1. 简介
Graph Attention Networks(GATs)是一种专为图结构数据设计的神经网络架构。在社交网络、生物网络和推荐系统等实际应用中,我们经常需要处理图结构数据。GAT 的核心优势在于其注意力机制,它能动态评估图中节点之间连接的重要性,从而更有效地处理大规模和复杂图结构。
2. 图上的机器学习
图结构广泛存在于现实世界的多个领域中。图由节点(nodes)和边(edges)组成,节点代表实体,边表示实体之间的关系。
2.1 图上的常见任务
- 节点分类(Node Classification):预测图中每个节点的类别。例如,在社交网络中根据人际关系预测用户的政党倾向。
- 链接预测(Link Prediction):预测未来可能连接的节点。例如,在推荐系统中基于用户购买历史推荐新商品。
- 图分类(Graph Classification):对整个图进行分类。例如,根据分子结构预测其化学类别。
- 社区检测(Community Detection):识别图中紧密相连的节点群组。例如,在社交网络中发现兴趣相似的用户群体。
2.2 传统方法的局限性
传统机器学习方法如线性回归和支持向量机(SVM)处理的是固定长度的向量数据。它们依赖于向量之间的运算(如点积、欧几里得距离),但图结构的数据无法直接映射为向量。
图结构的复杂性体现在:
- 节点和边数量不固定
- 节点间关系复杂且非线性
- 包含多种属性(节点属性、边属性、全局属性)
因此,研究人员开发了专门处理图数据的模型,如图神经网络(GNNs)。
3. 图神经网络(GNNs)
GNNs 通过消息传递机制更新图中节点的表示。每一层 GNN 从上一层接收图的表示,并通过聚合邻居节点的信息来更新当前节点的特征。每一层的“感受野”增加一个跳数(hop):
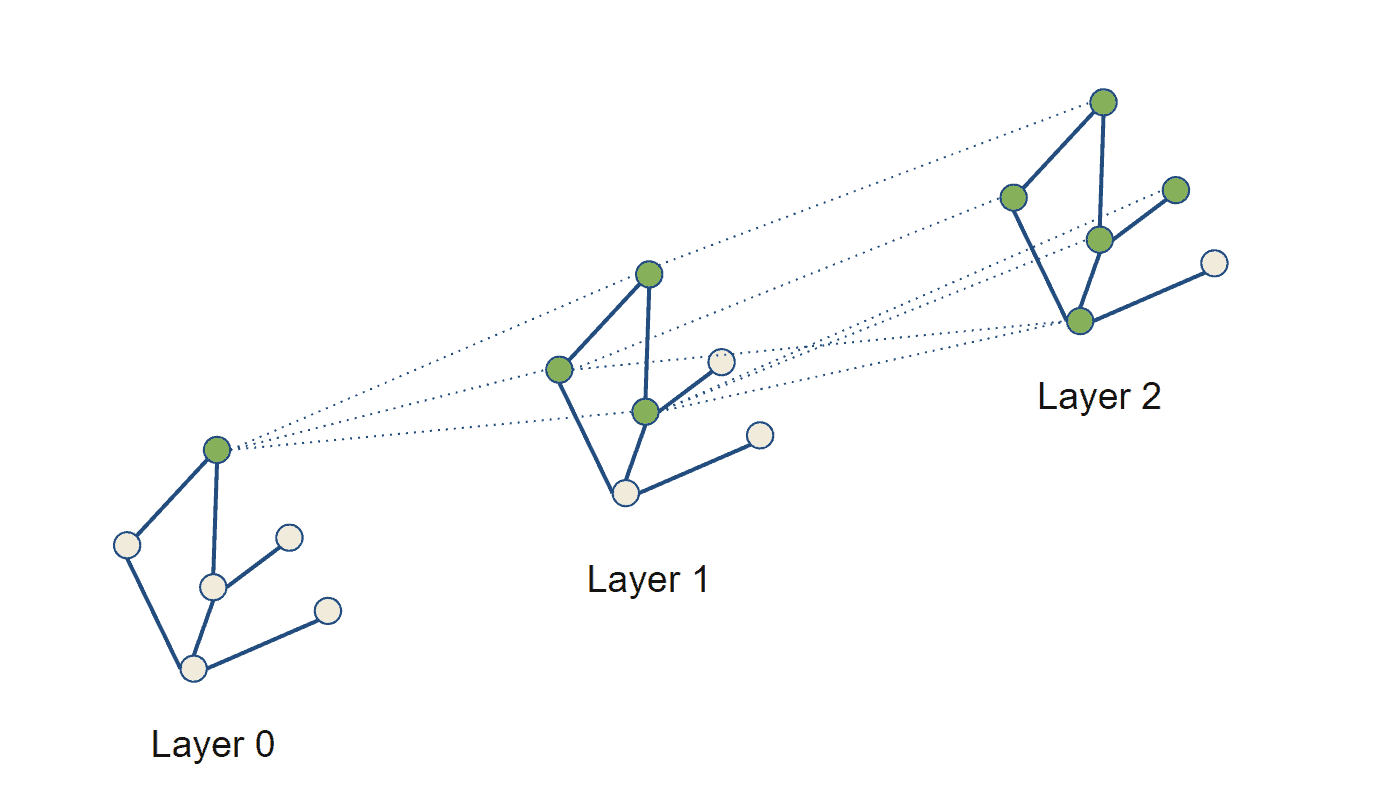
设图  ,其中
,其中  为节点集合,
为节点集合, 为边集合。设
为边集合。设  为节点
为节点  的邻居,
的邻居, 为节点特征,
为节点特征, 为边特征。
为边特征。
消息传递的一般形式为:
![[{\displaystyle \mathbf {h} _{u}=\phi \left(\mathbf {x_{u}},\bigoplus _{v\in N_{u}}\psi (\mathbf {x} _{u},\mathbf {x} _{v},\mathbf {e} _{uv})\right)}]](/wp-content/ql-cache/quicklatex.com-536826f822e71fd8db7ab9ef18b1723c_l3.svg)
其中:
 为更新函数
为更新函数 为消息函数
为消息函数 为置换不变的聚合函数(如 sum、mean、max)
为置换不变的聚合函数(如 sum、mean、max)
置换不变性意味着无论输入顺序如何,输出结果不变,这对图结构来说至关重要。
4. GAT 的工作原理
4.1 为什么需要注意力机制?
