1. 引言
卷积神经网络(Convolutional Neural Network,CNN)是计算机视觉任务中广泛应用的一种神经网络结构。本文将介绍 CNN 的基本原理,并探讨如何根据具体任务设计合适的 CNN 架构。
尽管 CNN 的设计没有统一的标准,但有一些通用的设计原则和技巧可以帮助我们构建更高效、更准确的模型。我们将从简单任务入手,逐步扩展到复杂问题的解决方案,比如迁移学习与主流网络结构。
2. 神经网络概述
神经网络是受生物神经网络启发而设计的一类算法。其核心是神经元之间的连接结构。神经网络通常由多个层组成,每层包含若干神经元。
✅ 深度神经网络:至少包含一个隐藏层(非输入层或输出层)的神经网络被称为深度神经网络,这也是“深度学习”一词的由来。
常见的神经网络类型包括:
- 前馈神经网络(Feedforward Neural Network)
- 卷积神经网络(Convolutional Neural Network)
- 循环神经网络(Recurrent Neural Network)
本文将重点介绍卷积神经网络。
3. 卷积神经网络(CNN)
卷积神经网络是一种专门用于处理具有网格结构数据(如图像)的神经网络。它在图像识别、目标检测、特征提取等任务中表现出色,尤其适合处理高维数据如图像、视频等。
3.1. 卷积操作
卷积是 CNN 的核心操作,其数学表达如下:
(1) $$ g(x, y) = w * f(x, y) = \sum_{s = s_{min}}^{s_{max}} \sum_{t = t_{min}}^{t_{max}} w(s, t)f(x+s, y+t) $$
其中:
