1. Introduction
In this tutorial, we’ll discuss how to avoid single points of failure in distributed systems. We’ll start with a brief introduction to different types of failures that can occur in distributed systems. Then, we’ll explain a single point of failure and how to avoid it.
Finally, we’ll summarize the key points of the tutorial.
2. What Is a Single Point of Failure?
In distributed systems, a Single Point of Failure (SPOF) is such a component or part that, if it fails, causes the entire system to fail. Therefore, SPOFs represent a serious flaw in the system design.
An essential part of distributed systems is the communication subsystem enabling the components to communicate. A communication channel can also be a SPOF. If the communication channel fails, the components cannot communicate, and the system will fail:
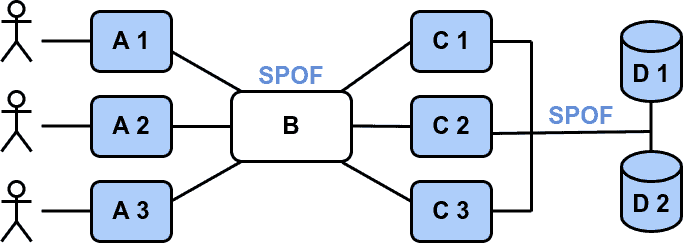
3. Identifying Single Points of Failures
Before we explain how to avoid SPOFs in distributed systems, let’s first discuss how to identify them. The most straightforward way is to go through the system’s architecture diagram component by component and check whether the component is an SPOF.
If a system is free of SPOFs, it doesn’t mean it cannot fail. We must also check how the system depends on other external systems or components. Imagine a distributed system that is SPOF-free, but it makes use of an external system by making a synchronous call to it. If the external system fails during the call, the entire system will halt during a certain time. Or, imagine if such a system has only one power supply.
Lastly, we must also consider that today’s distributed systems are often built on top of other systems. The system’s infrastructure may form an overlay network over a physical network, which may also have SPOFs. Running redundant components on the same physical or virtual machine is not good.
4. Avoiding Single Points of Failures by Redundancy
Now let’s discuss how to avoid SPOFs in distributed systems. The most straightforward way is to remove the SPOF by adding redundant components. If one component fails, the other one can take over. The more redundant components we have, the more resilient the system and the more costs and resources it requires.
Redundant components can be either active or passive. Active components are always running and can also help to distribute the load. Passive components are only used as a backup when the active component fails.
With this approach, there must be several mechanisms that handle the load distribution and failover:
- a load balancer that distributes the load among the active components
- a failure detector that detects when an active component fails
- a process that starts a passive component and makes it active by updating the load balancer and failure detector
The load distribution and failover mechanisms can be implemented within a load balancer. But there are two important points to consider:
- it adds extra complexity to the system
- the load balancer becomes a SPOF
We’ve only moved the SPOF from the component to the load balancer. To avoid this, the load balancer must also be redundant, in other words, distributed. Now we can see, that this process of removing SPOFs started a chain reaction. We must continue until all SPOFs within our distributed system are removed. This leads to a typical cloud architecture, where all components are redundant and distributed. It starts with the load balancer, continues with the caching and application servers, and ends with the persistent storage at the bottom of the stack or vice versa.
To be consistent, the measures applied above are still not sufficient. What if the entire data centre fails or becomes unreachable? Data centres usually have redundant power supplies and network connections, but if a part of the Internet backbone fails, the data centre may become unreachable. Cloud providers run several data centres in different geographical locations called “regions” or “availability zones”.
How does a client know which load balancer or data centre to use? The answer is the Domain Name System (DNS). The DNS is a hierarchical and distributed system without an SPOF, and it also allows the assignment of multiple IP addresses to a domain name. That means the client needs to know just the service’s domain name, and if one IP address becomes unreachable, it can try another one.
Let’s show how that works on an example with Netflix. We request the resolution of the DNS name www.netflix.com (using the host utility) and get the following information:
www.netflix.com is an alias for www.dradis.netflix.com. www.dradis.netflix.com is an alias for www.eu-west-1.internal.dradis.netflix.com. www.eu-west-1.internal.dradis.netflix.com is an alias for apiproxy-website-nlb-prod-3-ac110f6ae472b85a.elb.eu-west-1.amazonaws.com. apiproxy-website-nlb-prod-3-ac110f6ae472b85a.elb.eu-west-1.amazonaws.com has address 54.74.73.31 apiproxy-website-nlb-prod-3-ac110f6ae472b85a.elb.eu-west-1.amazonaws.com has address 54.155.178.5 apiproxy-website-nlb-prod-3-ac110f6ae472b85a.elb.eu-west-1.amazonaws.com has address 3.251.50.149 apiproxy-website-nlb-prod-3-ac110f6ae472b85a.elb.eu-west-1.amazonaws.com has IPv6 address 2a05:d018:76c:b684:8ab7:ac02:667b:e863 apiproxy-website-nlb-prod-3-ac110f6ae472b85a.elb.eu-west-1.amazonaws.com has IPv6 address 2a05:d018:76c:b683:a2cd:4240:8669:6d4 apiproxy-website-nlb-prod-3-ac110f6ae472b85a.elb.eu-west-1.amazonaws.com has IPv6 address 2a05:d018:76c:b685:e8ab:afd3:af51:3aed
As we can see, we’ve got three IPv4 and three IPv6 addresses. We can also see, that the services are hosted at Amazon Web Services (AWS) in the eu-west-1 geographical region, and the IP addresses belong to the Amazon Elastic Load Balancer (ELB). Each region at Amazon is divided into availability zones (AZs), each AZ being a separate data centre.
