1. 简介
在实际开发中,我们有时会遇到这样一类数组:它们基本已经有序,只有少数元素处于错误的位置。这类数据该如何排序?选择哪种排序算法效率最高?
本文我们将分析四种常见的排序算法在基本有序数组上的表现,帮助你在实际开发中做出更合适的选择。
2. 问题定义
排序算法的性能分析通常关注最坏情况或平均情况下的时间复杂度。但在某些特定场景下,比如输入数组基本有序时,理论上的复杂度可能无法准确反映实际表现。
✅ 我们关注的是:当一个数组基本有序时,哪种排序算法性能最好?
⚠️ 注意:我们假设数组中没有重复元素。虽然这个假设略显理想化,但可以简化分析。对于有少量重复元素的数组,预期结果不会相差太大。
3. 实验方法
3.1 基本有序数组的定义
我们定义一个数组为“基本有序”,如果它只有少量逆序对(inversion)。用数学表达如下:
(1) 
其中:
α(a)表示数组的“有序度”ε ∈ (0, 1)是一个阈值,表示我们认为“基本有序”的最大逆序对比例
比如设置 ε = 0.01 或 0.05,表示我们只认为逆序对不超过 1% 或 5% 的数组是基本有序的。
3.2 四种基本有序数组类型
我们考虑了以下四种类型的基本有序数组:
| 类型 | 特点 | 逆序对分布 |
|---|---|---|
| 左扰动(Left-perturbed) | 逆序对集中在左侧 | 指数下降 |
| 右扰动(Right-perturbed) | 逆序对集中在右侧 | 指数上升 |