- $ f(x, y) $:输入图像
- $ w $:卷积核(filter 或 kernel)
卷积过程如下图所示:
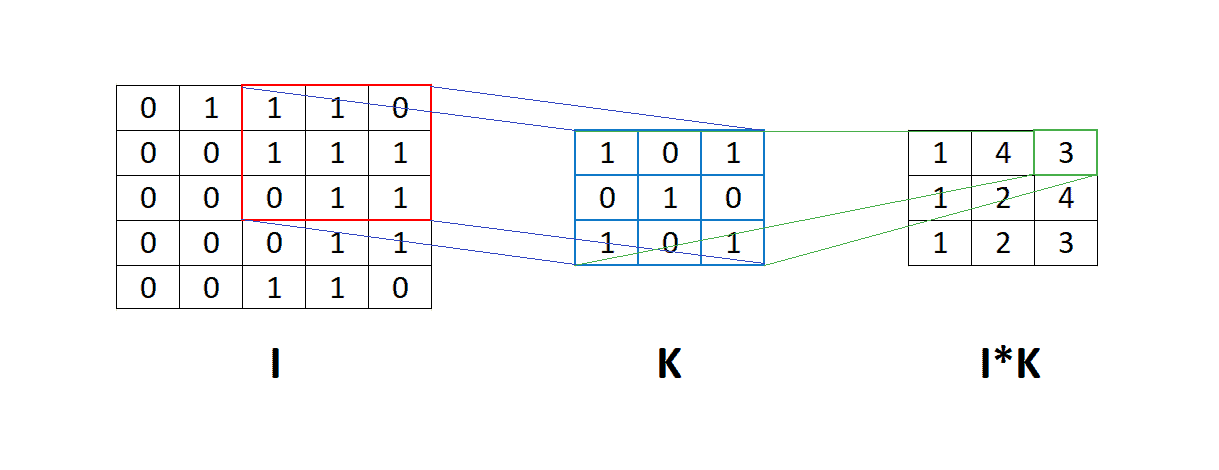
卷积核在输入矩阵上滑动,进行逐元素乘法并求和,得到输出特征图。
3.2. CNN 的优势
与全连接网络相比,CNN 的最大优势在于参数更少,从而减少了计算量和过拟合风险。
举个例子:
- 输入图像大小为 $32 \times 32$
- 使用 10 个 $3 \times 3$ 的卷积核
- 每个卷积核有 $3 \cdot 3 = 9$ 个参数 + 1 个偏置项
- 总参数数量为:$10 \cdot (9 + 1) = 100$
而全连接网络中,若同样输出维度为 $30 \times 30 \times 10$,则参数数量为:
(3) $$ 1024 \cdot 30 \cdot 30 \cdot 10 = 9,216,000 $$
因此,CNN 在参数效率方面具有巨大优势。
3.3. 典型 CNN 架构
一个简单的 CNN 架构通常包括以下组件:
- 卷积层(Convolutional Layer)
- 激活函数(ReLU)
- 池化层(Pooling Layer)
如下图所示:
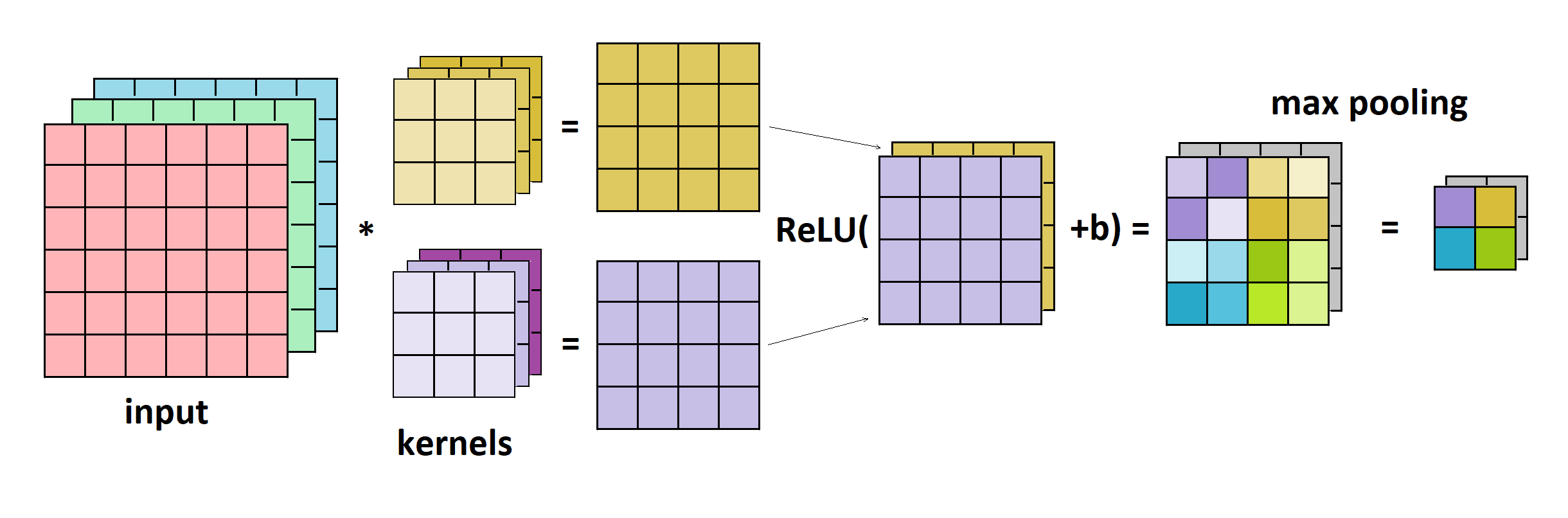
ReLU 用于引入非线性,池化层(如最大池化 Max Pooling)用于降维和提取局部特征。
4. CNN 设计原则
设计 CNN 没有固定公式,但可以根据任务复杂度采取不同策略。
4.1. 简单任务设计
对于简单任务(如 MNIST 手写数字识别),建议:
