1. 概述
本文讨论如何统计图中两个节点之间的最短路径数量。首先我们会明确问题定义,并通过一个示例说明。随后,我们将分别介绍针对无权图和有权图的两种解决方案。
2. 问题定义
给定一个包含  个节点的图
个节点的图  ,以及
,以及  条边。我们有两个整数
条边。我们有两个整数  和
和  ,分别表示起点和终点。
,分别表示起点和终点。
目标是统计从 到 的所有最短路径的数量。
⚠️ 注意:最短路径是指在所有可能路径中长度最小的那条路径。
来看一个例子:
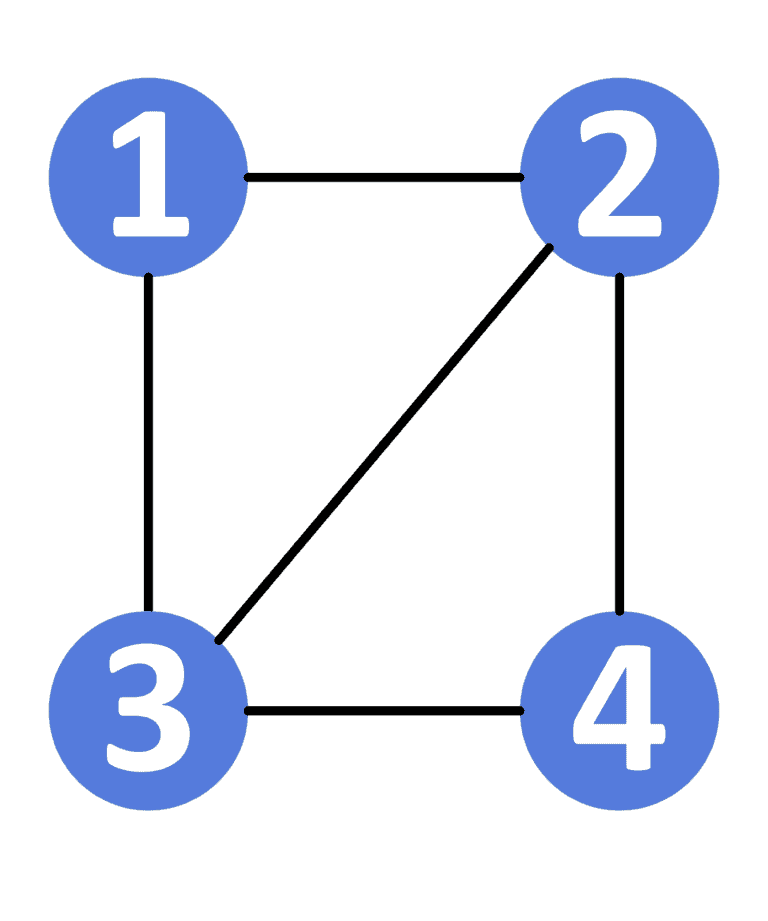
从节点 1 到节点 4 有 4 条路径:
1 → 2 → 4(长度为 2)1 → 2 → 3 → 4(长度为 3)1 → 3 → 4(长度为 2)1 → 3 → 2 → 4(长度为 3)
最短路径长度是 2,有两条这样的路径,所以答案是 2。
3. 无权图处理
3.1. 思路解析
使用 BFS(广度优先搜索) 来统计从起点到每个节点的最短路径数量。我们维护两个数组:
distance[u]:表示从起点到节点u的最短路径长度。paths[u]:表示从起点到节点u的最短路径数量。
初始化:
distance全部为INF,起点为0。paths全部为0,起点为1。
BFS过程中,对每个子节点:
- 如果
distance[child] > distance[current] + 1:说明找到更短路径,更新距离和路径数。 - 如果
distance[child] == distance[current] + 1:说明找到等长路径,累加路径数。
3.2. Java 实现
int countShortestPathsUnweighted(int V, List<List<Integer>> adj, int S, int D) {
int[] distance = new int[V + 1];
int[] paths = new int[V + 1];
Arrays.fill(distance, Integer.MAX_VALUE);
Queue<Integer> queue = new LinkedList<>();
distance[S] = 0;
paths[S] = 1;
queue.add(S);
while (!queue.isEmpty()) {
int current = queue.poll();
for (int child : adj.get(current)) {
if (distance[child] > distance[current] + 1) {
distance[child] = distance[current] + 1;
paths[child] = paths[current];
queue.add(child);
} else if (distance[child] == distance[current] + 1) {
paths[child] = (paths[child] + paths[current]);
}
}
}
return paths[D];
}
✅ 时间复杂度:O(V + E)
⚠️ 注意:此算法不能用于有权图,因为 BFS 无法处理边权不一致的情况。
4. 有权图处理
4.1. 思路解析
对于有权图,我们需要使用 Dijkstra 算法。它通过优先队列(最小堆)来保证每次取出的节点是当前距离最小的节点。
我们同样维护:
distance[u]:当前最短距离paths[u]:对应最短路径数量
每次从优先队列取出当前节点后,遍历其邻接边:
- 如果发现更短路径:更新距离,重置路径数。
- 如果是等长路径:累加路径数。
4.2. Java 实现
class Edge {
int node, cost;
Edge(int node, int cost) {
this.node = node;
this.cost = cost;
}
}
int countShortestPathsWeighted(int V, List<List<Edge>> adj, int S, int D) {
int[] distance = new int[V + 1];
int[] paths = new int[V + 1];
Arrays.fill(distance, Integer.MAX_VALUE);
PriorityQueue<Edge> pq = new PriorityQueue<>((a, b) -> a.cost - b.cost);
distance[S] = 0;
paths[S] = 1;
pq.add(new Edge(S, 0));
while (!pq.isEmpty()) {
Edge e = pq.poll();
int current = e.node;
int currDist = e.cost;
if (currDist > distance[current]) continue;
for (Edge edge : adj.get(current)) {
int node = edge.node;
int cost = edge.cost;
int newDist = currDist + cost;
if (newDist < distance[node]) {
distance[node] = newDist;
paths[node] = paths[current];
pq.add(new Edge(node, newDist));
} else if (newDist == distance[node]) {
paths[node] = (paths[node] + paths[current]);
}
}
}
return paths[D];
}
✅ 时间复杂度:O(E + V log V)
⚠️ 注意:路径数可能会很大,建议使用 mod 取模或 BigInteger。
5. 总结
| 图类型 | 算法 | 时间复杂度 | 关键点 |
|---|---|---|---|
| 无权图 | BFS | O(V + E) | 每层扩展时判断是否为更短路径 |
| 有权图 | Dijkstra | O(E + V log V) | 使用优先队列保证每次取最短路径节点 |
✅ 技术要点回顾
- BFS 适用于无权图,Dijkstra 适用于有权图。
- 每个节点维护两个值:
distance和paths。 - 更新路径数时注意两种情况:
- 找到更短路径:直接赋值
- 找到等长路径:累加
⚠️ 踩坑提醒
- 不要混用 BFS 和有权图,会导致错误。
- 路径数可能溢出,建议使用
mod或BigInteger。 - Dijkstra 中优先队列可能包含旧节点,需跳过已处理节点。