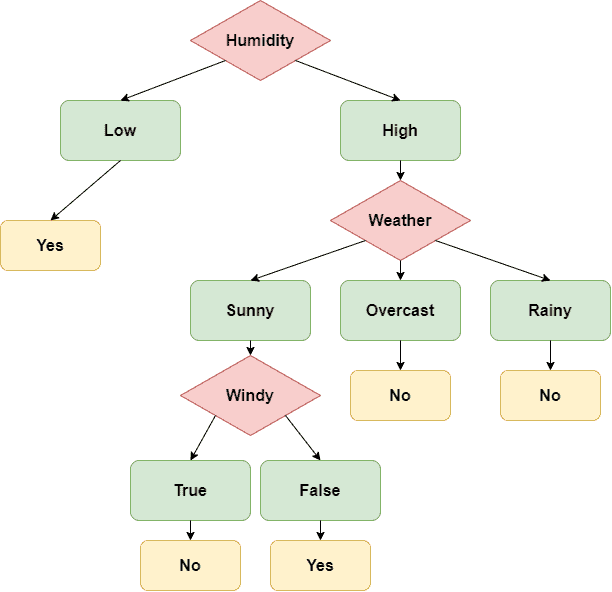
如图所示,我们根据天气、湿度、是否有风等特征构建了一个决策树。对于输入 (Sunny, High, True),最终输出为 NO。
4.2. 优势与局限
✅ 优势:
- 可解释性强,易于可视化
- 支持数值型和类别型数据
- 几乎不需要数据预处理
- 可以发现特征之间的潜在关系
❌ 局限:
- 容易过拟合(可通过剪枝缓解)
- 对类别分布不均的数据敏感
- 分割方式为线性,不适用于非线性可分问题
⚠️ 适用场景:风险评估、业务决策、金融建模等。
5. 对比分析
| 特性 | 朴素贝叶斯 | 决策树 |
|---|---|---|
| 计算效率 | ✅ 高 | ✅ 高 |
| 可解释性 | ❌ 低 | ✅ 高 |
| 数据要求 | ✅ 小数据即可 | ✅ 小数据即可 |
| 对特征依赖 | ✅ 依赖独立性假设 | ✅ 依赖信息增益排序 |
| 抗噪能力 | ❌ 弱 | ✅ 中等 |
| 易于调优 | ✅ 低 | ✅ 中等 |
选择建议:
- 如果特征之间基本独立,或数据稀疏(如文本),优先选 朴素贝叶斯
- 如果需要可解释性、可视化,或特征之间有复杂关系,优先选 决策树
6. 总结
两种分类器各有千秋:
- 朴素贝叶斯 依赖于特征独立性假设,适用于文本分类等场景。
- 决策树 更注重特征重要性排序,适合结构化数据和需要解释性的任务。
在实际应用中,建议结合数据特点进行尝试,并辅以交叉验证、参数调优等手段来提升模型性能。
✅ 一句话总结:
朴素贝叶斯适合“简单快速”,决策树适合“清晰可解释”。两者都值得加入你的机器学习工具箱。