- 使用一个卷积层 + ReLU + Max Pooling
- 卷积核数量控制在 10 左右,尺寸为 $3 \times 3$
- 可逐步增加层数和卷积核数量,平衡准确率与训练速度
此外,还可以尝试不同的激活函数(如 Leaky ReLU、ELU)以及调整学习率、批量大小等超参数。
4.2. 复杂任务设计
对于复杂任务(如 ImageNet 分类),建议使用迁移学习(Transfer Learning)。
迁移学习的核心思想是复用已训练好的模型,根据新任务微调(fine-tune)模型参数。具体步骤如下:
- 加载预训练模型(如 VGG、ResNet)
- 替换最后一层全连接层
- 冻结部分层或微调整个模型
- 使用自己的数据集进行训练
迁移学习之所以有效,是因为预训练模型已经学习了大量通用特征,可以迁移到新任务中。
5. 主流 CNN 架构
以下是一些经典的 CNN 架构及其特点:
5.1. VGG16
- 发布于 2014 年 ImageNet 竞赛
- 包含 16 个带权重的层(13 个卷积层 + 3 个全连接层)
- 使用统一的 $3 \times 3$ 卷积核,结构简单但参数量大
5.2. InceptionNet(GoogleNet)
- 同样发布于 2014 年
- 引入 Inception 模块,融合多个卷积核($1 \times 1$, $3 \times 3$, $5 \times 5$)和池化操作
- 使用 $1 \times 1$ 卷积进行通道压缩,减少参数
Inception 模块示意图如下:
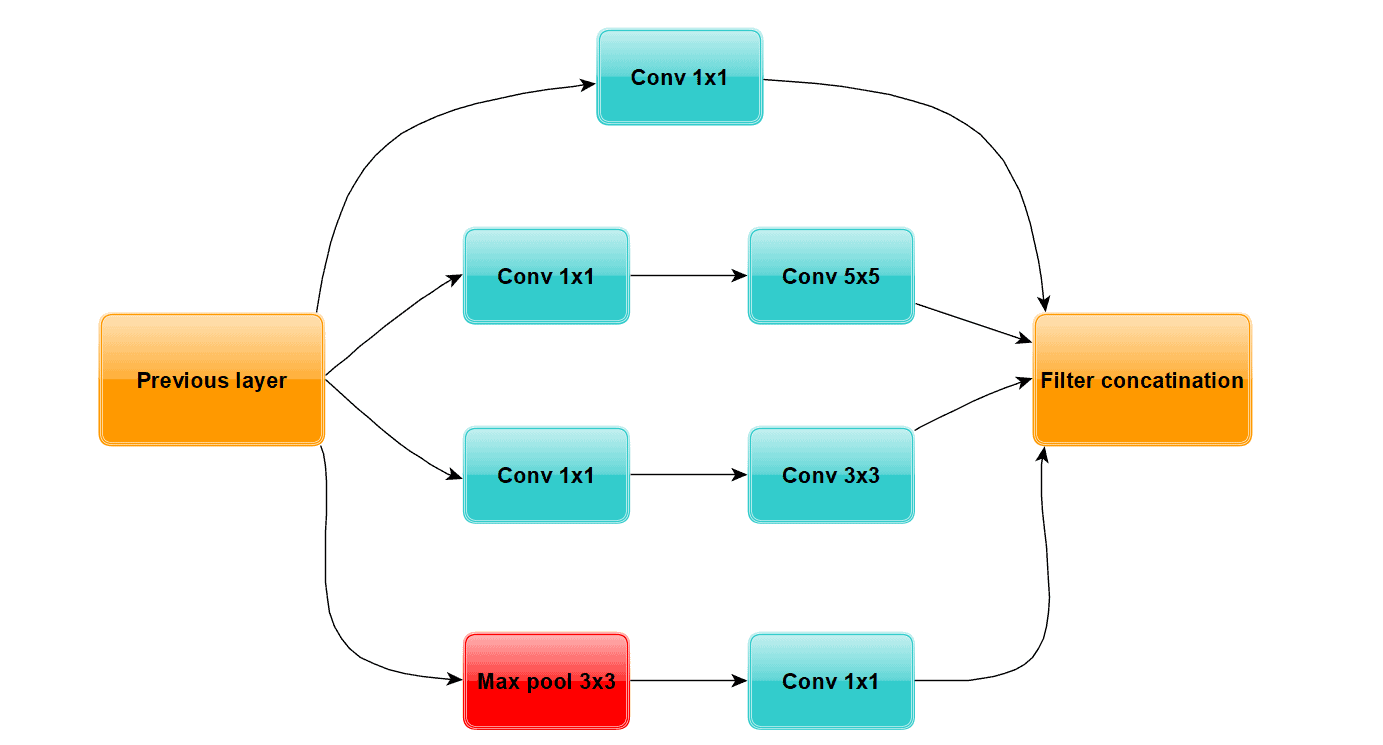