5. Stateless vs. Stateful Components
In this section, we’ll look deeper into the redundancy of components. A load balancer or a component serving some static content can be easily replicated. We just simply start new instances if needed, and we’re done. But components like databases that hold some state are more difficult to replicate. We must ensure that all replicas are in sync and that the state is consistent. Otherwise, we could lose data or get inconsistent results.
The stateless components, we can easily scale horizontally by using the recreate strategy. If a component fails, we just start a new instance – recreate it.
When a stateful component fails, we also start a new instance, but before making it active, we must provide it with the current state. Also, due to load balancing, we must synchronize all instances’ states (data replicas) in case of a write operation. For stateful components, a state synchronization mechanism must be provided to avoid data inconsistency.
Due to concurrent access, components can perform write operations in different orders. This makes replica synchronization a hard problem. It’s even harder in the context of failures and network latency. These problems can be solved with a distributed consensus algorithm, but never completely. This property of distributed systems is captured by the CAP theorem. It states that it’s impossible for a distributed system to simultaneously provide more than two out of the following three guarantees: consistency, availability, and network partition tolerance. So as a trade-off, several types of consistency models have been developed. Depending on the requirements of the distributed application, we choose the appropriate consistency model.
An interesting solution to consistency in distributed systems is the concept of Conflict-Free Replicated Data Types. These are used mainly in distributed caches like, for instance, the in-memory data grid Hazelcast.
6. Avoiding Single Points of Failures by Bulkheads and Resiliency
Avoiding SPOFs simply by making things redundant is not the final solution to the problem. SPOFs may not be apparent by just looking at the system’s architecture. They can also be a resource shared by the system’s components, that’s simply so basic that nobody ever thinks about it. For example, the memory of a computer. If there’s a component with a memory leak, it can consume most of the memory and cause other components of the system to fail. Moreover, it will probably also cause parts of other unrelated systems running on the same computer, to fail.
In general, we can say that a SPOF is also any shared resource (CPU, memory, persistent storage, service). This kind of SPOF is tricky in that:
- it may not be an explicit design flaw of a given system
- it may affect other unrelated systems running on the same computer
The solution to this problem is to prevent any component from exhausting the shared resource. This is usually addressed by creating so-called bulkheads. The basic idea of bulkheads is to isolate parts of a system from each other, to prevent a failure from spreading across the system. Bulkheads may be implemented in different ways. They can be implemented as rate limiters, circuit breakers, or containers like Docker.
This idea applies also to external services. They’re also shared resources, but outside of our control, and we cannot prevent them from failing. It is important to make a system resilient to failures of external services. There are several solutions to this problem:
- asynchronous calls – the caller doesn’t wait for the response and can meanwhile serve subsequent requests
- retries – the caller retries the request after a given time-out, where the number of retries is limited
- caching – the caller caches the response and serves subsequent requests from the cache
- fallback – if all previous solutions fail, the caller returns a default value
A nice thing is, that all these solutions are already implemented in the Resilience4j Java library and can be easily integrated into a distributed application.
7. Conclusion
To summarize, SPOFs are a severe flaw in the design of a distributed system. If a SPOF fails, the entire system fails. We avoid SPOF by adding redundant components, bulkheads, and resilience mechanisms if the system uses external services.
As we saw in Section 4, even components added to handle redundancy and failover can become SPOFs and must be redundant. This leads to a typical cloud architecture, where all components are redundant and distributed. Moreover, attention must be paid to stateful components. Unlike stateless components, they also require state synchronization.
In this article, we discussed what SPOFs in distributed systems are and how to avoid them. Today’s distributed systems are very complex and often referred to as massively distributed. This is mainly because the main goals are distributing the load and avoiding failures.
To conclude this tutorial, it doesn’t matter how advanced, sophisticated, or complex a system is. The truth is always, that “A chain is only as strong as its weakest link”.