1. 简介
在本教程中,我们将详细讲解神经网络反向传播过程中权重和偏置是如何更新的。首先简要介绍神经网络、前向传播与反向传播的基本概念,接着从数学角度深入解析权重和偏置的更新机制。
本教程的目标是帮助读者理解偏置在神经网络中的更新方式,并与权重更新进行对比。
2. 神经网络概述
神经网络是一种模拟生物神经系统的算法结构。其核心理念是构建一个具有类人脑行为的人工系统。根据网络结构不同,神经网络主要分为三类:
- 全连接神经网络(常规神经网络)
- 卷积神经网络(CNN)
- 循环神经网络(RNN)
它们之间的主要区别在于神经元的类型以及信息在网络中的流动方式。本文将以全连接神经网络为例说明反向传播过程。
3. 人工神经元
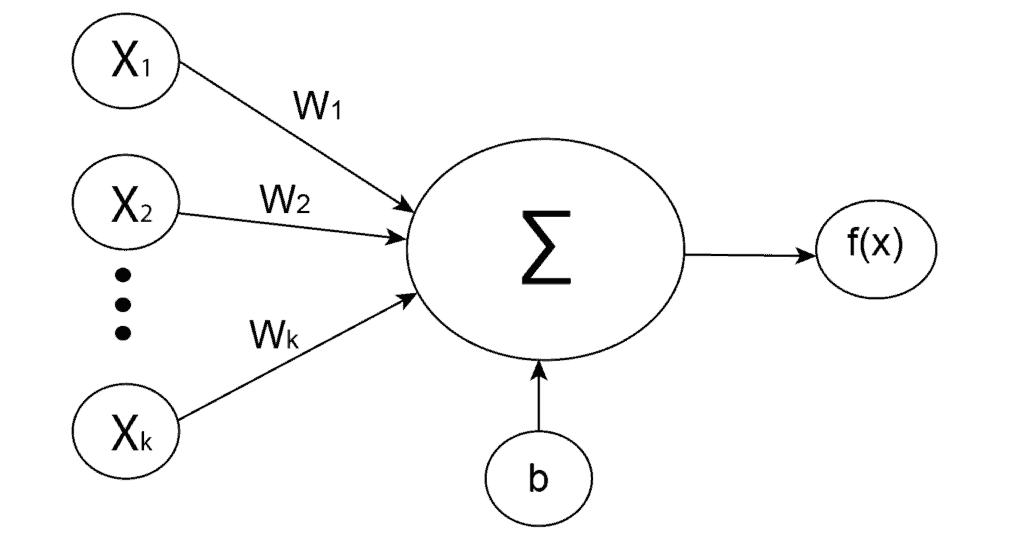
人工神经元是所有神经网络的基础单元,模仿生物神经元结构。每个神经元接收多个输入信号,经过加权求和、加上偏置后,再通过激活函数处理,输出结果传递给下一层神经元。
数学上,神经元的输入加权和表示为:
(1) $$ z = w_{1}x_{1} + w_{2}x_{2} + \cdots + w_{k}x_{k} + b $$
其中:
- $ w_i $ 是连接权重
- $ x_i $ 是输入
- $ b $ 是偏置
最终输出由激活函数 $ f $ 处理:
$$ a = f(z) $$
如下图所示为一个典型的人工神经元结构:
4. 前向传播与反向传播
神经网络的训练过程主要分为两个阶段:
- 前向传播(Forward Propagation)
- 反向传播(Backpropagation)
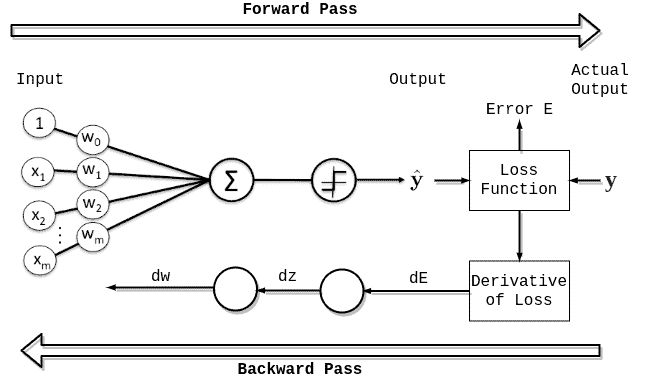
4.1 前向传播
前向传播是指输入数据在网络中从前向后依次传递,经过每一层神经元的处理,最终计算出预测值和误差。这是全连接网络的标准流程,对于RNN等结构略有不同。
✅ 总结:前向传播从输入开始,到误差计算结束。
4.2 反向传播
反向传播是训练神经网络的关键环节。其核心思想是根据前向传播计算出的误差,反向调整网络中的权重和偏置,以降低误差并提升模型的泛化能力。
初始状态下,网络的预测结果不准确。反向传播的目的就是通过不断迭代,逐步提升网络精度并降低误差。
常见的优化方法包括:
- 随机梯度下降(SGD)
- RMSProp
- Adam
这些方法都基于梯度下降算法,通过迭代调整权重和偏置,使损失函数最小化。为此,我们需要计算损失函数对权重和偏置的梯度,然后使用以下公式进行更新:
$$ \text{参数} = \text{参数} - \alpha \cdot \text{梯度} $$
其中 $ \alpha $ 是学习率。
反向传播流程如下图所示:
4.3 权重更新
考虑如下神经网络片段,其中 $ l $ 表示第 $ l $ 层,$ a $ 是激活值,$ W $ 是权重矩阵:
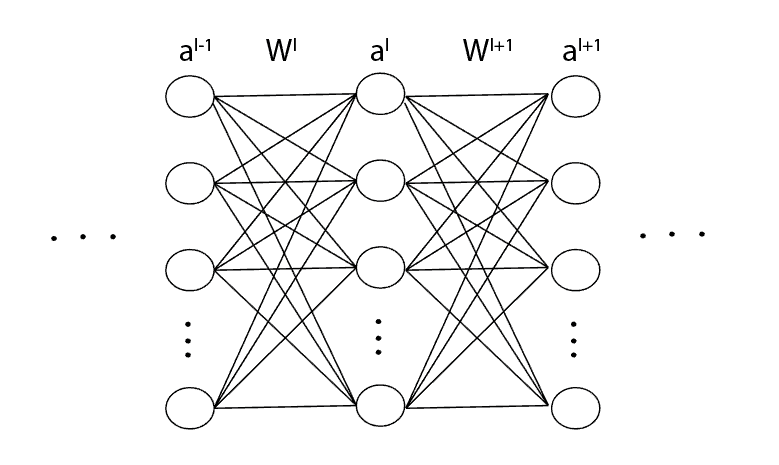
第 $ l $ 层第 $ k $ 个神经元的输出为:
(2)
$$
a_k^l = \sigma(z_k^l), \quad z_k^l = w_{k1}^l a_1^{l-1} + w_{k2}^l a_2^{l-1} + \cdots + w_{kn}^l a_n^{l-1} + b_k^l
$$
若要更新权重 $ w_{kj}^l $,我们需要计算损失函数 $ C $ 对该权重的偏导数:
(3)