| 中扰动(Centrally perturbed) | 逆序对集中在中间 | 高斯分布 |
| 均匀扰动(Uniformly perturbed) | 逆序对均匀分布 | 均匀分布 |
3.3 测试的排序算法
我们测试了以下四种排序算法:
✅ Bubble Sort
✅ Insertion Sort
✅ Quicksort
✅ Merge Sort
选择它们的原因如下:
- Bubble 和 Insertion 是简单排序算法,理论上在基本有序数组上表现更好
- Merge Sort 有稳定的 O(n log n) 时间复杂度
- Quicksort 平均性能优秀,但在最坏情况下会退化到 O(n²)
3.4 性能指标
我们关注以下三个指标:
- ✅ 交换次数(Swaps)
- ✅ 比较次数(Comparisons)
- ✅ 执行时间(Seconds)
⚠️ 注意:实际运行时间受硬件、操作系统、并发进程等影响,因此只能作为参考。
4. 实验结果
4.1 交换次数(Swaps)
所有算法的交换次数都随着数组大小和逆序对数量增加而增加。
- Bubble 和 Insertion 在均匀扰动数组上交换最多,因为逆序对分散,交换距离更长
- Merge 和 Quicksort 的交换次数相对稳定
📊 结果图如下:
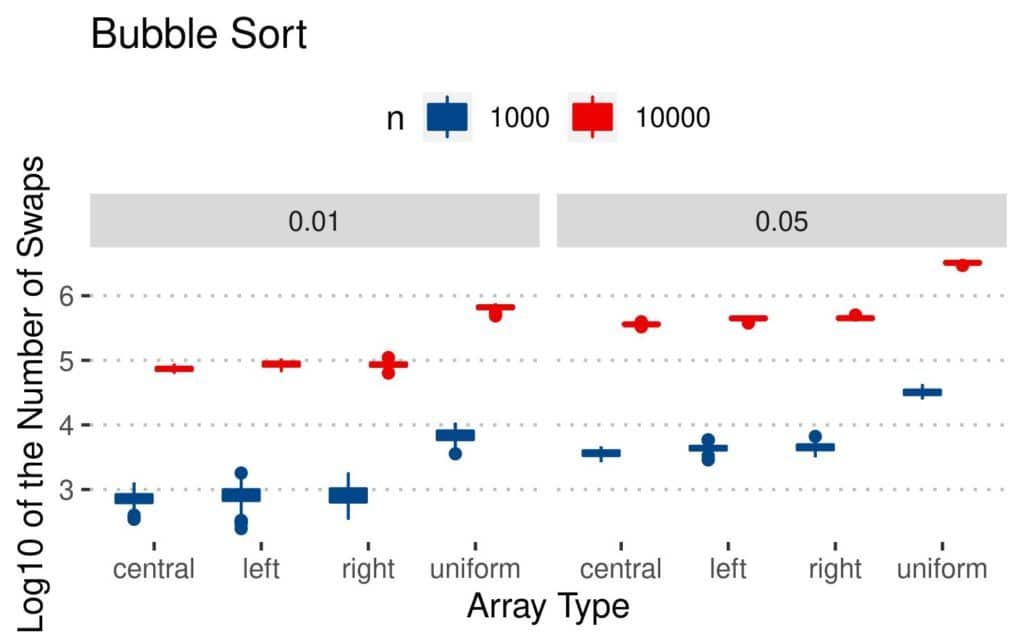