注意力机制让模型关注更相关的信息,忽略不相关的内容,从而提升预测准确性。
在 GAT 中,注意力机制用于动态评估图中节点连接的重要性。相比传统图卷积网络(GCNs)使用固定权重,GAT 可以根据任务和图结构自适应地调整连接权重。
4.2 概述
GAT 由多个注意力层组成,每层包含多个并行运行的注意力头(attention heads)。每个注意力头计算图中节点的注意力系数(attention coefficients),这些系数表示节点连接的重要性。
具体流程如下:
- 输入节点特征和图邻接矩阵
- 计算注意力系数
- 使用系数加权邻居特征
- 合并加权特征并进行变换
- 输出作为下一层输入
核心机制是自注意力(self-attention),它允许每个节点关注图中其他所有节点,同时考虑图的连接结构。
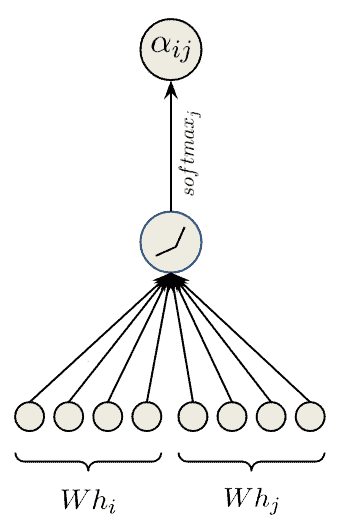
4.3 数学原理
设  为节点
为节点  的输入特征,
的输入特征, 为可学习权重矩阵。自注意力机制计算注意力系数
为可学习权重矩阵。自注意力机制计算注意力系数  :
:
![[\alpha_{ij} = \frac{\exp\left(\text{LeakyReLU}\left(W^T \cdot \left[h_i \Vert h_j\right]\right)\right)}{\sum_{k=1}^{n} \exp\left(\text{LeakyReLU}\left(W^T \cdot \left[h_i \Vert h_j\right]\right)\right)}]](/wp-content/ql-cache/quicklatex.com-7eb4be4427cfa0b456a902808d156217_l3.svg)
其中:
 为拼接操作
为拼接操作- LeakyReLU 是激活函数
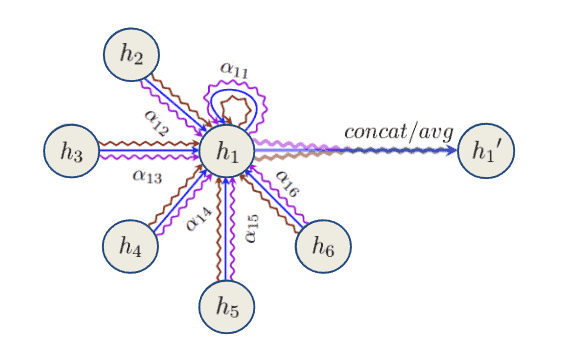
计算完注意力系数后,用于加权邻居节点特征,再进行合并和变换:
![[\displaystyle \mathbf {h} _{u}={\overset {K}{\underset {k=1}{\Big \Vert }}}\sigma \left(\sum _{v\in N_{u}}\alpha _{uv}\mathbf {W} ^{k}\mathbf {x} _{v}\right)]](/wp-content/ql-cache/quicklatex.com-99f0a0e8d37236d41b27ed3c0ed998ca_l3.svg)
最终层中,不再拼接而是对注意力头输出取平均:
![[\displaystyle \mathbf {h} _{u}=\sigma \left({\frac {1}{K}}\sum _{k=1}^{K}\sum _{v\in N_{u}}\alpha _{uv}\mathbf {W} ^{k}\mathbf {x} _{v}\right)]](/wp-content/ql-cache/quicklatex.com-7d11cee2ae8dd9ec641c7a41ad28aa18_l3.svg)
4.4 计算复杂度
**GAT 的注意力机制复杂度为  **,其中:
**,其中:
 为节点数
为节点数 为节点嵌入维度
为节点嵌入维度
每个节点需对其所有邻居进行线性变换,共进行  次,每次复杂度为
次,每次复杂度为  ,总复杂度为:
,总复杂度为:

此外,多头注意力机制会进一步放大复杂度,需根据实际需求权衡性能与效率。
5. 优缺点总结
✅ 优点:
- 注意力机制让模型聚焦关键节点和边
- 在节点分类、图分类等任务上有更好表现
❌ 缺点:
- 计算开销大,尤其在大图上
- 注意力机制解释性较差
- 对超参数敏感(如注意力头数量、隐藏层数)
- 在节点或边较少的图上表现不佳
6. 总结
本文介绍了图结构数据的常见任务、GNN 的基本原理以及 GAT 的核心机制 —— 注意力机制。
传统机器学习处理固定长度向量,而 GAT 可处理变长图结构数据,通过注意力机制动态评估节点连接重要性,从而提升模型性能。尽管 GAT 在许多任务中表现出色,但其计算复杂度较高,需根据实际场景进行优化和调整。