5.3. ResNet
- 2015 年 ImageNet 冠军
- 引入残差块(Residual Block),解决梯度消失问题
- 残差连接(Shortcut Connection)让信息直接跳过若干层传递
残差块结构如下:
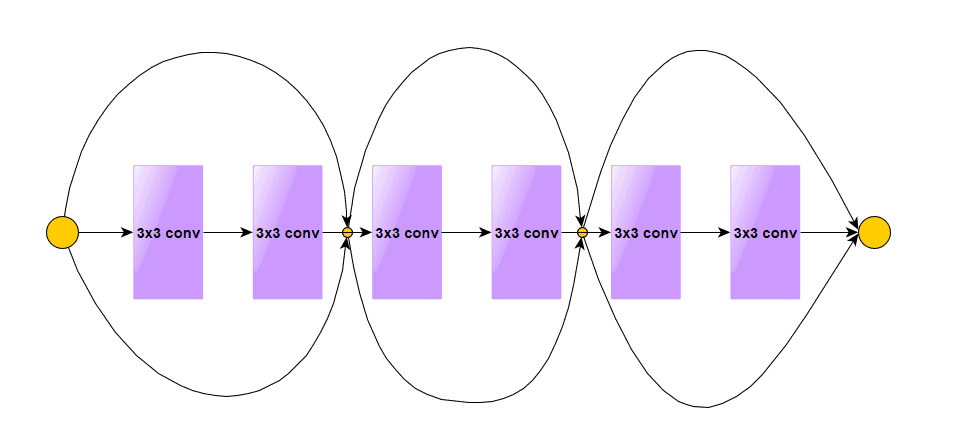
5.4. NFNets(Normalizer-Free Networks)
- DeepMind 于 2021 年推出
- 使用无 BatchNorm 的残差块,结合权重标准化和梯度裁剪
- 在 ImageNet 上达到 SOTA 级别
5.5. EfficientNets
- 由 Google 提出,包含从 EfficientNet-B0 到 B7 的多个版本
- 参数量从 5.3M 到 66M 不等
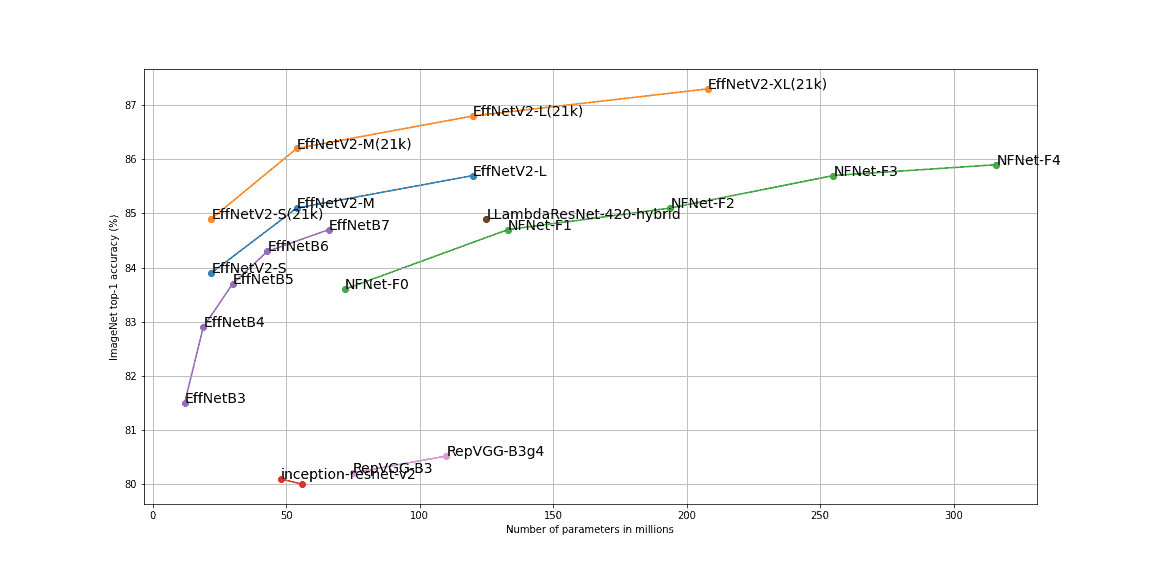
- EfficientNetV2 引入 Fused-MBConv 层,结合渐进式训练策略,性能优于 NFNet
EfficientNetV2 在 ImageNet 上的 Top-1 准确率如下图所示:
6. 总结
本文介绍了卷积神经网络的基本原理、设计思路以及主流架构。对于简单任务,可以从轻量级模型入手,逐步优化;对于复杂任务,推荐使用迁移学习和预训练模型。
CNN 的成功在于其高效的参数利用和对空间特征的提取能力。选择合适的架构、合理设计网络结构,是构建高性能视觉模型的关键。
✅ 提示:实际项目中建议优先尝试 ResNet、EfficientNet 等成熟模型,再根据需求微调或自定义设计。