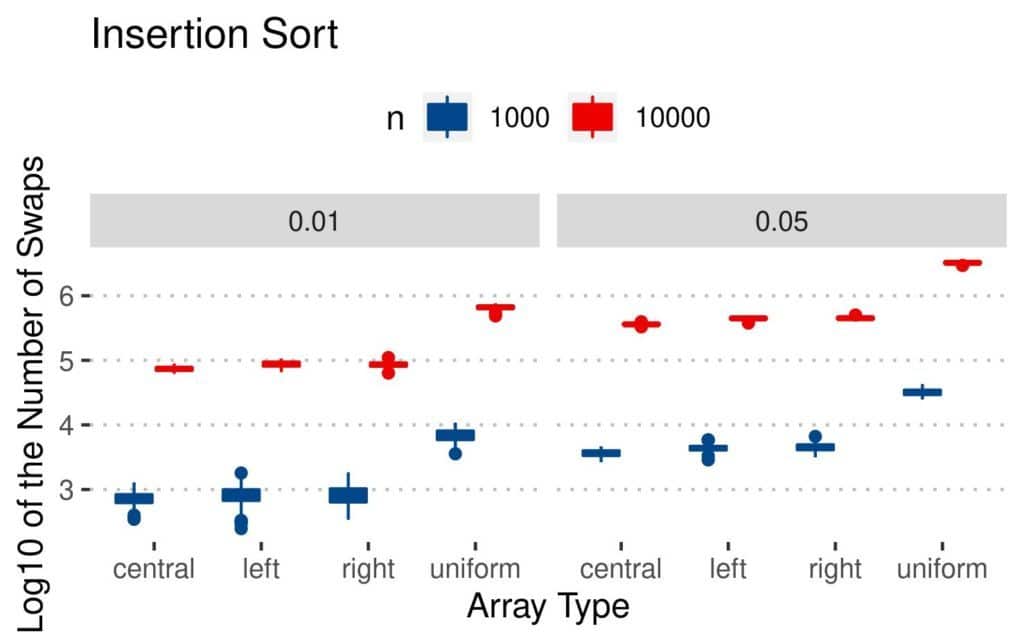
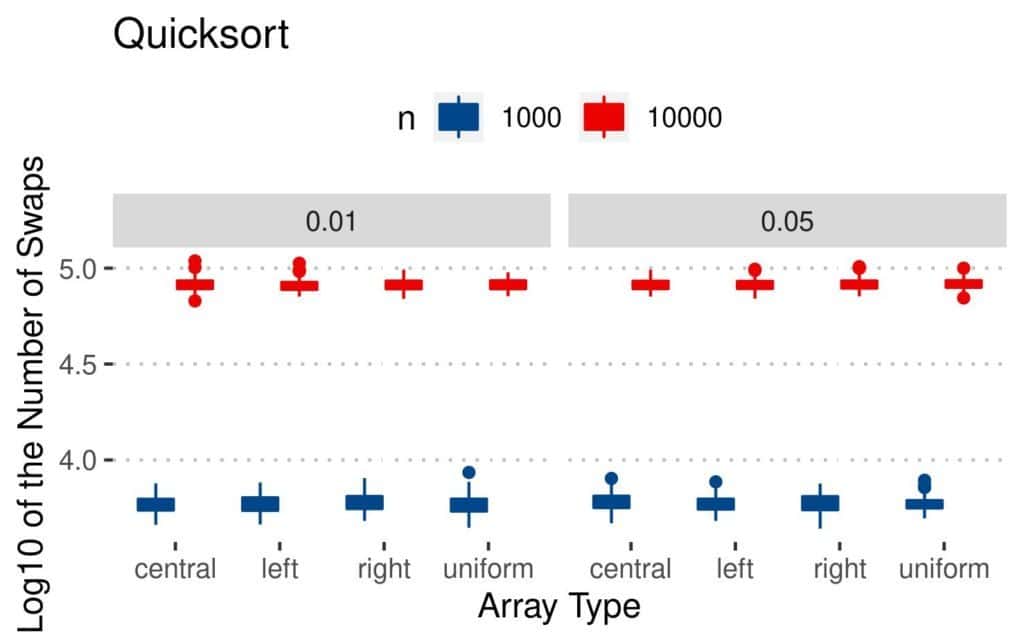
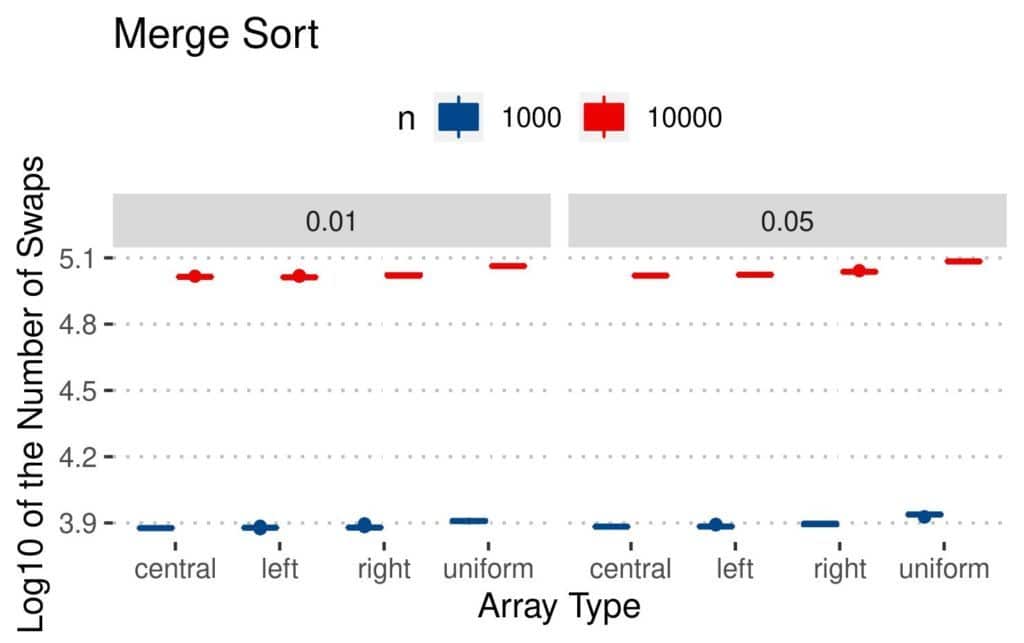
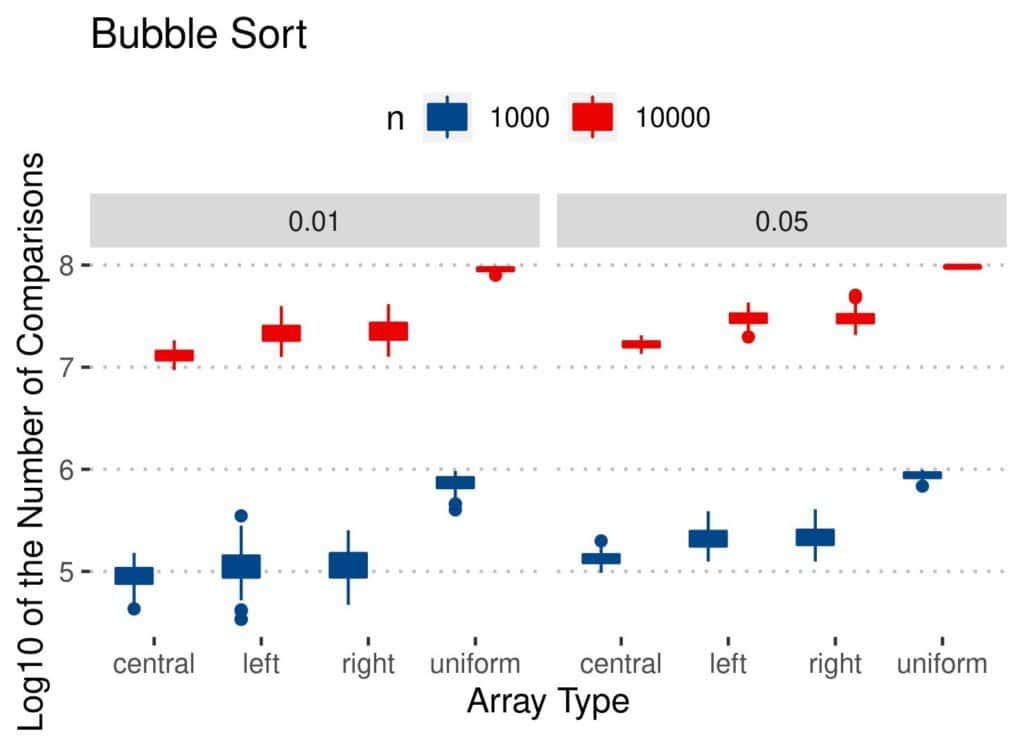
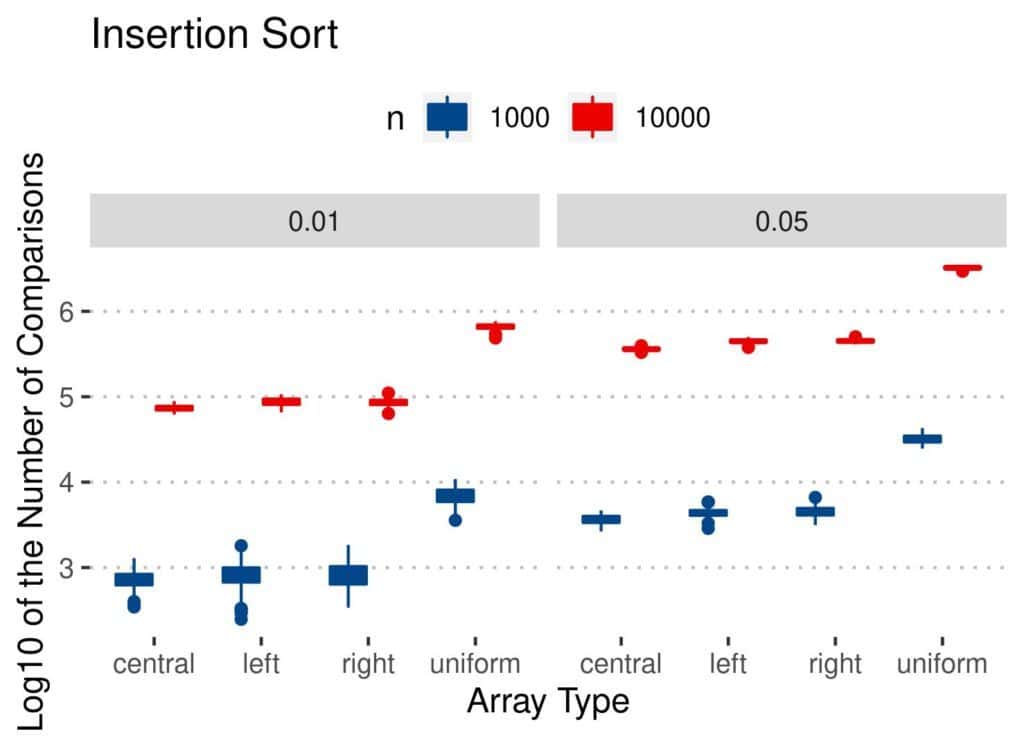
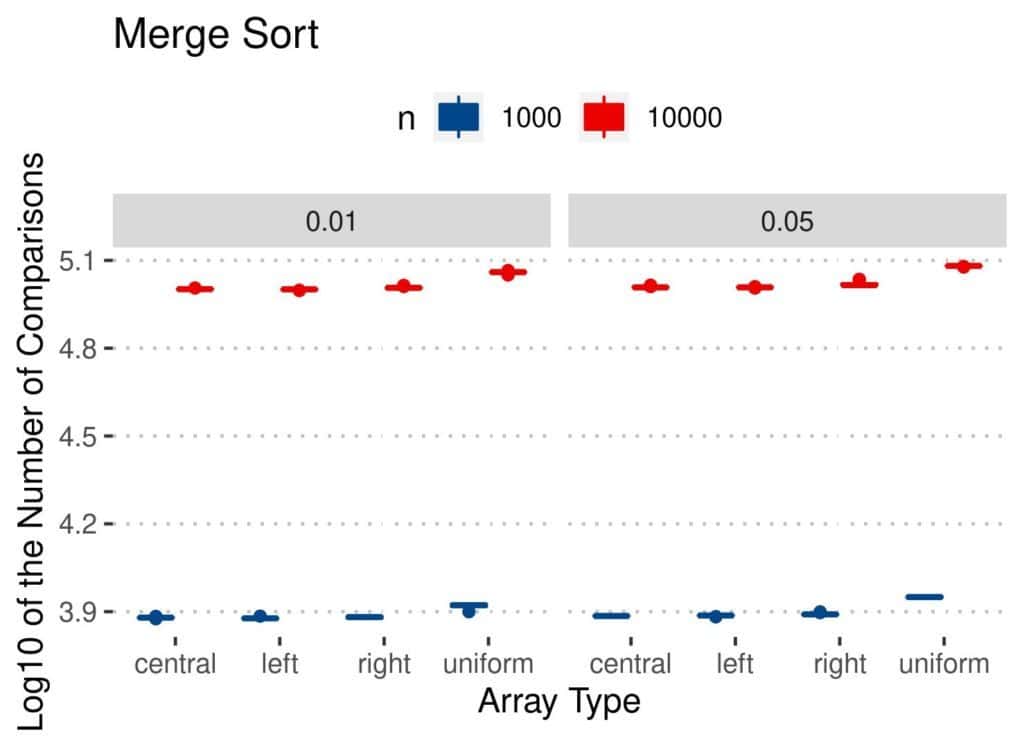
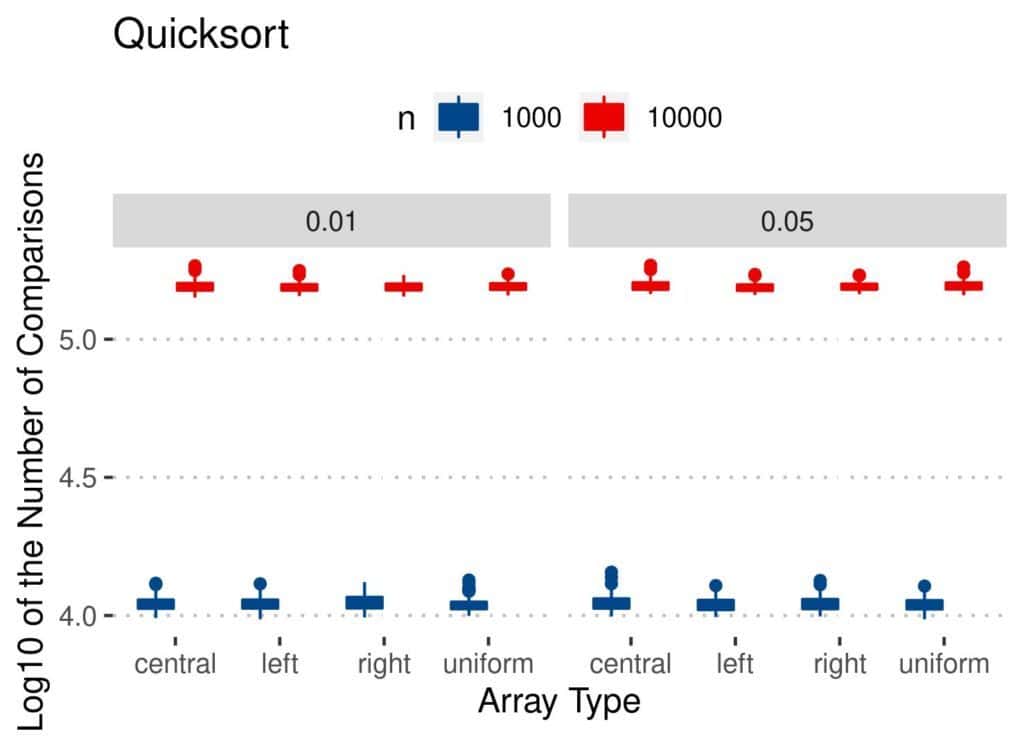
4.2 比较次数(Comparisons)