$$
\frac{\partial C}{\partial w_{kj}^l}
$$
使用链式法则展开为:
(4)
$$
\frac{\partial C}{\partial w_{kj}^l} = \frac{\partial C}{\partial z_k^l} \cdot \frac{\partial z_k^l}{\partial w_{kj}^l} = \frac{\partial C}{\partial a_k^l} \cdot \frac{\partial a_k^l}{\partial z_k^l} \cdot \frac{\partial z_k^l}{\partial w_{kj}^l}
$$
进一步展开为:
(5)
$$
\frac{\partial C}{\partial w_{kj}^l} = \left( \sum_m \frac{\partial C}{\partial z_m^{l+1}} \cdot w_{mk}^{l+1} \right) \cdot \sigma'(z_k^l) \cdot a_j^{l-1}
$$
4.4 误差信号
定义第 $ l $ 层第 $ k $ 个神经元的误差信号为:
(6)
$$
\delta_k^l = \frac{\partial C}{\partial z_k^l}
$$
由此可得递归公式:
(7)
$$
\delta_k^l = \left( \sum_m \delta_m^{l+1} w_{mk}^{l+1} \right) \cdot \sigma'(z_k^l)
$$
对于最后一层 $ L $,误差信号为:
(9)
$$
\delta_k^L = \frac{\partial C}{\partial a_k^L} \cdot \sigma'(z_k^L)
$$
将误差信号代入原式,得到:
(10)
$$
\frac{\partial C}{\partial w_{kj}^l} = \delta_k^l \cdot a_j^{l-1}
$$
最终权重更新公式为:
(11)
$$
w_{kj}^l = w_{kj}^l - \alpha \cdot \delta_k^l \cdot a_j^{l-1}
$$
4.5 偏置更新
偏置的更新方式与权重类似。根据导数规则:
(12)
$$
\frac{\partial (x + a)}{\partial x} = 1
$$
对第 $ l $ 层第 $ k $ 个偏置项 $ b_k^l $,有:
(14)
$$
\frac{\partial C}{\partial b_k^l} = \frac{\partial C}{\partial z_k^l} \cdot \frac{\partial z_k^l}{\partial b_k^l} = \delta_k^l
$$
因此偏置更新公式为:
(15)
$$
b_k^l = b_k^l - \alpha \cdot \delta_k^l
$$
⚠️ 注意:偏置更新中没有输入项 $ a_j^{l-1} $,因此其更新方式比权重更简单。
5. 总结
本文从神经网络的基本结构出发,详细讲解了前向传播与反向传播的原理,并从数学角度推导了权重与偏置的更新公式。
- ✅ 权重更新依赖误差信号与上一层激活值的乘积
- ✅ 偏置更新仅依赖误差信号本身
理解这两个更新机制的区别,对于掌握神经网络训练过程至关重要。本文偏理论和数学推导,适合已有微积分和机器学习基础的读者阅读。