1. 梯度下降简介
在本教程中,我们将深入探讨梯度下降(Gradient Descent,GD) 及其三种主要变体:随机梯度下降(Stochastic Gradient Descent,SGD)、标准梯度下降 和 小批量梯度下降(Mini Batch Gradient Descent)。
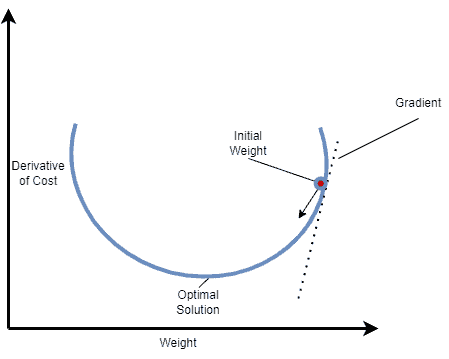
梯度下降是一种广泛使用的迭代优化算法,用于寻找任意可微函数的最小值。在机器学习中,我们通常用它来最小化损失函数,从而更好地拟合训练数据。每一步迭代中,我们根据当前点的梯度方向更新参数,朝着函数下降最快的方向前进。
2. 梯度下降(Gradient Descent)
✅ 核心思想:
每次迭代使用整个训练集来计算损失函数的梯度,并据此更新模型参数。
优点:
- 梯度估计无偏
- 每次更新方向稳定,标准误差小
- 理论上保证收敛到全局最小值(在凸函数中)
缺点:
- 每次迭代计算量大,训练慢
- 内存占用高
- 容易陷入局部最小值(在非凸问题中)
数学公式:
权重更新公式如下:
$$ w_{i+1} = w_i - \alpha \cdot \nabla_{w_i} J(w_i) $$
其中:
- $ w $:模型权重
- $ \alpha $:学习率(Learning Rate)
- $ J $:损失函数
- $ i $:迭代步数
可视化示意图:
3. 随机梯度下降(Stochastic Gradient Descent, SGD)
✅ 核心思想:
每次迭代只使用一个随机选择的训练样本进行梯度计算和参数更新。
优点:
- 计算效率高
- 可以跳出局部最小值
- 更适合大规模数据
缺点:
- 更新过程噪声大,收敛路径不稳定
- 收敛速度慢,容易震荡
- 易过拟合,泛化能力弱
数学公式:
$$ w_{i+1} = w_i - \alpha \cdot \nabla_{w_i} J(x^{(i)}, y^{(i)}; w_i) $$
其中:
- $ x^{(i)} $:第 $ i $ 个样本
- $ y^{(i)} $:对应的真实标签
4. 小批量梯度下降(Mini Batch Gradient Descent)
✅ 核心思想:
介于 GD 与 SGD 之间。每次迭代使用一个小批量(mini-batch)的样本计算梯度并更新参数。
优点:
- 平衡了计算效率与稳定性
- 收敛更快、更稳定
- 利用向量化计算,提升性能
缺点:
- 需要调参 mini-batch 大小
- 噪声仍高于标准 GD
数学公式:
$$ w_{i+1} = w_i - \alpha \cdot \nabla_{w_i} J(x^{i:i+b}, y^{i:i+b}; w_i) $$
其中:
- $ b $:mini-batch 的大小
5. 算法实现对比
我们以线性回归为例,展示三种方法在实现上的差异。
模型定义:
- 假设函数:$ h_\omega(x) = \omega_0 + \omega_1 x $
- 参数:$ \omega_0, \omega_1 $
- 损失函数:
$$ J(\omega_0, \omega_1) = \frac{1}{2m} \sum_{i=1}^m (h_\omega(x^{(i)}) - y^{(i)})^2 $$
目标:最小化 $ J(\omega_0, \omega_1) $
伪代码对比:
✅ 5.1 梯度下降伪代码:
Repeat until convergence {
Compute gradients using all m samples
Update weights
}
✅ 5.2 随机梯度下降伪代码:
Shuffle dataset
Repeat until convergence {
For each sample (x_i, y_i) {
Compute gradient
Update weights
}
}
✅ 5.3 小批量梯度下降伪代码:
Shuffle dataset
Split into batches of size b
Repeat until convergence {
For each batch (X_b, Y_b) {
Compute gradient
Update weights
}
}
6. 实际应用场景
这些梯度下降变体广泛应用于机器学习和神经网络中,尤其是在反向传播(Backpropagation)过程中用于训练模型参数。它们通过不断调整模型权重,使损失函数逐步下降,最终达到一个局部或全局最小值。
7. 三种方法对比总结
| 方法 | 优点 | 缺点 |
|---|---|---|
| GD | 无偏估计、稳定 | 计算开销大、收敛慢 |
| SGD | 快速、适合大数据 | 噪声大、收敛不稳定 |
| Mini-Batch GD | 折中方案、效率与稳定性兼顾 | 需调参 mini-batch size |
✅ 推荐使用: 小批量梯度下降是目前深度学习中最常用的优化策略。
8. 总结
本文系统地介绍了梯度下降及其主要变体:标准 GD、SGD 和 Mini-Batch GD。我们分析了它们的工作原理、数学公式、实现伪代码以及优缺点。最后得出结论:
Mini-Batch Gradient Descent 在性能、效率和稳定性之间取得了最佳平衡,因此在实际应用中最受青睐。
掌握这三种方法的区别和适用场景,有助于我们在训练模型时做出更合理的优化选择。