与交换次数类似:
- Insertion Sort 比较次数最少
- Merge 和 Quicksort 相对稳定
- Bubble 和 Insertion 在均匀扰动数组上表现较差
📊 结果图如下:
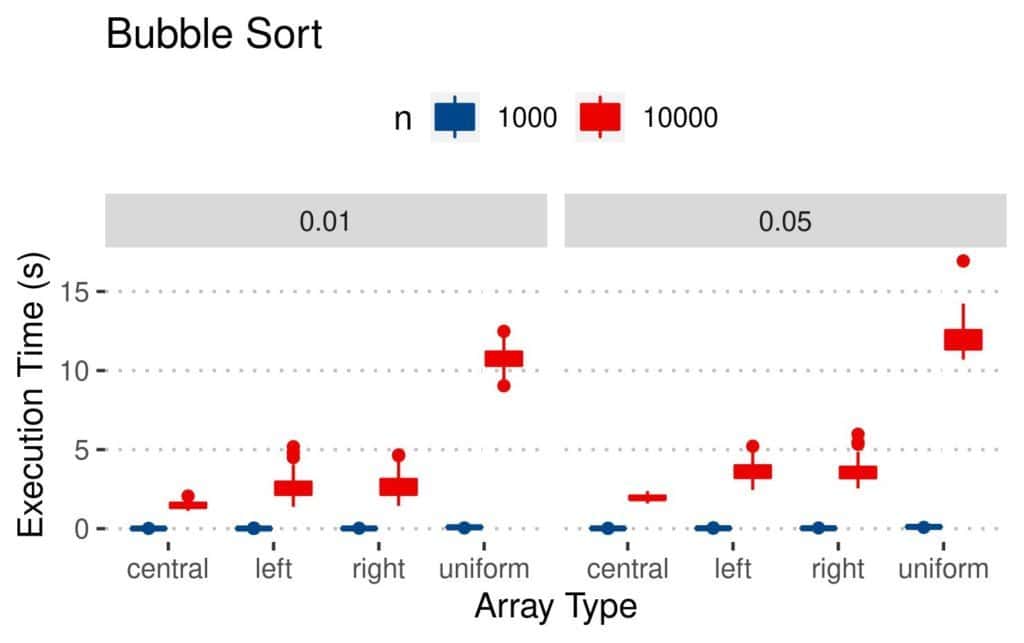
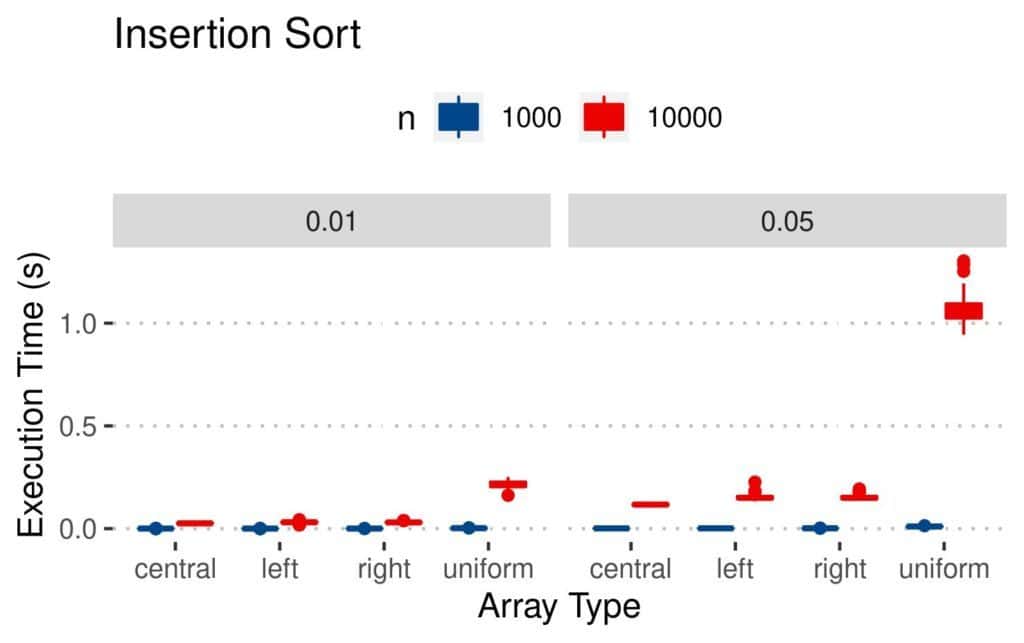
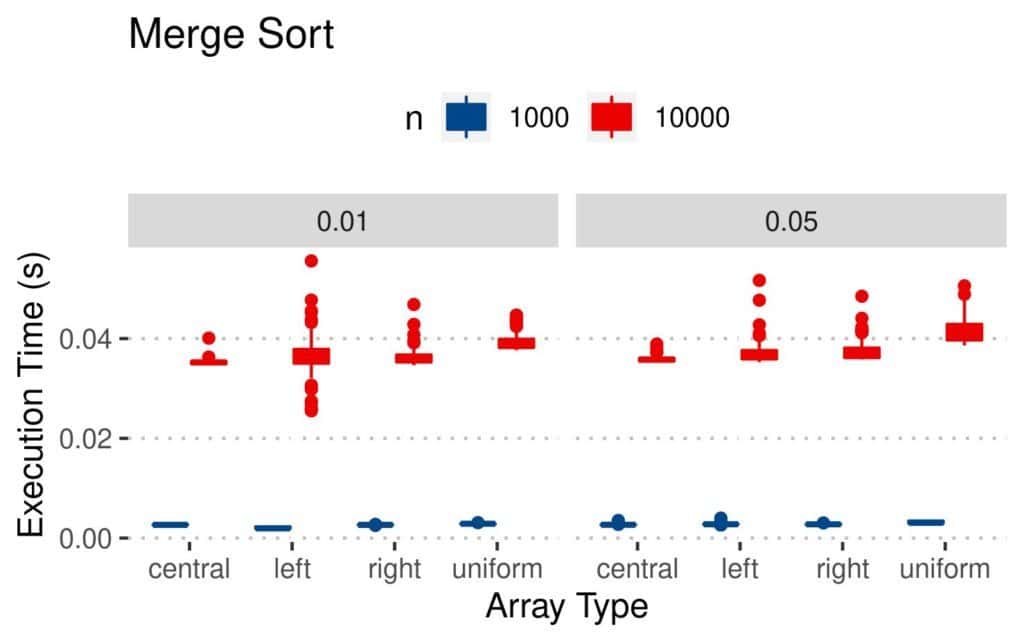
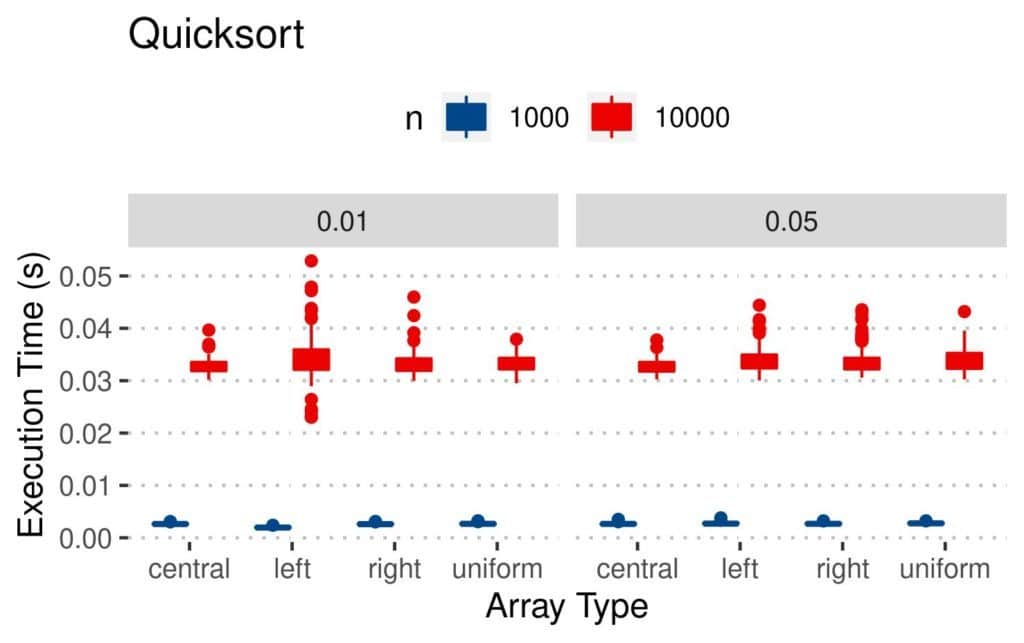
4.3 执行时间(Execution Time)
这是最直观的性能指标:
- Merge 和 Quicksort 执行最快
- Insertion 虽然比较和交换更少,但执行时间反而更长
- 均匀扰动数组最难处理
📊 结果图如下:
5. 结论
虽然 Insertion Sort 在比较和交换次数上表现最优,但实际执行速度最快的是 Quicksort 和 Merge Sort。
✅ 总结如下:
| 排序算法 | 比较次数 | 交换次数 | 执行速度 | 推荐使用场景 |
|---|---|---|---|---|
| Bubble Sort | ❌ 最多 | ❌ 最多 | ❌ 最慢 | 不推荐 |
| Insertion Sort | ✅ 最少 | ✅ 较少 | ❌ 较慢 | 小数组或教学 |
| Quicksort | ❌ 较多 | ❌ 较多 | ✅ 最快 | 通用排序 |
| Merge Sort | ❌ 较多 | ❌ 较多 | ✅ 快 | 稳定排序场景 |
⚠️ 注意:实验结果受环境影响,实际应用中应结合具体情况测试验证。
6. 延伸思考
- 如果你处理的是实时数据流中的排序问题,基本有序数组可能是一个常见场景
- 插入排序在 Java 的
Arrays.sort()中被用于排序小数组 - 如果你正在开发一个高频交易系统,基本有序数组的排序性能可能会影响整体响应时间
建议在实际项目中根据数据特征选择排序算法,而不是一味追求理论复杂度。理论是基础,但实践才是检验真理的唯一标准。